
개요
프로젝트는 새로운 데이터 엔지니어가 합류하시고 변곡점에 이르렀습니다. DBA도 경험하신분이고 실력과 인간적인 미까지 겸비하신 분이였습니다. 😁 새로운 데이터 엔지니어분과 크롤링 파이프라인의 재설계를 주도 하셨습니다. 저는 PO와 함께 오픈서치 데이터를 쌓으면서 어떻게 하면 효율적인 데이터 모델링이 될까 고민했습니다.

우리 서버컴의 영롱한 자태를 보아라!!!!
우리가 서비스하기 적합한 인덱스 설계는 어떻게 해야될까?
Nested 모델링
엘라스틱서치에서 Nested data type을 활용해 설계하는 방법입니다. 하나의 인덱스에서 Nested data type을 선언하고 오브젝트 속성들을 정의하여 연속(Array)하게 배치하는 방식입니다.
출처 : https://www.samsungsds.com/kr/insights/elastic_data_modeling.html
오픈서치에 관계형 데이터 모델링 방법은 4가지 정도가 있습니다. 우리 프로젝트는 영상의 조회수를 추적해야되기때문에 매일 크롤링된 영상의 조회수를 nested 안에 저장해야 된다고 생각을 잠깐 했습니다.
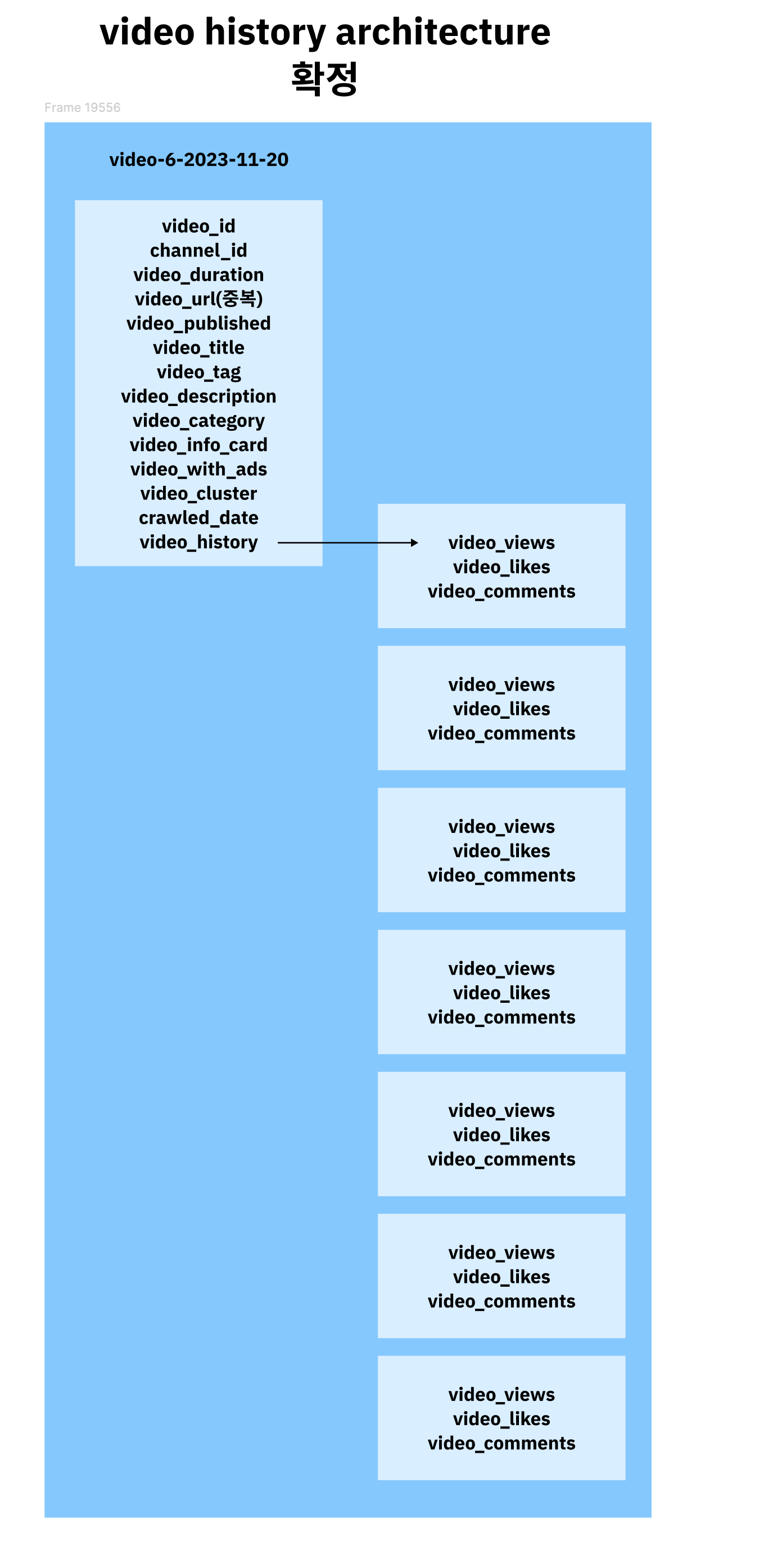
이런식으로 nested 안에 히스토리를 하루하루씩 쌓여나가는 방식
이러한 데이터형태를 더미데이터로 넣고 테스트 중이였습니다. 테스트하다보니 사실 우아한 형제들 기술블로그에서 참고하여 식당의 메뉴를 빠르게 개선하기 위한 사례를 참고 했었는데 우아한 형제들은 메뉴는 계속 늘어날 우려가 없고 우리는 매일 조회수가 늘어나기 때문에 update에 대한 것이 성능의 저하는 물론이고 나중에 늘어나면 샤드를 늘려줘야되기 때문에 리인덱싱을 해야된다 그 작업도 만만치 않을것 같았습니다. 그래서 테스트를 하는 동안에도 계속 반신반의 했고 불안한 마음에 계속해서 PO분이랑 소통을 많이 했던거 같아요.🥶
그러던 중에 생각이 깨어나는 의견이 들어왔습니다.
이그나이트로의 전환
이그나이트는 인메모리 데이터 관리 시스템으로, 빠른 데이터 처리와 분석을 지원하며, 실시간 쿼리 성능을 극대화합니다.
새로 합류한 DE분은 이그나이트라는 인메모리기반에 sql쿼리를 활용하여 조인을 할수있는 데이터베이스로 전환을 해보는것이 어떻냐는 의견을 주셨습니다. 클라우드로 사용하기에는 인메모리라서 비용이 많이 나올꺼 같고 우리 서버컴퓨터에 온프레미스로 사용을 해보자는 것이 관건이였습니다. 처음 듣는 데이터베이스여서 러닝커브가 좀 필요했습니다. Apache에서 제공하는 Thin Client라는 Ignite를 연결하는 라이브러리는 유지보수 한지가 많은 시간이 지나서 지금 사용하기엔 약간 기능적 측면에서나 안정성 측면에서도 사용하기 좀 힘들어 보였습니다. 그러나 그런것이 부족하다면 직접 안정성, 기능적인걸 보완하면 된다고 생각했었기에 빠르고 조인이 잘 된다는 가능성만 믿고 한번 엎어 보기로 했습니다. 🤣
참고 : https://www.npmjs.com/package/apache-ignite-client
처음 테스트시에는 정말 빨랐습니다. 아직까지 ETL 파이프라인을 구현중이였고 캐쉬된 데이터의 용량 자체도 작아서 그런지 빠른 response 반응을 보였습니다. 조인 성능도 빨라서 진짜 우리 디비를 찾았구나 생각을 했습니다.
또 다른 시련?
연결 관리, 헬스 체크 로직등을 직접 구현해서 사용했으며 DE님의 도움으로 싱글톤으로 동작하도록 구현했습니다. 그래도 매회 실행될때마다 연결하니 디비가 불필요한 리소스를 낭비하는 경우가 생기고 응답을 하는 도중에 뻗어 버리는 상황이 빈번하게 일어났습니다.
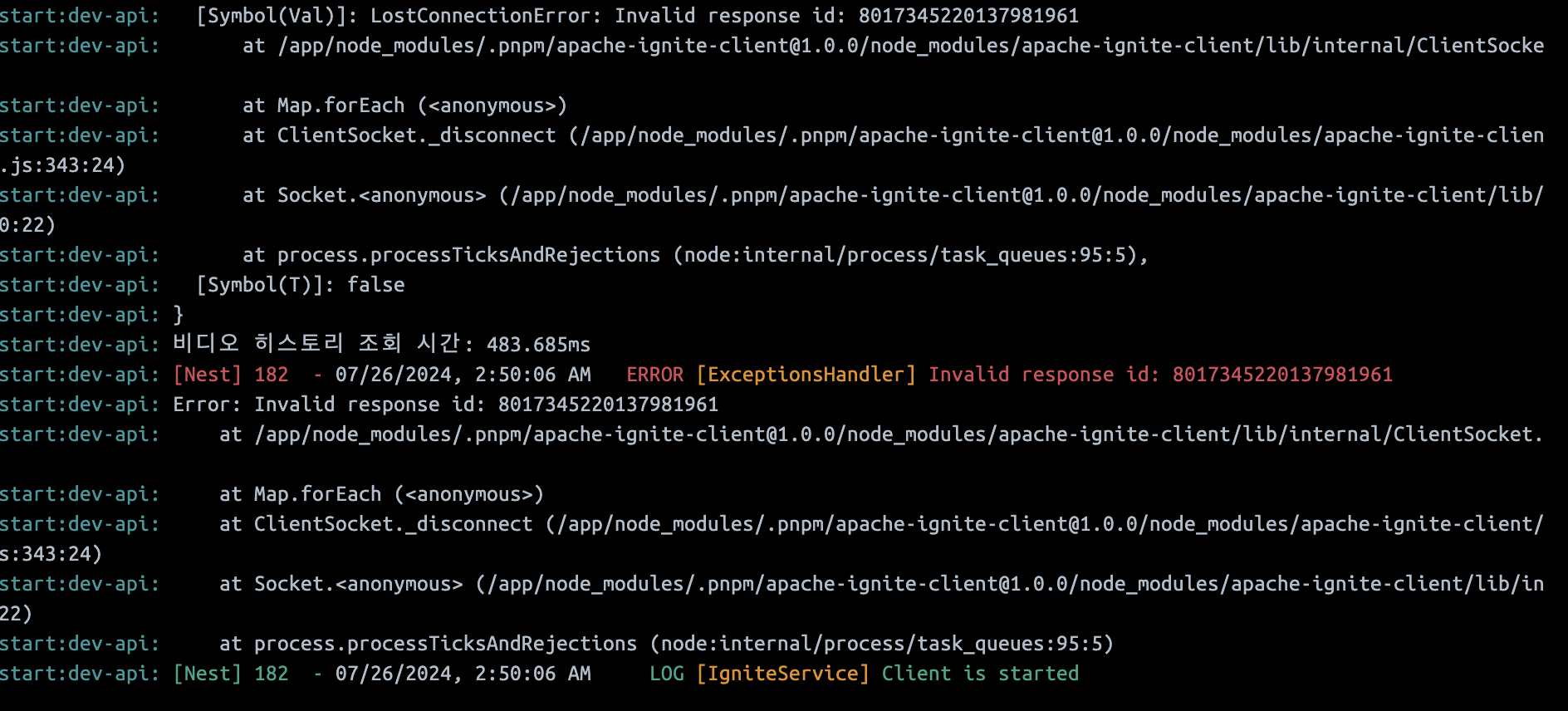
도대체 왜그럴까? 시련 그만좀
이건 오류 메세지는 커넥션을 잃어버리는것인데 커넥션을 잃어버리는거에 중점을 두고 나름의 커넥션 풀링을 도입해서 테스트를 해보았습니다만 계속 위와 같은 오류와 타임아웃이 걸려서😂 매회 api 요청이 들어올때마다 연결하고 끊고 이런 방식으로 로직을 바꿔 보았습니다. 테스트 결과는 아래와 같습니다.
테스트 리포트 요약
기본 정보
테스트 실행 ID: t35qm_ndxfpawpnk3renqnbtz4thfq484eh_kbqy
총 소요 시간: 2분 1초
총 가상 사용자 수(VUs): 300
성공적인 요청 수(HTTP 200 응답): 17
다운로드된 총 바이트 수: 16,826 bytes
총 HTTP 요청 수: 300
평균 요청 속도: 초당 3 요청
성공적으로 완료된 VU 수: 17
실패한 VU 수: 283
주요 오류
ETIMEDOUT: 283건
세션 길이 (응답 시간)
최소: 29,635 ms
최대: 59,313.1 ms
평균: 46,834.2 ms
중앙값: 45,720.8 ms
95 퍼센타일: 55,843.8 ms
99 퍼센타일: 55,843.8 ms
시간대별 세부 사항
#### 08:24:40 (+0000)
요청 수: 45
생성된 VUs: 45
#### 08:24:50 (+0000)
요청 수: 50
생성된 VUs: 50
#### 08:25:00 (+0000)
요청 수: 52
생성된 VUs: 52
#### 08:25:10 (+0000)
요청 수: 50
성공 응답 수 (HTTP 200): 1
다운로드된 바이트: 1,081 bytes
실패한 VUs: 0
#### 08:25:20 (+0000)
요청 수: 50
성공 응답 수 (HTTP 200): 11
다운로드된 바이트: 10,763 bytes
실패한 VUs: 0
#### 08:25:30 (+0000)
요청 수: 49
성공 응답 수 (HTTP 200): 4
다운로드된 바이트: 3,901 bytes
실패한 VUs: 0
#### 08:25:40 (+0000)
요청 수: 4
성공 응답 수 (HTTP 200): 1
실패한 VUs: 28
#### 08:25:50 (+0000)
실패한 VUs: 50
#### 08:26:00 (+0000)
실패한 VUs: 51
#### 08:26:10 (+0000)
실패한 VUs: 51
#### 08:26:20 (+0000)
실패한 VUs: 49
#### 08:26:30 (+0000)
실패한 VUs: 50
#### 08:26:40 (+0000)
실패한 VUs: 4
결론
이번 테스트에서 가상 사용자 수는 총 300명이었으나, HTTP 요청에서 성공적인 응답은 매우 낮았고, 많은 VU들이 타임아웃 오류를 경험했습니다. 특히 ETIMEDOUT 오류가 283건 발생하여 성능 문제가 우려됩니다. 요청의 평균 응답 시간이 높은 점도 확인되었습니다.Artillery 테스트 했으며 테스트결과는 gpt에서 해석을 시켰습니다.
이 테스트 이후에 이그나이트는 죽어 버렸습니다. 우리는 다 재택근무를 하고 있었는데 가까운 팀원분이 다시 서버를 켜로 가야되는 불상사까지 벌어졌습니다.😂
이그나이트가 우리에 맞지 않았던 점
우리가 이그나이트에서 어려움을 겪었던 이유는 팀원들 마다 거의 상통한 의견으로 보고 있습니다.
DE & DBA 김xx
우리가 가진 데이터는 대용량 시계열 데이터였고, 약 80 GB 메모리에서 처리하기에는 무리가 있었습니다. Ignite는 주로 key-value 저장을 지원하지만, 우리는 SQL 플러그인을 중심으로 사용하려 했고, 이에 대한 레퍼런스가 부족해 트러블슈팅이 어려웠습니다.
오픈서치와 달리, Ignite는 조인이 잘 되어 분석가나 애플리케이션에서 데이터를 쉽게 인출할 수 있었습니다. 그러나 메모리를 초과하는 대용량 데이터나 LIKE 조건절을 사용한 텍스트 데이터에서는 성능이 부족했습니다.
모니터링 시스템이 충분하지 않았고, 후반에는 GridGain을 사용해봤지만, 이는 기간제였고 특정 Ignite 버전과의 호환성 문제도 있었습니다. 동시성 처리도 아쉬웠으며, 선행 세션이 리소스를 많이 사용하면 후행 세션의 쿼리 대기가 길어졌습니다. 추가로, idle 세션 관리 정책을 찾기 어려웠습니다.
파티션의 네이티브 동작이 불완전했습니다. 오라클이나 마리아DB처럼 특정 파티션에 빠르게 접근하지 못했고, 메모리에 비해 데이터가 많아져 불필요한 메모리 작업이 발생했습니다. 파티션을 쪼개 두었지만, 전문 검색이나 전체 데이터를 union all로 처리해야 했던 상황이 많았습니다.
처음부터 데이터 특성과 텍스트 데이터량을 잘 파악했더라면, PostgreSQL 및 기타 도구들을 사용하여 시스템을 구성했을 것입니다.
PO 민xx
우리는 데이터 집계 속도를 높이기 위해 테스트 시 라이브 서비스와 동일한 데이터 양을 적재하여 더 다양한 시도를 해봤더라면 더 좋았을 것입니다. 인적·물적 자원의 한계가 아쉬웠고, DE님의 조언처럼 하둡이나 임팔라를 사용해볼 수 있었지만, Ignite가 불안정했던 이유 중 하나는, 우리가 key-value가 아닌 RDS처럼 사용했기 때문일 가능성도 큽니다.
제가 맡은 백엔드 입장에서 디비 자체 집계를 넘어 서버에서 계산하는 로직을 짜는 입장에서 조인은 큰 부담으로 다가왔습니다. 우리가 선택하는 디비의 요구 사항이 조인에 집중되어 있었기 때문에, 그걸 해결하려 조인으로 인한 성능 저하, 디비가 죽는 것를 해결하기 위해 서버에서 자체적으로 조인하는 방식을 시도했지만, API 호출 시 시간이 많이 소요되어 성능이 떨어지는 경험을 하게 된 때문입니다. 🥲 그래서 우리는 비정규화와 우리의 목적에 맞는 디비를 다시 찾기로 했고 결국은 logstach와 opensearch로 다시 회귀 했습니다. 정말 열정적인 우리 팀원분들😆
다음 포스팅에 계속 됩니다~~
별점: 이그나이트 오픈서치 비교 테스트
최대 검색량 설정 변경
PUT /video-history/_settings
{
"index": {
"max_result_window": 1000000
}
}
Respone
{
"acknowledged": true
}데이터 검색 속도
GET video-history/_search
{
"query": {
"match_all": {}
},
"size":10000
}
### size 변경해가며 테스트
1000 : 164 ms
10000 : 1301 ms
20000 : 2670 ms
50000 : 6588 ms
100000 : 12510 ms- 참고
- 주간 조회수 기준 가장 영상이 많은 키워드
- 전망 : 6513
- 주식 : 6226
- 분석 : 2982
- 비트코인 : 2958
- 단, 전체적으로 영상 수가 적게 나온 것이, 데이터 누락이 의심되니 주의
- 주간 조회수 기준 가장 영상이 많은 키워드
데이터 집계 속도
GET video-history/_search
{
"size": 10000,
"aggs": {
"average_views": {
"avg": {
"field": "video_views"
}
}
}
}
### 검색된 데이터들의 평균을 구하는 쿼리
10000 : 1550 ms
20000 : 2770 ms
50000 : 6635 ms
100000 : 13092 ms
CPU 사용량 : 6% of 8 CPUGPT가 추천한 고비용 집계 쿼리
GET video-history/_search
{
"size": 100000,
"aggs": {
"popular_channels": {
"terms": {
"field": "video_id.keyword",
"size": 10
},
"aggs": {
"average_views": {
"avg": {
"field": "video_views"
}
}
}
}
}
}
respone
"aggregations": {
"popular_channels": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 7600267,
"buckets": [
{
"key": "---3Rqk77WM",
"doc_count": 1,
"average_views": {
"value": 51081
}
},
{
"key": "---4xDkKpao",
"doc_count": 1,
"average_views": {
"value": 180
}
},
...
10000 : 3141 ms
100000 : 14354 ms
인덱스 사이즈에 따른 속도 차이 테스트
-
위 사진은 video_data 인덱스 중 video_cluster가 0인 데이터만 분리하여 video_data_00 인덱스에 복제한 사진
- 데이터 양은 video_data:807만 개, video_data_00:34만 개로 약 24배
-
다음과 같은 쿼리로 검색한 결과
GET video_data_00/_search { "query": { "bool": { "must": [ { "term": { "video_cluster": 0 } } ] } }, "size": 1000 } video-data 1000 : 415 ms 10000 : 3834 ms video_data_00 1000 : 440 ms 10000 : 3503 ms SELECT cd.channel_name, cd.channel_link, ch.channel_subscribers, ch.channel_total_videos, ch.channel_average_views, cd.mainly_used_keywords FROM ${tableName} cd JOIN ${joinTableName} ch ON cd.channel_id = ch.channel_id WHERE cd.channel_id = '${channelId}' AND ch.DAY = (SELECT MAX(DAY) FROM ${joinTableName}); -
추가로, 파티셔닝을 가정해 여러 인덱스 동시에 검색한 결과
GET /video_data_00,video_data_01,video_data_02/_search { "query": { "bool": { "must": [ { "term": { "video_cluster": 0 } } ] } }, "size": 1000 } 1000 : 482 ms 10000 : 3470 ms
- 파티셔닝 효과 없음
샤딩에 따른 속도 차이
- video_data 데이터양 : 807만 개
- 1-shards : 7857 ms
- 4-shards : 3834 ms
- video_data_01 데이터 양 : 76만 개
- 1-shards : 7611 ms
- 2-shards : 5824 ms
- 4-shards : 5429 ms
오픈서치 테스트
- 이그나이트에서 CPU 50% 가까이 사용하는 API와 동일한 기능을 수행하는 오픈서치 쿼리 실행
체크 항목
- 쿼리 길이 : 이그나이트에서는 길이가 길다고 거절당한 쿼리 실행해보기
- 코드 복잡성 : 같은 쿼리를 node.js에서 사용할 때 복잡해지지 않는지 확인
(최대 검색량은 10,000 -> 1,000,000 건으로 증가시켜뒀으니 scroll API같은 nextPage는 안해도 됩니다) - 시간 : 10,000 건 기준 3초 이내
(ignite '서울 24-07-20 ~ 24-07-29 ' 검색 시 2300 ms)
(ignite '주식 24-07-20 ~ 24-07-29 ' 검색 시 38000 ms)
(ignite '전망 24-07-20 ~ 24-07-29 ' 검색 시 12000 ms) - CPU 사용량 : 10회 연속 쿼리 실행 시 50% 이하
