
📢Renaming and Combining
데이터분석 : 1. 데이터 생성 및 읽기
데이터분석 : 2. 인덱싱, 선택 및 할당
데이터분석 : 3. 요약 기능 및 맵
데이터분석 : 4. 그룹화 및 정렬
데이터분석 : 5. 데이터 유형 및 결측값
데이터분석 : 6. 이름 변경 및 결합
📌1. 소개(Introduction)
-
데이터는 우리에게 열 이름, 인덱스 이름 또는 기타 우리가 만족스럽지 않은 이름으로 전달된다. 이 경우, pandas 함수를 사용하여 문제가되는 항목의 이름을 변경하는 방법을 배워보자!
-
여러 DataFrame 또는 Series에서 데이터를 결합하는 방법을 배워보자!
이전과 마찬가지로 Keggle데이터를 활용하여 실행하자.
import pandas as pd
pd.set_option('display.max_rows', 5)
reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)📌2. 이름 변경(Renaming)
📍rename()
- rename() 함수를 사용하면 인덱스 이름 또는 열 이름을 변경할 수 있습니다.
❗데이터셋에서 points 열을 score로 변경할 떄:
reviews.rename(columns={'points': 'score'})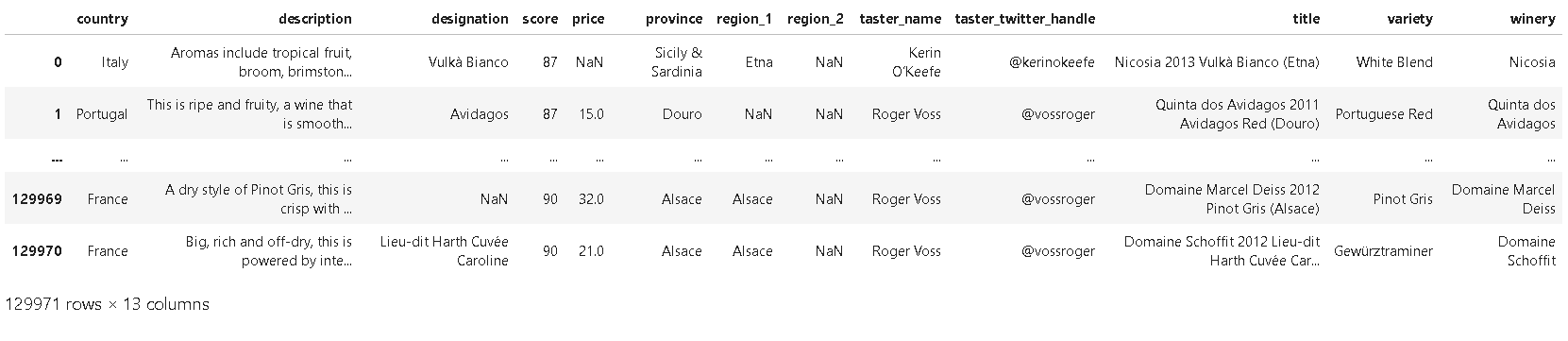
- rename() 함수는 각각 index 또는 column 키워드 매개변수를 지정하여 인덱스 또는 열 값을 변경할 수 있다.
- 다양한 입력 형식을 지원하지만 일반적으로 Python 문법이 제일 편리하다.
❗인덱스의 일부 요소의 이름을 변경할 떄:
reviews.rename(index={0: 'firstEntry', 1: 'secondEntry'})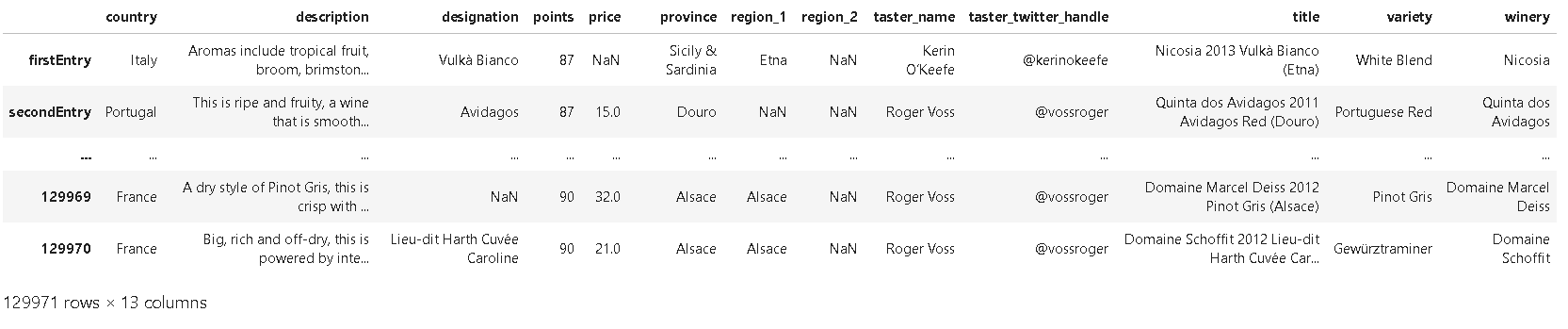
❗'region_1' 열 -> 'region', 'region_2' 열 -> 'locale' 이름 변경
renamed = reviews.rename(columns=dict(region_1='region', region_2='locale'))- 열 이름을 자주 변경하게 될 것이지만 행 인덱스의 이름을 변경하는 경우는 매우 드물다.
- 이를 위해서는 일반적으로 set_index()가 더 편하다.
📍rename_axis()
- 행 인덱스와 열 인덱스는 각각 자체적인 이름 속성을 가질 수 있다.
❗rename_axis() 메서드를 사용하여 이름을 변경할 때:
reviews.rename_axis("wines", axis='rows').rename_axis("fields", axis='columns')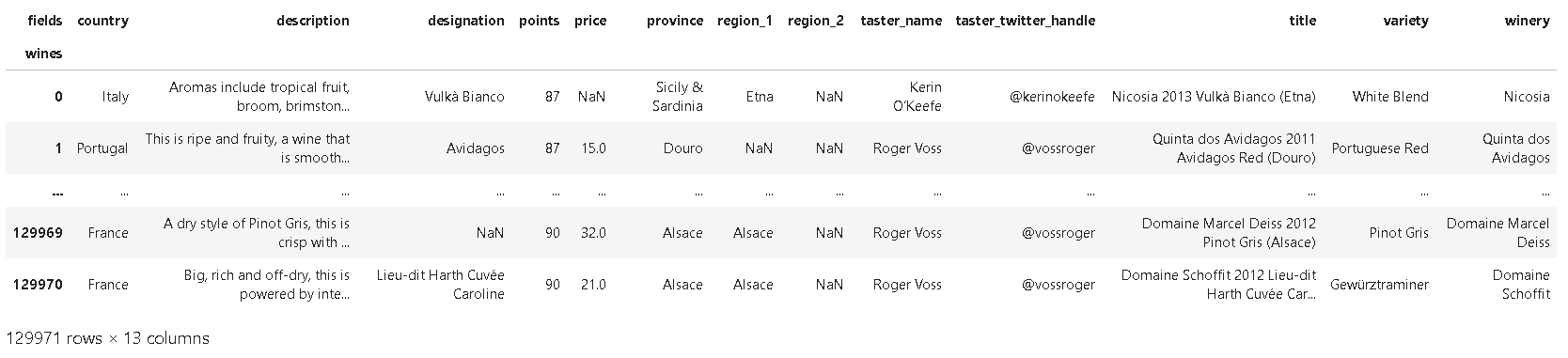
📌3. 결합(Combining)
- 프로그램을 수행하는 동안 데이터셋을 조작할 때는 때로는 다른 DataFrame 또는 Series를 복잡한 방식으로 결합해야 할 때가 있다.
- 판다스에는 concat(), join(), merge()라는 세 가지 핵심 방법이 있습니다.
- 복잡성이 증가하는 순서로 나열하면 concat(), join(), merge()입니다.
- merge()가 수행할 수 있는 대부분의 작업은 join()으로 더 간단하게 수행할 수 있으므로, 여기서는 첫 번째 두 함수에 중점을 두고 merge()를 생략할 것이다.
📍concat()
-
가장 간단한 결합 방법은 concat()이다.
-
요소들의 목록이 주어지면 이 함수는 축을 따라 해당 요소들을 함께 합치게 된다.
-
이는 서로 다른 DataFrame 또는 Series 객체에 데이터가 있지만 동일한 필드(열)를 가지고 있는 경우에 유용하다.
예를 들어, YouTube 동영상 데이터셋은 원산지(예: 캐나다 및 영국)별로 데이터를 분할합니다. 여러 개의 국가를 동시에 연구하려는 경우 concat()을 사용하여 데이터를 합칠 수 있습니다.
❗concat()을 사용하여 데이터를 합칠 때:
canadian_youtube = pd.read_csv("../input/youtube-new/CAvideos.csv")
british_youtube = pd.read_csv("../input/youtube-new/GBvideos.csv")
pd.concat([canadian_youtube, british_youtube])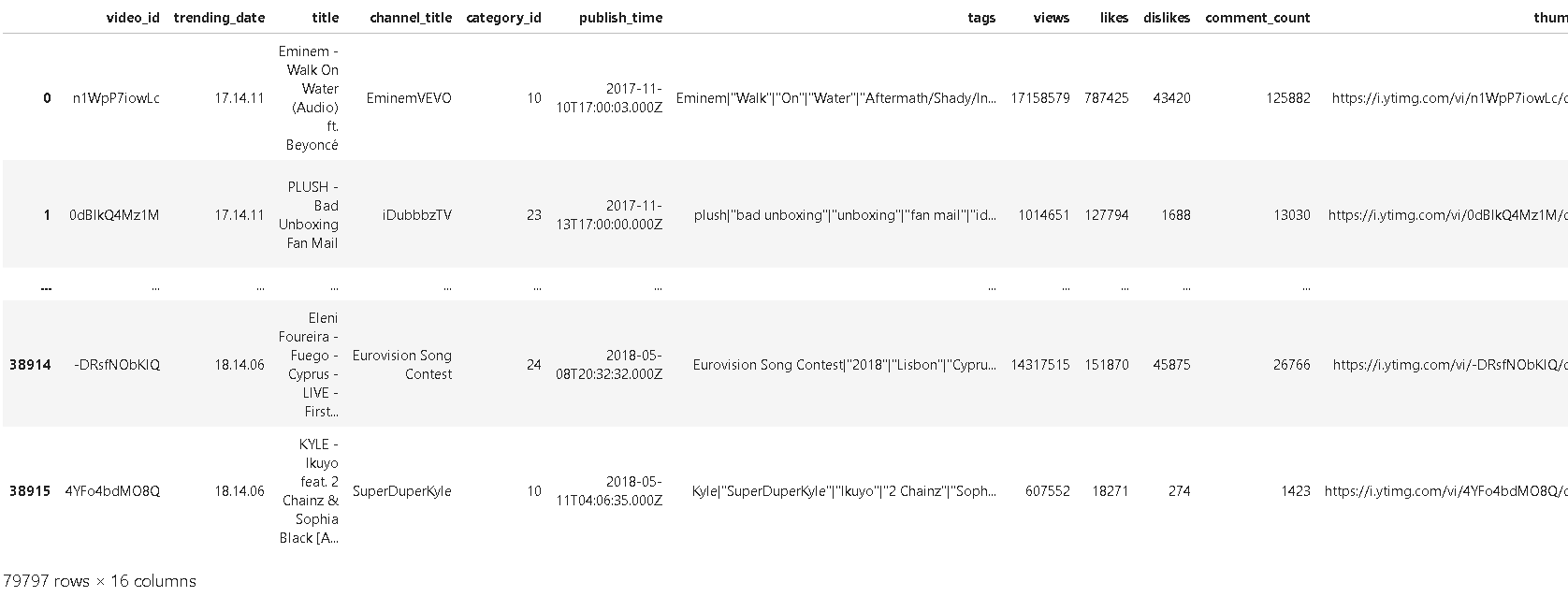
📍join()
- join() 메서드는 공통 인덱스를 가진 다른 DataFrame 객체를 결합할 수 있도록 해줍니다.
이를 통해 공유된 인덱스 값을 기준으로 데이터를 결합할 수 있습니다.
❗캐나다와 영국에서 동시에 트렌드에 올랐던 동영상을 가져올 때:
left = canadian_youtube.set_index(['title', 'trending_date'])
right = british_youtube.set_index(['title', 'trending_date'])
left.join(right, lsuffix='_CAN', rsuffix='_UK')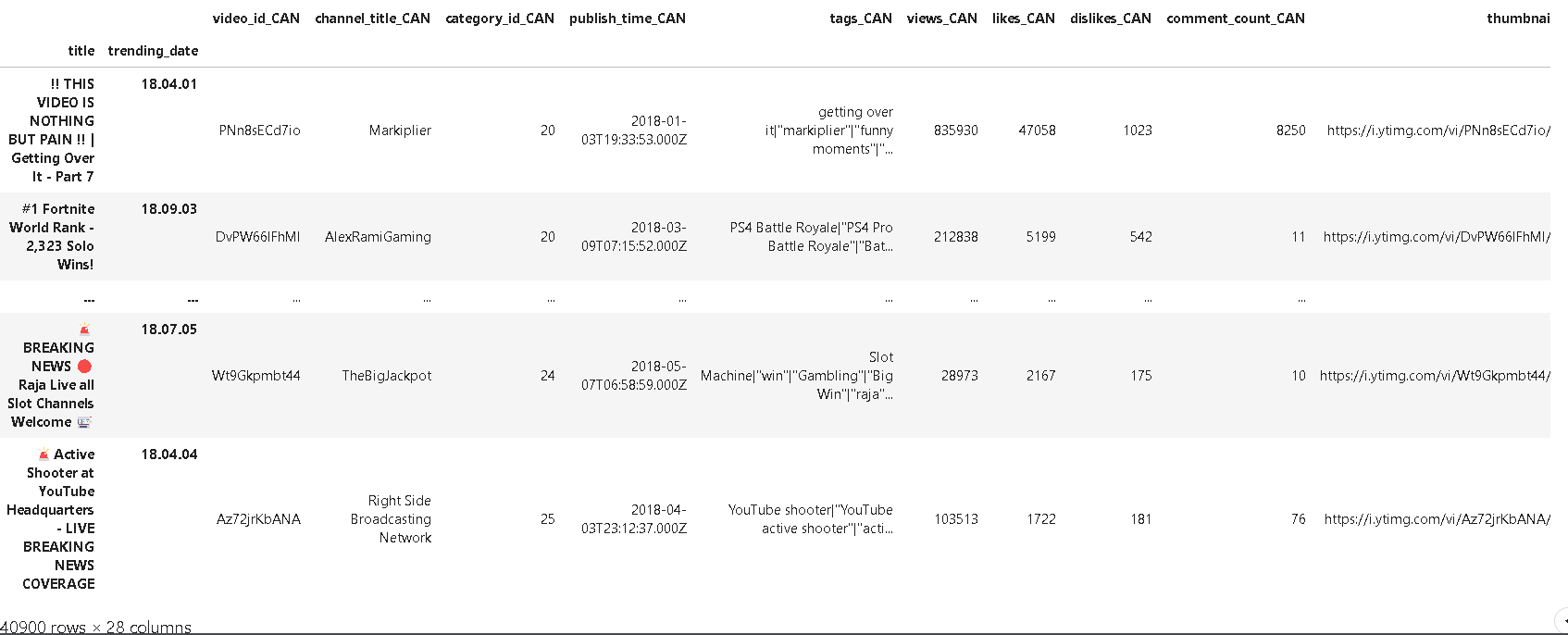
- 우리가 미리 이름을 변경했다면, 같은 컬럼 이름이 없기 때문에 접미사( lsuffix and rsuffix)들은 필요하지 않을 것입니다.
❗각 대회(MeetID)에 대한 정보와 해당 대회에 참가한 경기자들의 정보를 결합:
- 각 대회의 정보
powerlifting_meets = pd.read_csv("../input/powerlifting-database/meets.csv")
powerlifting_competitors = pd.read_csv("../input/powerlifting-database/openpowerlifting.csv")- Solution
powerlifting_combined = powerlifting_meets.set_index("MeetID").join(powerlifting_competitors.set_index("MeetID"))set_index() 함수를 사용하여 각각의 DataFrame의 인덱스를 "MeetID" 열로 설정한다.
join() 함수를 사용하여 두 DataFrame을 "MeetID"를 기준으로 조인한다.(조인은 공통된 인덱스 값을 기준으로 DataFrame을 병합하는 작업)결과적으로, powerlifting_combined 변수에는 "MeetID"를 인덱스로 가지고, powerlifting_meets DataFrame과 powerlifting_competitors DataFrame이 조인된 결과가 저장된다.
이를 통해 각 대회(MeetID)에 대한 정보와 해당 대회에 참가한 경기자들의 정보를 하나의 DataFrame으로 결합하여 사용할 수 있다.
