
📢Grouping and Sorting
데이터분석 : 1. 데이터 생성 및 읽기
데이터분석 : 2. 인덱싱, 선택 및 할당
데이터분석 : 3. 요약 기능 및 맵
데이터분석 : 4. 그룹화 및 정렬
데이터분석 : 5. 데이터 유형 및 결측값
데이터분석 : 6. 이름 변경 및 결합
📌1. 소개(Introduction)
-
맵(Map)은 DataFrame이나 Series에서 한 번에 한 값씩 데이터를 변환할 수 있도록 해준다.
-
그러나 종종 데이터를 그룹화하고 해당 그룹에 대해 특정 작업을 수행하고 싶을 때가 있다.
SQL에서 처럼 말이다 -
이러한 작업을 groupby() 연산을 사용하여 수행한다.
-
또한 데이터프레임을 더 복잡하게 인덱싱하는 방법과 데이터를 정렬하는 방법을 배워보자
이전과 마찬가지로 Keggle데이터를 활용하여 실행하자.
import pandas as pd reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0) pd.set_option("display.max_rows", 5)
📌2. 그룹별 분석(Groupwise analysis)
- 지금까지 우리가 많이 사용한 함수 중 하나는 value_counts() 함수다.
- value_counts() 함수의 동작을 다음과 같이 재현할 수 있다.
📍groupby()
reviews.groupby('points').points.count()points
80 397
81 692
...
99 33
100 19
Name: points, Length: 21, dtype: int64
-
groupby() 함수는 동일한 점수를 할당한 와인에 대한 그룹을 생성한다.
그런 다음 각 그룹에 대해 points 열을 가져와서 해당 열이 얼마나 자주 나타나는지 계산한다. -
value_counts()는 이러한 groupby() 작업의 단축키에 불과하다.
-
이 데이터로 이전에 사용한 요약 함수를 사용할 수 있다.
❗각 점수 범주에서 가장 싼 와인을 얻으려 할 때:
reviews.groupby('points').price.min()points
80 5.0
81 5.0
...
99 44.0
100 80.0
Name: price, Length: 21, dtype: float64
- 우리가 생성하는 각 그룹은 값이 일치하는 데이터만 포함하는 DataFrame의 일부라고 생각할 수 있다.
- 이 DataFrame은 apply() 메서드를 사용하여 직접 접근할 수 있으며, 그런 다음 데이터를 우리가 원하는 방식으로 조작할 수 있습니다.
❗각 와이너리에서 리뷰한 첫 번째 와인의 이름을 선택할 때:
reviews.groupby('winery').apply(lambda df: df.title.iloc[0])winery
1+1=3 1+1=3 NV Rosé Sparkling (Cava)
10 Knots 10 Knots 2010 Viognier (Paso Robles)
...
àMaurice àMaurice 2013 Fred Estate Syrah (Walla Walla V...
Štoka Štoka 2009 Izbrani Teran (Kras)
Length: 16757, dtype: object
❗리뷰어별 평균 평점을 확인할 때:
- reviews DataFrame을 'taster_name' 열을 기준으로 그룹화한다.
- 각 그룹에서 'points' 열의 평균값을 계산하여 리뷰어별 평균 평점을 구하는 작업을 수행하라.
reviewer_mean_ratings = reviews.groupby('taster_name')['points'].mean()or
reviewer_mean_ratings = reviews.groupby('taster_name').points.mean()groupby() 함수를 사용하여 'taster_name' 열을 기준으로 DataFrame을 그룹화한다.
그리고 mean() 함수를 사용하여 각 그룹에서 'points' 열의 평균값을 계산한다.
이를 통해 각 리뷰어별로 평균 평점을 구할 수 있다.
- 더 세부적인 제어를 위해 두 개 이상의 열을 기준으로 그룹화할 수도 있다.
❗각 국가와 와인 품종의 조합별로 등장 횟수를 내림차순 정렬:
- reviews DataFrame을 'country'와 'variety' 열을 기준으로 그룹화한다
- 각 그룹의 크기를 계산하여 각 국가와 와인 품종의 조합별로 등장 횟수를 구하는 작업을 수행한다.
- 그리고 등장 횟수를 기준으로 내림차순으로 정렬하라.
country_variety_counts = reviews.groupby(['country', 'variety']).size().sort_values(ascending=False)groupby() 함수를 사용하여 'country'와 'variety' 열을 기준으로 DataFrame을 그룹화한다.
그리고 size() 함수를 사용하여 각 그룹의 크기, 즉 등장 횟수를 계산합니다.
이를 통해 각 국가와 와인 품종의 조합별로 등장 횟수를 얻을 수 있습니다.
마지막으로, sort_values(ascending=False)함수를 사용하여 등장 횟수를 기준으로 내림차순으로 정렬합니다.
📍idxmax()
- 🌈max()는 최대값을 구하고, idxmax()는 최대값의 인덱스를 구한다.
❗국가와 지방별로 최고의 와인을 선택할 때:
reviews.groupby(['country', 'province']).apply(lambda df: df.loc[df.points.idxmax()])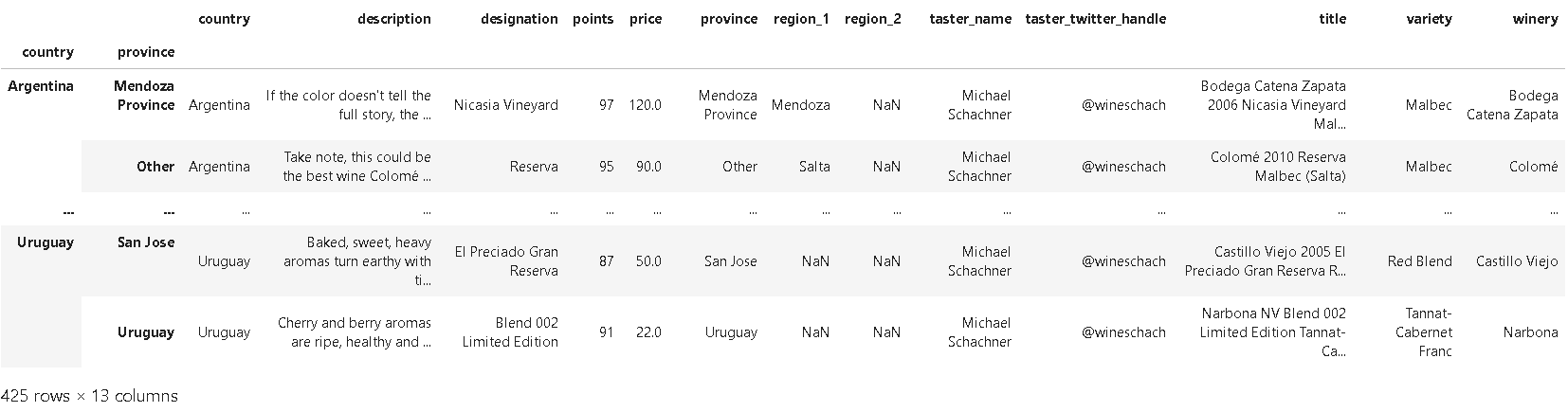
📍agg()
- 언급할 가치가 있는 또 다른 groupby() 메서드는 agg()이다.
- agg() 메서드를 사용하면 DataFrame에 여러 가지 다른 함수를 동시에 실행할 수 있다.
❗데이터셋의 간단한 통계 요약을 생성할 떄:
reviews.groupby(['country']).price.agg([len, min, max])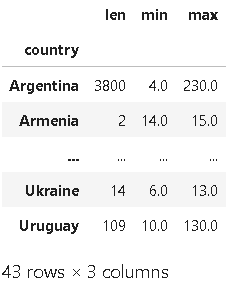
❗각 와인 품종의 가격 범위:
- reviews DataFrame을 'variety' 열을 기준으로 그룹화한다.
- 각 그룹에서 'price' 열의 최소값과 최대값을 계산하는 작업을 수행한다.
price_extremes = reviews.groupby(['variety').price.agg([min, max])groupby() 함수를 사용하여 'variety' 열을 기준으로 DataFrame을 그룹화한다.
agg() 함수를 사용하여 각 그룹에서 'price' 열의 최소값과 최대값을 계산합니다. agg() 함수의 인자로는 계산하려는 통계 함수들을 전달합니다. 여기서는 최소값과 최대값을 계산하기 위해 min과 max 함수를 사용합니다.
❗최소 가격과 최대 가격에 따라 정렬된 와인 품종을 확인:
- 'price_extremes' DataFrame을 기준으로 'min' 열과 'max' 열을 내림차순으로 정렬하여 와인 품종을 정렬한다.
- 그 결과를 sorted_varieties 변수에 한다.
sorted_varieties = price_extremes.sort_values(by=['min', 'max'], ascending=False)groupby()를 효과적으로 사용하면 데이터셋에서 다양하고 효율적인 작업을 수행할 수 있다.
📌3. 다중 인덱스(Multi-indexes)
- 지금까지는 단일 레이블 인덱스를 가진 DataFrame 또는 Series 객체를 다루었다.
- 그러나 groupby()는 우리가 실행하는 작업에 따라 때에 따라 multi-index라고 불리는 것으로 결과가 나타난다.
📍Multi-index
- Multi-index는 일반적인 인덱스와 다른 점이 여러 수준을 가지고 있다.
countries_reviewed = reviews.groupby(['country', 'province']).description.agg([len])
countries_reviewed
mi = countries_reviewed.index
type(mi)pandas.core.indexes.multi.MultiIndex
- 다중 인덱스는 단일 수준 인덱스에는 없는 계층 구조를 다루기 위한 여러 메서드를 가지고 있다.
- 또한 값을 검색하기 위해서는 두 수준의 레이블이 필요하다.
📍reset_index()
- 일반 인덱스로 변환하는 reset_index() 메서드
countries_reviewed.reset_index()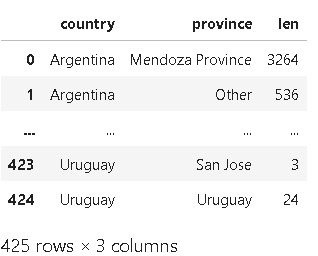
📌4. 분류(Sorting)
- 다시 countries_reviewed를 살펴보면, 그룹화된 결과는 데이터의 값 순서가 아니라 인덱스 순서에 따라 반환된다.
- 즉, groupby의 결과를 출력할 때 행의 순서는 데이터의 값이 아니라 인덱스의 값에 따라 결정된다.
📍sort_values()
- 원하는 순서로 데이터를 얻으려면 직접 정렬해야 한다. 이를 위해 sort_values() 메서드가 유용합니다.
❗오름차순 정렬할 때:
countries_reviewed = countries_reviewed.reset_index()
countries_reviewed.sort_values(by='len')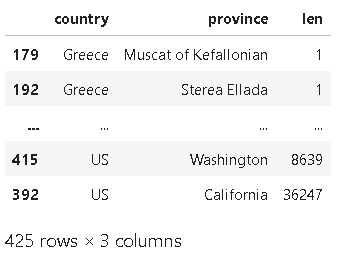
- sort_values() 메서드는 기본적으로 오름차순 정렬을 수행하며, 가장 작은 값이 먼저 나타난다.
- 그러나 대부분의 경우 우리는 내림차순 정렬을 원한다.
- 즉, 더 큰 숫자가 먼저 나타나도록 정렬해야한다.
❗내림차순 정렬할 때:
countries_reviewed.sort_values(by='len', ascending=False)
❗한번에 여러 열을 기준으로 정렬할 때:
- 먼저 country로 정렬한 후 그 안에서 len으로 정렬한다.
countries_reviewed.sort_values(by=['country', 'len'])
❗가장 비싼 와인 품종은 무엇일까:
📍 sort_index()
- 값을 정렬하려면 sort_index() 메서드를 사용(기본 : 인덱스 값을 기준)
- 이 메서드는 동일한 인자와 기본 정렬 순서를 가지고 있습니다.
countries_reviewed.sort_index()
- 마지막으로, 한 번에 여러 열을 기준으로 정렬할 수 있다.
❗특정 금액으로 구매할 수 있는 가장 좋은 와인:
- 가격을 인덱스로 가지고, 해당 가격에 해당하는 와인이 받은 최고 포인트를 값으로 가지는 Series를 생성합니다.
- Series를 가격을 기준으로 오름차순으로 정렬합니다.
best_rating_per_price = reviews.groupby('price')['points'].max().sort_index()reviews DataFrame을 'price' 열을 기준으로 그룹화하고, 각 그룹에서 'points' 열의 최대값을 계산한다. 그리고 sort_index() 함수를 사용하여 가격을 기준으로 Series를 오름차순으로 정렬한다.
