다시 돌아온 이유
기존의 OpenSearch로 다시 돌아오게 된 이유는 조인에 있었습니다. 조인에서 부터 생각이 나아갔기 때문에 조인이 많은 리소스를 소모한다는 것을 깨달았고 비정규화를 통해서 빠르게 받아 올수 있겠다는 판단에서 부터입니다. 따라서, 기존에 데이터웨어 하우스에 있는 데이터를 logstach를 통해 비정규화하고 OpenSearch로 데이터를 보다 빠르고 효율적으로 받아올 수 있었습니다.
오픈서치 인덱스 디자인
오픈서치를 활용한 데이터 인덱스 디자인을 통해, 비디오 및 채널 데이터를 효율적으로 관리했습니다. 아래는 각 인덱스와 데이터 스트림에 대한 구체적인 설명입니다.
-
video_data 인덱스
- 설명: 이 인덱스는 타겟 비디오의 상세 정보를 담고 있으며, 정기적으로 크롤링된 데이터를 업데이트합니다. 비디오 제목, 설명, 업로드 날짜 등의 정보가 포함됩니다.
-
video_history 데이터 스트림
- 설명: 매일 백킹 인덱스를 롤업하면서, video_data와 연관된 비디오의 조회수, 좋아요, 댓글 수를 추적합니다. 각 백킹 인덱스는 5GB에서 7GB로 구성되어 있어, 대량의 히스토리 데이터를 효과적으로 관리합니다.
-
channel_data 인덱스
- 설명: 채널의 상세 정보를 담고 있으며, 정기적으로 크롤링하여 업데이트합니다. 채널명, 설명, 구독자 수 등이 포함되어 채널의 전반적인 성과를 모니터링합니다.
-
channel_history 데이터 스트림
- 설명: channel_data와 연관된 채널의 과거 데이터를 추적합니다. video_history와 유사한 구조로, 채널의 조회수, 참여도 등을 롤업 방식으로 관리하여 데이터를 효율적으로 분석합니다.
데이터 중복 및 비정규화
원래 각 데이터 및 히스토리 인덱스에는 중복 데이터가 없었지만, 빠른 퍼포먼스를 위해 데이터 중복이 발생하도록 비정규화를 선택했습니다. 이를 통해 조회 성능을 향상시키고, 필요한 데이터를 보다 신속하게 추출할 수 있는 환경을 구축하게 되었습니다.
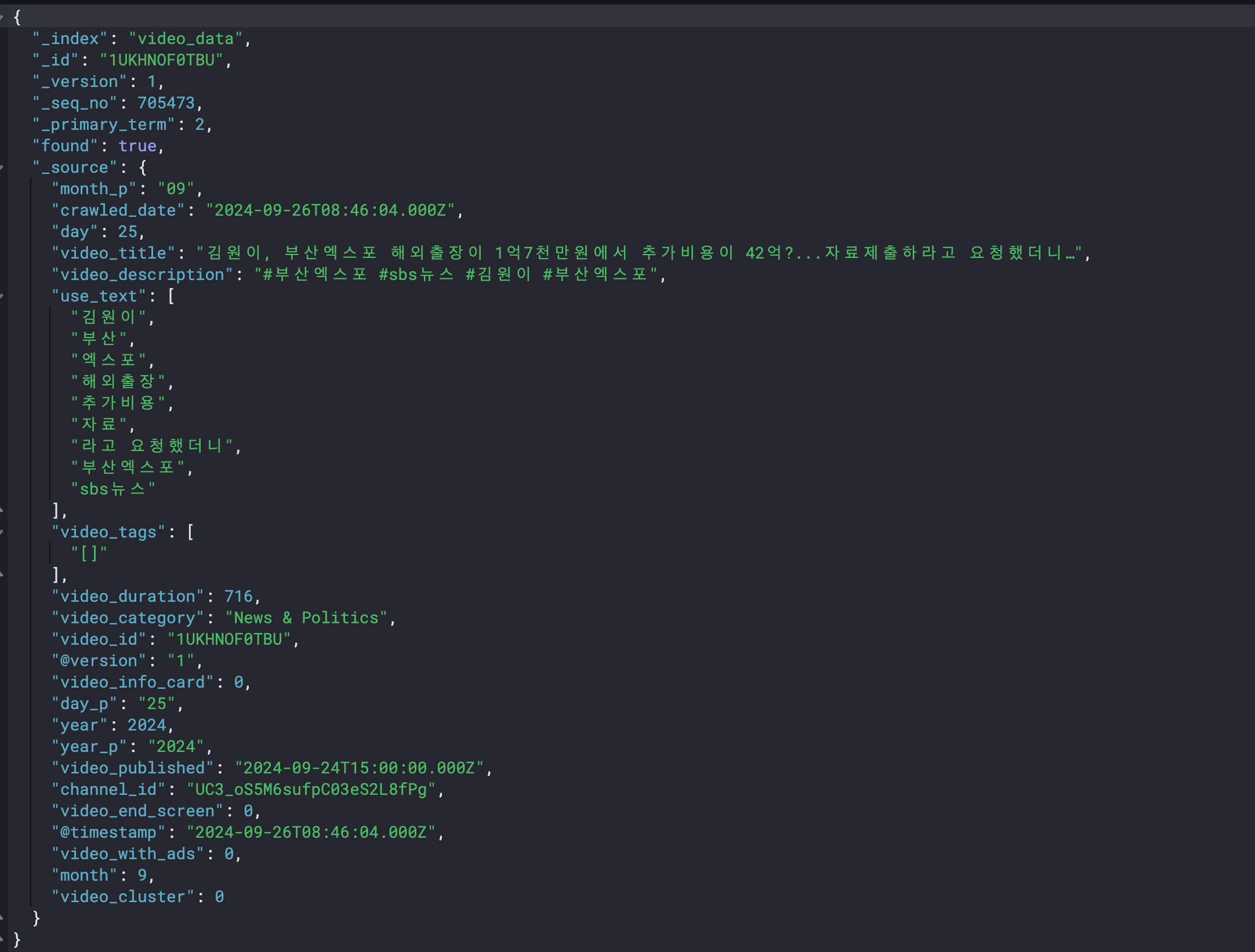
video_data 인덱스 데이터 일부분
오픈서치의 루씬 엔진은 어떻게 이렇게 빨리 문서를 찾을까?
루씬 엔진은 어떻게 빨리 데이터를 찾을수 있을까라는 의문부터 시작하여 역색인이라는 기술로 빠르게 찾는다는 것을 알게 되었습니다. 우리 데이터로 간단하게 예를 들어 설명하면 아래와 같습니다.😎
예시 데이터
다음과 같은 비디오 정보가 있다고 가정해봅시다 😀
| video_id | title | description | views | published_date |
|---|---|---|---|---|
| 1 | 사과 먹는 법 | 사과를 맛있게 먹는 방법 | 1000 | 2024-01-01 |
| 2 | 바나나 요리법 | 바나나를 활용한 요리법 | 500 | 2024-01-02 |
| 3 | 사과 요리 | 사과로 만든 다양한 요리 | 800 | 2024-01-05 |
역색인 생성 과정
-
단어 추출:
title및description필드에서 단어를 추출합니다.- 예를 들어, "사과 먹는 법", "바나나 요리법", "사과 요리" 같은 단어들입니다.
-
단어와 문서 ID 매핑:
- 각 단어를 키로 하고, 해당 단어가 포함된 비디오의
video_id를 값으로 설정합니다.
- 각 단어를 키로 하고, 해당 단어가 포함된 비디오의
결과
| 단어 | 문서 ID |
|---|---|
| 사과 | [1, 3] |
| 바나나 | [2] |
| 먹는 법 | [1] |
| 요리법 | [2] |
| 다양한 | [3] |
| 맛있게 | [1] |
검색 예시
- 사용자가 "사과"로 검색할 경우:
- 역색인을 통해 "사과"와 관련된 모든 비디오를 신속하게 찾을 수 있습니다.
- 결과적으로, 해당 단어가 포함된 비디오 ID
[1, 3]를 반환하여 사용자가 "사과 행위를 다루는 비디오"를 쉽게 찾아볼 수 있도록 합니다.
생각의 전환
위에 발췌한 데이터에서 볼수 있듯이 모델로 유튜브 데이터의 명사만을 추출하기 위해 전처리해서 use_text라는 필드를 만들어 빠르게 찾을려고 노력했으나 빨라지긴 했지만 유저 입장에서는 느릴수 있을꺼 같아 다른 방법을 찾아 봤습니다. 🥲
당장 ignite에서의 쿼리 방식이 wildcard, WHERE text Like%키워드%를 활용한 찾기여서 리소스를 많이 잡아 먹을수 밖에 없었던거 였고 어떤 사양의 서버 자원에도 버티지 못했었습니다.
그러다가 생각해낸게 저 루씬엔진 역색인입니다. 우리가 가진 비디오 데이터들의 타이틀들을 토큰화시켜 레디스에 set 형태로 저장하고 빠르게 찾아 올수 있도록 구현했습니다.
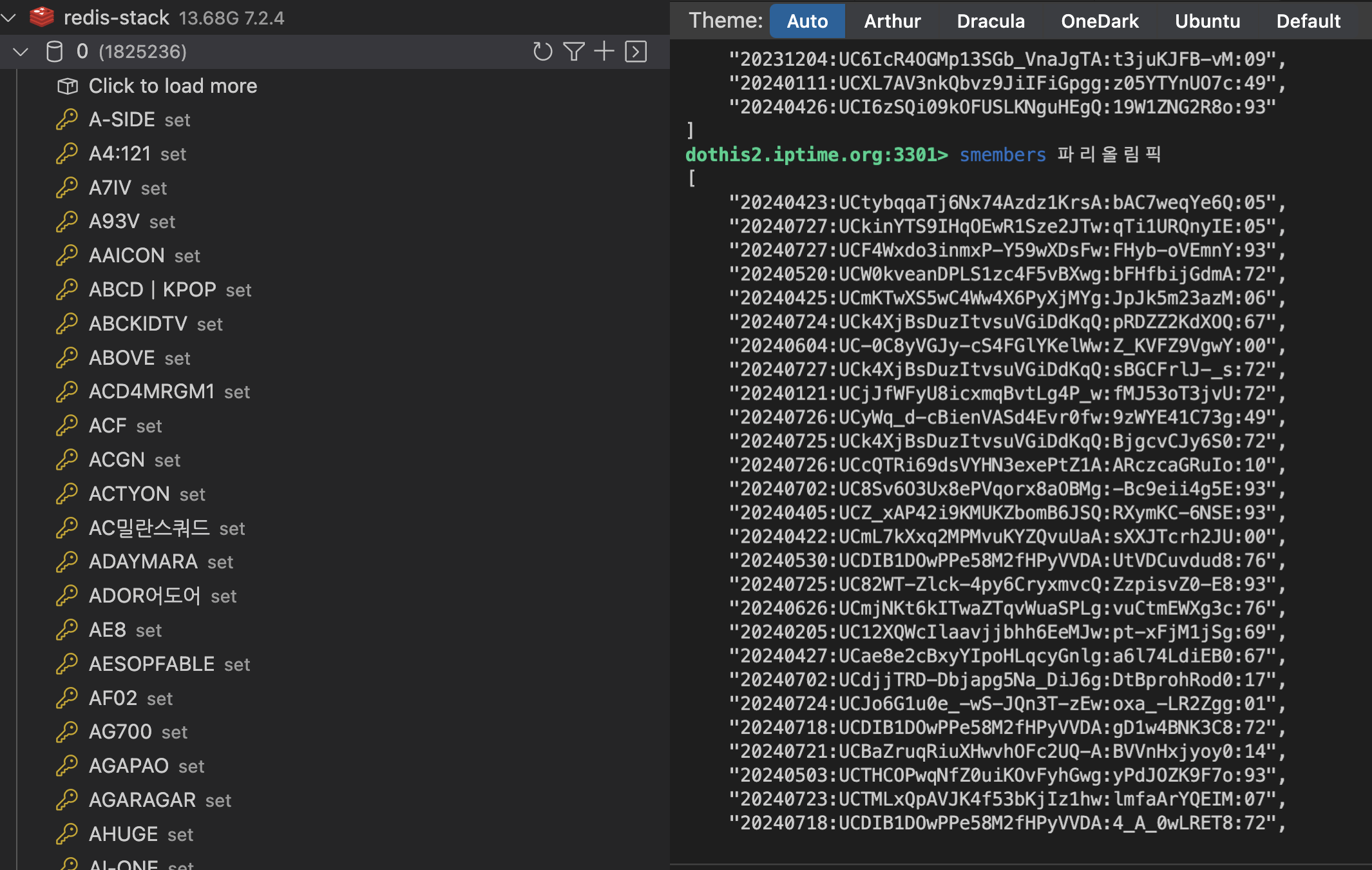
토큰화 데이터
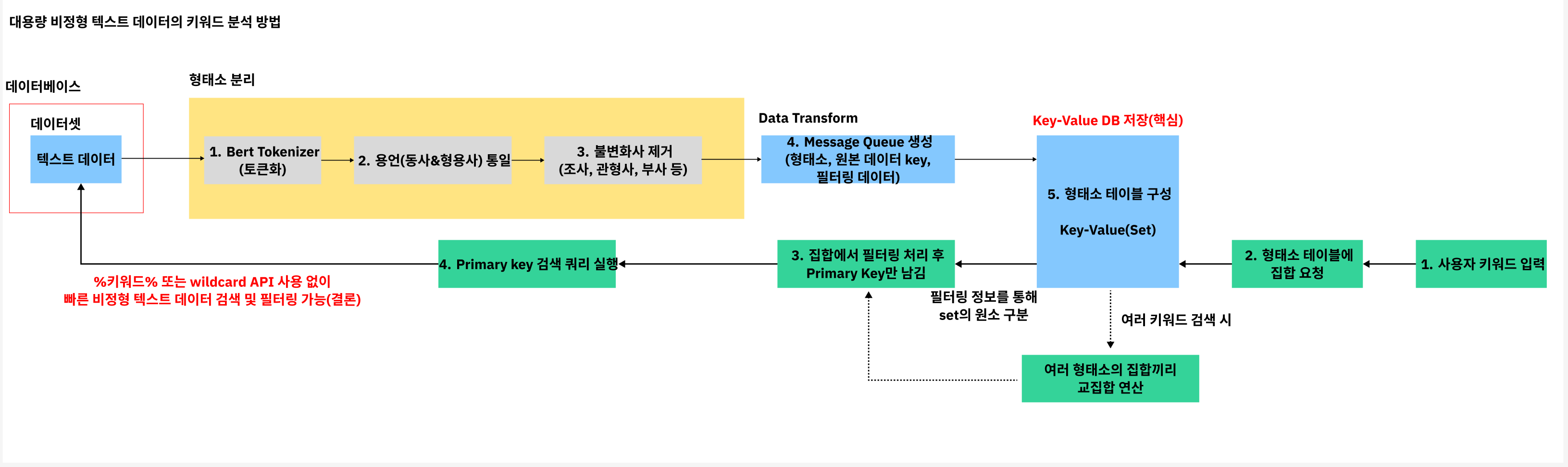
우리가 구현한 시스템의 다이어그램
BERT로 시작하는 비정형 텍스트 처리
먼저, 구글에서 개발한 언어 모델 BERT(Bidirectional Encoder Representations from Transformers)는 텍스트 데이터를 세밀하게 분석하는 데 도움을 줍니다. 예를 들어, 긴 문장에서 특정 단어나 구를 추출하려면 먼저 텍스트를 작은 단위(형태소)로 나누어야 합니다. BERT는 이 작업을 높은 정확도로 수행하며, 한국어 문법에도 알맞게 작동합니다.
한국어 텍스트의 복잡함을 극복하기: 용언 통일과 불변화사 제거
한국어는 같은 단어라도 여러 형태로 변형됩니다. 예를 들어 “예쁘다”라는 단어는 “예쁜”, “예뻐하다”와 같이 다양한 형태로 사용되죠.
이런 용언(동사나 형용사)의 다양성은 데이터 분석을 어렵게 만듭니다. 그래서 우리는 “대표 형태”를 하나로 통일하는 과정을 거칩니다. 이를 용언 통일이라고 합니다. 예를 들어, “예쁘다”, “예쁜”, “예뻐하다”를 모두 “예쁘다”로 변환하면 분석이 훨씬 간단해집니다.
또한, 문장에서 문법적 역할을 하는 불변화사(예: 은/는, 이/가, -히 등)는 제거해야 합니다. 이런 불변화사는 검색과 직접적인 관련이 없기 때문에 제거하고, 텍스트의 본질적인 의미를 담는 단어만 남깁니다.
Message Queue로 효율적 데이터 관리
형태소와 원본 데이터의 식별 정보(Primary Key), 그리고 날짜, 조회수, 카테고리 등 필터링에 필요한 정보를 포함한 데이터를 Message Queue에 전송하면, 이를 통해 데이터의 중복이나 누락 없이 안정적으로 처리할 수 있습니다. 저희는 Kafka를 사용했습니다.
형태소 테이블과 Key-Value DB
Redis, Key-Value DB는 간단하면서도 강력한 구조를 가지고 있습니다. 여기서 Key는 형태소, Value는 해당 형태소가 사용된 텍스트의 Primary Key와 필터링 정보를 집합(Set)으로 저장합니다. 예를 들어, “예쁘다”라는 키에 대해 관련된 모든 데이터가 하나의 집합으로 연결됩니다.
결과
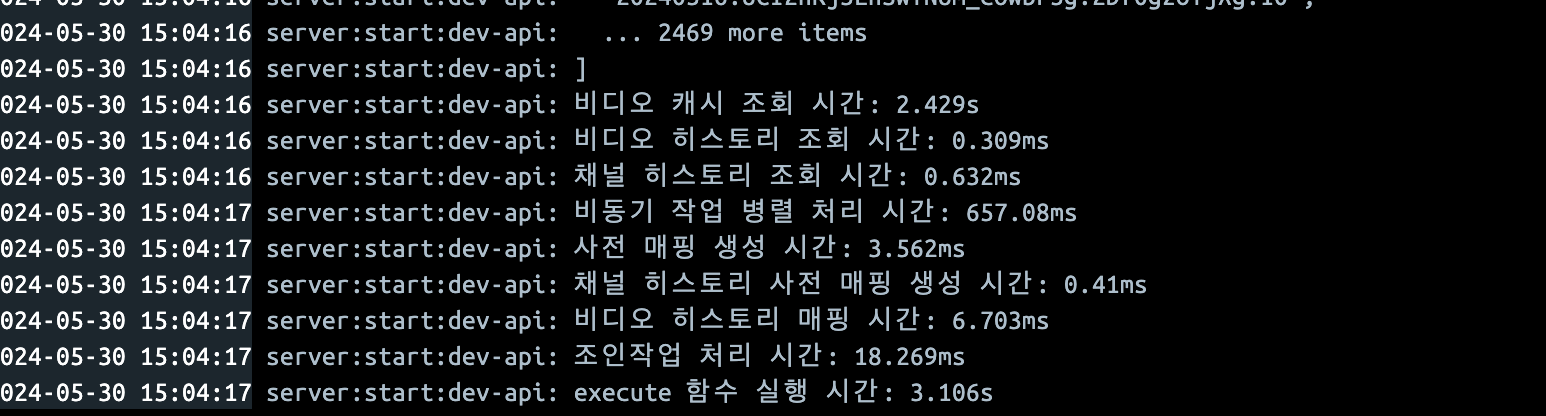
2년에 걸친 사투가 드디어 결실을 맺었습니다. 비디오 캐시를 쿼리하는 데 다소 시간이 소요되는 부분은 남아있지만, 프로젝트 전체적으로는 드라마틱한 성과를 거두었습니다. 초기에는 40초에서 50초가 걸리던 쿼리가 이제는 단 3초 만에 처리된다는 사실은, 함께 노력해온 PO님과 팀원들의 헌신과 열정 덕분이었습니다. 😊
히스토리 검색 부분에서는 하나의 백킹 인덱스가 5기가-7기가임에도 불구하고, 이처럼 빠른 속도를 보여주었다는 점은, 우리가 구현한 시스템의 성능 향상 가능성을 더욱 기대하게 만들었습니다. 이는 우리의 전략과 생각들이 올바랐다는 것을 증명하는 결과이며, 앞으로도 이러한 과정을 통해 더 나은 결과를 만들것이라고 생각이 들게 만드는 경험이였습니다. 더 나아가, 이러한 혁신적인 시스템을 특허로 출원 완료하며, 우리의 노력과 결실이 인정받게 되어 더욱 뿌듯합니다. 🎉
팀의 노력과 협업이 만들어 낸 이 성과는 앞으로도 더 큰 도전과 성취를 위한 원동력이 될 것입니다. 😘
