
맨당에 헤엄치는게 뭔지를 보여주겠다. - 개요
우리 프로젝트가 시작하고 초창기에는 집계 api 호출시 크롤링 된 데이터를 mysql에서 조인을 해서 집계하는 시간이 40초나 걸렸습니다.😂 이로 인해 서비스 속도와 사용자 만족도에 불편함이 될것이라고 생각습니다. 물론, RDS 인스턴스의 성능을 향상시키는 방법도 고려되었지만, 더 근본적인 해결책을 찾기 위해 데이터 구조와 처리 방식을 최적화하고 다양한 기술 스택을 검토하게 되었습니다.
오십보백보
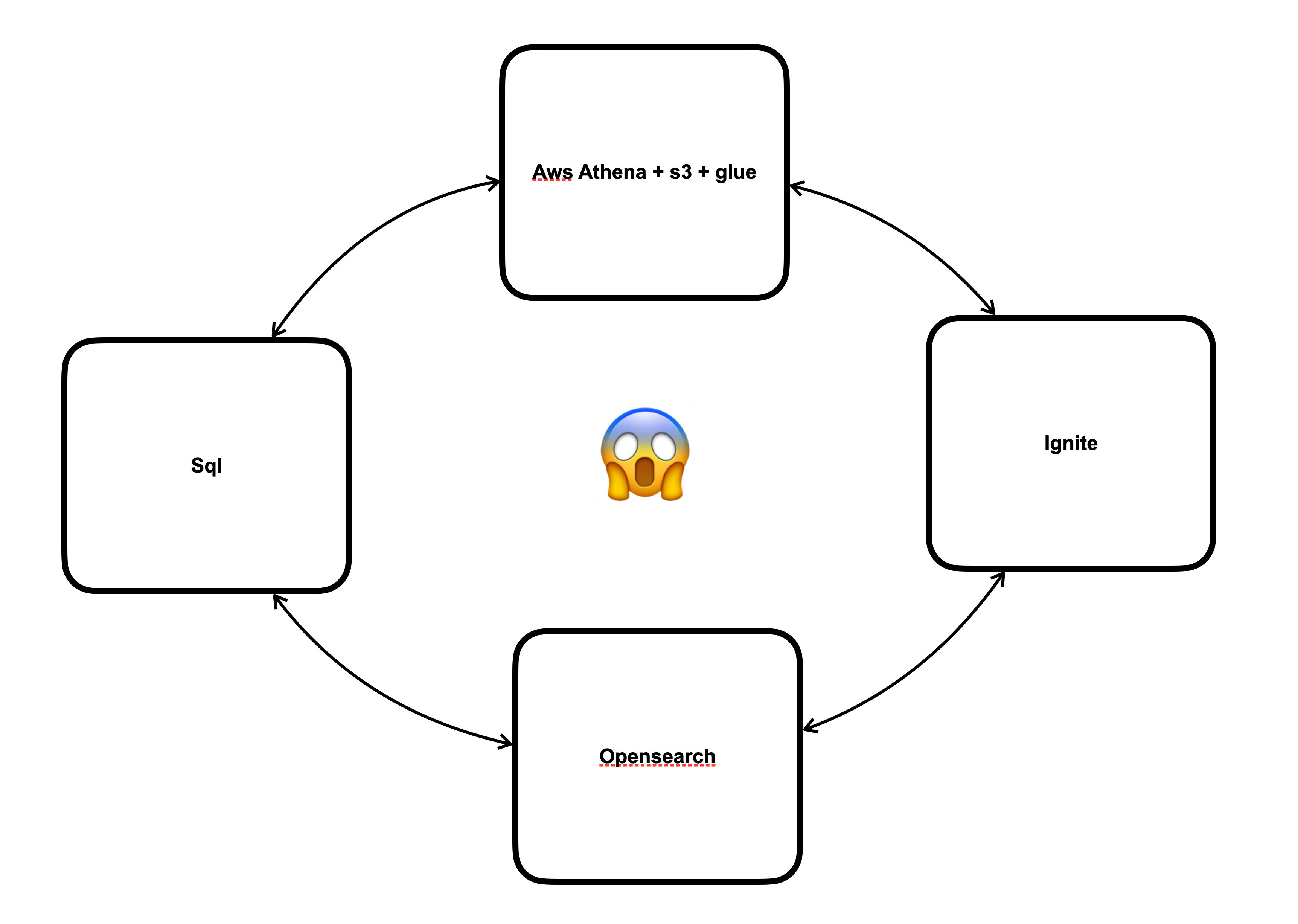
 다이어그램 만 봐도 초보티 팍팍
다이어그램 만 봐도 초보티 팍팍
검색을 통해도 만족스러운 해결책을 찾지 못하자, 우리는 도움이 필요하다고 느꼈습니다. 그래서 AWS의 기술 자문을 받기로 결정했습니다. 우리 상황에서는 데이터 ETL 과정에 S3, Athena, Glue를 활용하고, 백엔드 단에서는 OpenSearch를 사용하여 시스템을 구성하는 것이 최선의 선택임을 알게 되었습니다. 그리고 덤으로 kiness firehose까지.... 공부할게 많구나? 🥲
그래서 우리는 실행에 옮겼고 마이그레이션부터 파이프라인 구축까지 꽤 많은 시간과 노력이 들었습니다.
Ref
mysql에서 s3로 데이터 마이그레이션
https://velog.io/@bgly/MySQLS3%EB%8D%B0%EC%9D%B4%ED%84%B0-%EC%9D%B4%EC%A0%84
이 포스팅의 저자는 같은 팀에 계셨던 DE분인데 자기일에 열정적이고 프라이드가 정말 강하신 분이에요. 인싸들 말로 샤라웃을 보내고 싶어요. 😎
백엔드단에서 테스트하며 자주 소통을 해서 어떤 문제들이 있었는지 잘알고 있었습니다. 👍🏻
키네시스를 통해서 Opensearch에 들어간 데이터들을 쿼리를 해보니 유의미한 결과를 얻을수 있었습니다. 원래 sql에서 쿼리시 40초 1분이상 걸리던 쿼리 작업이 20-30초로 66퍼나 감소 확 줄여 버린거지요.
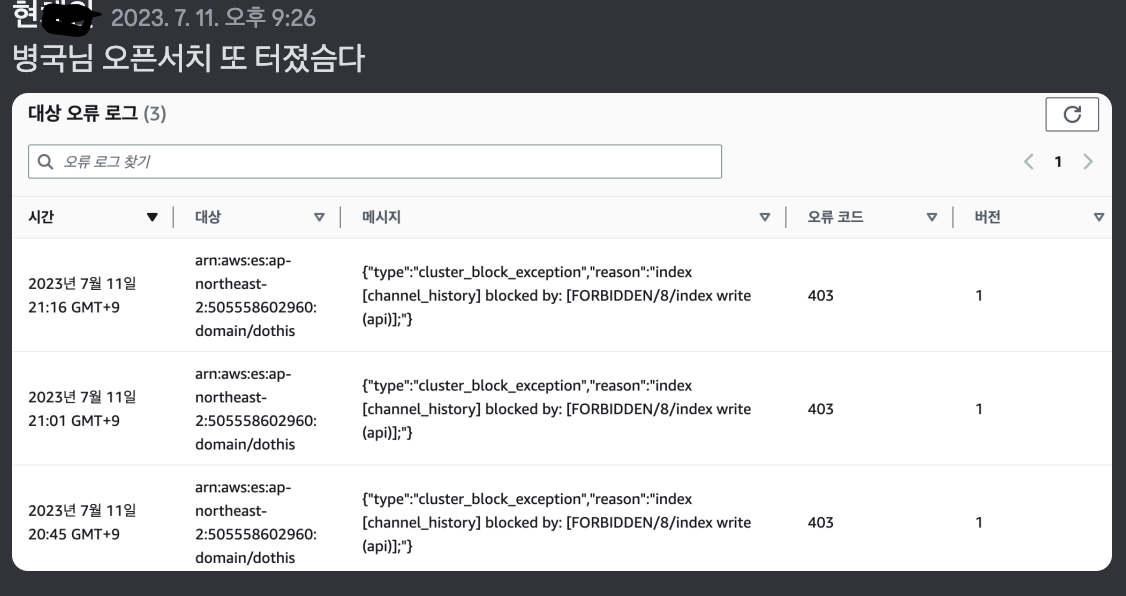 또터진 우리 오픈서치씨 이 로그의 원인은 저위에 포스팅 보시면 잘 설명이 되어있습니다.
또터진 우리 오픈서치씨 이 로그의 원인은 저위에 포스팅 보시면 잘 설명이 되어있습니다.
우리는 이렇게 클라우드 상황을 보며 우리가 가진 예산 범위내에서 최적화하려 노력을 많이 했습니다.
개발 초기 단계에서, 프라이머리 노드와 리플리카 노드를 두고 인덱스를 샤드로 나누는 기본적인 작업을 수행하고 이것저것 만져보고 테스트해 보았지만, 지금 생각해보면 하루 백업 인덱스가 5GB에서 7GB에 이르는 상황에서, 어떤 키워드들을 가지고 와일드카드로 짧게는 며칠, 길면 몇 주씩 분석하고 집계한다는 건 이 방식으로 구현을 하면 빠른게 더 이상하다라는 생각이 듭니다. 😅
남이 저희를 본다면 아직 20-30초나 걸리는 작업을 확 줄었다. 유의미하다라고 자체 평가하는게에 대해서 오십보백보라고 할수 있지만 아무것도 모르는 주니어들이 조금만 더 알아보고 노력한다면 서비스에 한 걸음더 다가가 갈수 있겠다라는 마음을 가지게 된 계기가 된 일이지 않았나 싶어요. 💪🏼
돈이 문제다
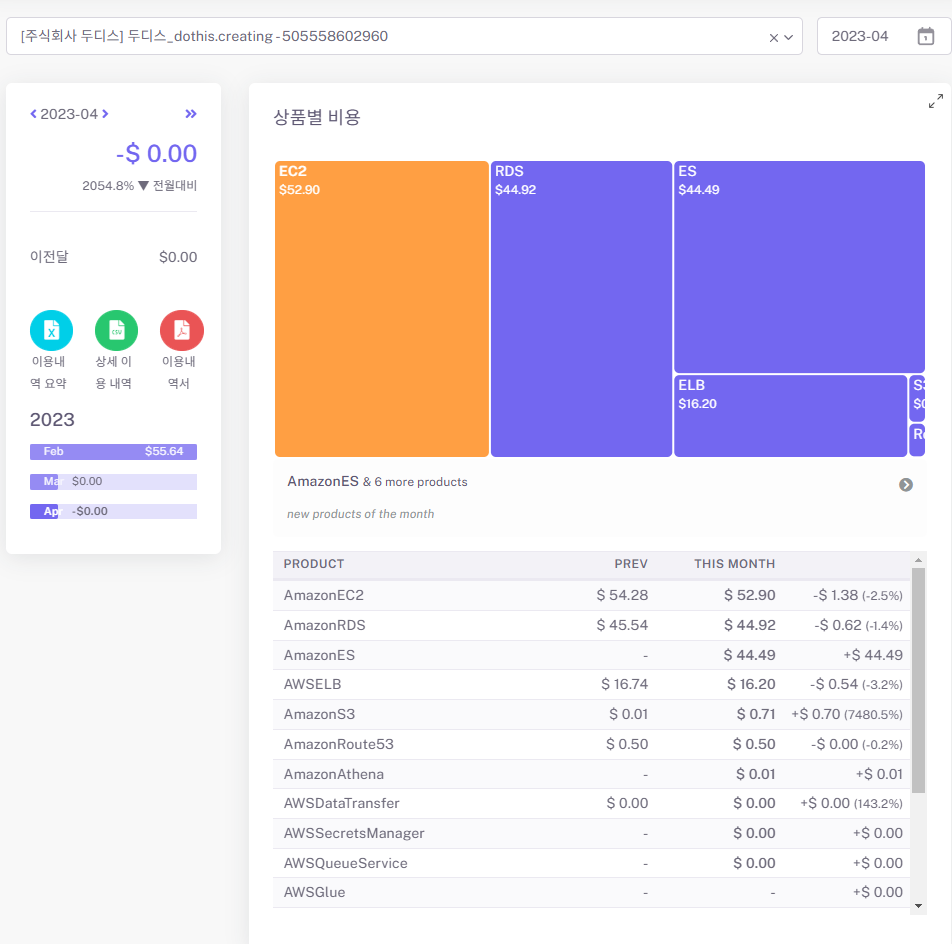
그전의 비용
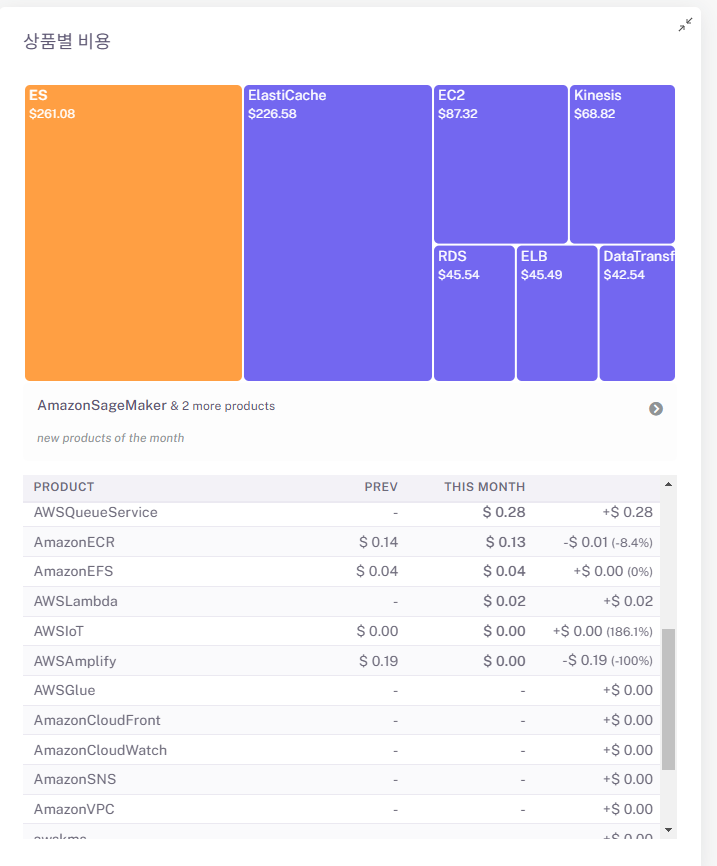
위의 es는 오픈서치를 의미 합니다😂. 우리가 엘라스틱캐쉬와 오픈서치를 도입하므로써 생긴 비용 변화, 람다 크롤링 비용도 많이 나올텐데 이러면 안돼!!!
위에서 볼수 있듯이 비용으로 문제로 인해 또 노선을 바꿔야될 상황에 처했습니다. 우리는 큐목적으로 사용한 엘라스틱캐쉬나 다른 ETL 서비스는 작은 조직에서 비용이 많이 나올수 있다는 문제가 있다는점이 문제였고 그래서 우리는 온프레미스로 컴퓨터를 구매하여 직접 관리하자는 해결책 찾을수 있었습니다.
다음편에 계속....
