📢Data Types and Missing Values
데이터분석 : 1. 데이터 생성 및 읽기
데이터분석 : 2. 인덱싱, 선택 및 할당
데이터분석 : 3. 요약 기능 및 맵
데이터분석 : 4. 그룹화 및 정렬
데이터분석 : 5. 데이터 유형 및 결측값
데이터분석 : 6. 이름 변경 및 결합
📌1. 소개(Introduction)
- DataFrame 또는 Series 내에서 데이터 유형을 조사하는 방법을 배워보자!
- 또한 항목을 찾고 대체하는 방법을 배워보자!
❗pandas 사용( pd.read_csv(), index_col=0, pd.set_option())
import pandas as pd
reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)
pd.set_option('display.max_rows', 5)이전과 마찬가지로 Keggle데이터를 활용하여 실행하자.
📌2. 데이터 유형(Dtypes)
📍dtype
- DataFrame 또는 Series의 열에 대한 데이터 유형은 dtype으로 알수있다.
❗특정 열의 데이터 유형을 가져오기 위해 dtype 속성을 사용할 때:
reviews.price.dtypedtype('float64')
- reviews DataFrame의 price 열의 데이터 유형을 가져올 수 있습니다.
❗DataFrame의 모든 열의 데이터 유형을 반환할 때:
reviews.dtypescountry object
description object
...
variety object
winery object
Length: 13, dtype: object
- dtypes 속성을 사용하면 DataFrame의 모든 열의 데이터 유형을 반환할 수도 있습니다.
데이터 유형은 pandas가 데이터를 내부적으로 저장하는 방식에 대한 정보를 제공합니다.
float64는 64비트 부동 소수점 숫자를 사용한다는 것을 의미하며,
int64는 유사한 크기의 정수를 의미합니다.
그 외에도 다른 데이터 유형도 있습니다.
기억해야 할 하나의 특이한 점은 문자열로만 구성된 열은 자체 유형을 갖지 않고, 대신 object 유형을 갖습니다.
📍astype()
- astype() 함수를 사용하여 한 유형의 열을 다른 유형으로 변환한다.
❗points 열을 기존의 int64 데이터 유형에서 float64 데이터 유형으로 변환할 때:
reviews.points.astype('float64')0 87.0
1 87.0
...
129969 90.0
129970 90.0
Name: points, Length: 129971, dtype: float64
❗DataFrame 또는 Series의 인덱스도 자체 dtype을 가지고 있다.
reviews.index.dtypedtype('int64')
Pandas는 범주형 데이터와 시계열 데이터와 같은 더 특이한 데이터 유형도 지원한다.
그러나 이러한 데이터 유형은 덜 사용되므로 넘어가도록 하자.
📌3. 누락값(Missing data)
- 값이 누락된 항목은 NaN이라는 값으로 표시됩니다.
- NaN은 "Not a Number"의 약자로, 기술적인 이유로 인해 이러한 NaN 값은 항상 float64 dtype을 갖습니다.
📍pd.isnull()
- 🌈비어있는 행 확인
- Pandas는 누락된 데이터에 대한 특정 메서드를 제공한다.
- NaN 항목을 선택하려면 pd.isnull() (반대 : 이와 동반되는 pd.notnull())을 사용할 수 있다.
❗pd.isnull()을 사용하여 country의 누락값을 알아볼 때:
reviews[pd.isnull(reviews.country)]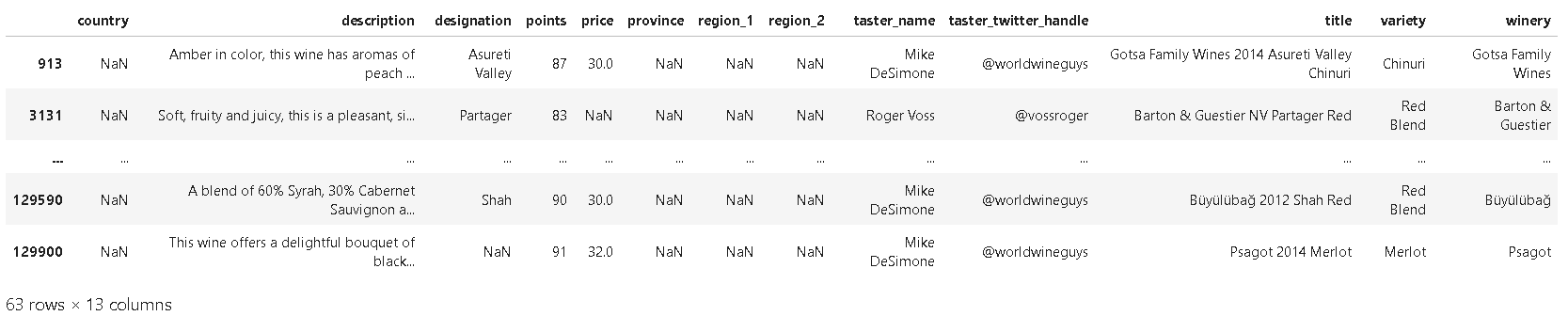
❗[예제]price의 누락값의 개수를 구해라
missing_price_reviews = reviews[reviews.price.isnull()]
n_missing_prices = len(missing_price_reviews)or
n_missing_prices = reviews.price.isnull().sum()or
n_missing_prices = pd.isnull(reviews.price).sum()📍fillna()
- 🌈NaN을 지정한 값으로 대체
- 누락된 값을 대체하는 것은 일반적인 작업이다.
- Pandas는 이 문제에 대한 매우 유용한 메서드인 fillna()를 제공합니다.
- fillna()는 이러한 데이터를 보완하기 위해 몇 가지 다른 전략을 제공하는데 그중 하나가 각 NaN 값을 "Unknown"으로 대체하는 것이다.
reviews.region_2.fillna("Unknown")0 Unknown
1 Unknown
...
129969 Unknown
129970 Unknown
Name: region_2, Length: 129971, dtype: object
❗[예제]리뷰 수가 가장 많은 지역부터 내림차순 정렬:
- 'region_1' 열에서 결측값을 'Unknown'으로 대체한다.
- 각 지역별 리뷰 수를 계산하고 내림차순으로 정렬하라.
reviews_per_region = reviews.region_1.fillna('Unknown').value_counts().sort_values(ascending=False)fillna() 함수를 사용하여 'region_1' 열의 결측값을 'Unknown'으로 대체한다.
value_counts() 함수를 사용하여 각 지역별로 리뷰 수를 계산한다.
(value_counts() 함수는 빈도수를 계산하여 시리즈로 반환하는 함수)
sort_values() 함수를 사용하여 리뷰 수를 기준으로 내림차순으로 정렬한다.
- 또는 데이터베이스에서 주어진 레코드 이후에 나타나는 첫 번째 비 null 값으로 각 누락된 값을 채울 수도 있습니다. 이를 backfill 전략이라고 합니다.
📍replace()
- 🌈도메인 값 대체
- 또는 대체하고자 하는 비 null 값을 가질 수도 있습니다.
예를 들어, 이 데이터셋이 게시된 이후에 리뷰어 Kerin O'Keefe가 트위터 핸들을 @kerinokeefe에서 @kerino로 변경한 경우 데이터셋에 이를 반영하는 한 가지 방법은 replace() 메서드를 사용하는 것이다.
reviews.taster_twitter_handle.replace("@kerinokeefe", "@kerino")0 @kerino
1 @vossroger
...
129969 @vossroger
129970 @vossroger
Name: taster_twitter_handle, Length: 129971, dtype: object
- replace() 메서드는 데이터셋에서 일종의 표식 값으로 제공되는 누락된 데이터를 대체하는 데 사용된다.
- 누락된 데이터는 "Unknown", "Undisclosed", "Invalid" 등으로 표시될 수 있다.
