
📢Summary Functions and Maps
데이터분석 : 1. 데이터 생성 및 읽기
데이터분석 : 2. 인덱싱, 선택 및 할당
데이터분석 : 3. 요약 기능 및 맵
데이터분석 : 4. 그룹화 및 정렬
데이터분석 : 5. 데이터 유형 및 결측값
데이터분석 : 6. 이름 변경 및 결합
📌1. 소개(Introduction)
- 작업에 맞게 데이터를 형식화하기 위해 고급 작업을 수행해야 한다.
이번에는 데이터를 "딱 맞게" 가져오기 위해 적용할 수 있는 다양한 작업에 대해 알아보자!
import pandas as pd //pandas를 활용한 데이터 작업
pd.set_option('display.max_rows', 5) //나타내지는 줄 수 5줄
import numpy as np //numpy함수 사용
reviews = pd.read_csv("../input/wine-reviews/winemag-data-130k-v2.csv", index_col=0)이전에 사용했던 Keggle의 데이터를 사용하여 분석해보자!
📌2. 요약(Summary functions)
- Pandas는 데이터를 유용한 방식으로 재구성하는 많은 간단한 요약을 위한 함수를 제공한다.
📍describe()
- 🌈행의 개수
- describe() 메서드는 주어진 열의 속성에 대한 요약을 생성한다.
- describe() 메서드는 데이터 유형에 따라 출력이 변경되므로 유형에 대해 알아볼 수 있다.
❗숫자형 데이터 요약:
reviews.points.describe()count 129971.000000
mean 88.447138
...
75% 91.000000
max 100.000000
Name: points, Length: 8, dtype: float64
- 위의 출력은 숫자 데이터에 대해서만 의미가 있다.
❗문자열 데이터 요약:
reviews.taster_name.describe()count 103727
unique 19
top Roger Voss
freq 25514
Name: taster_name, dtype: object
📍mean()
- 🌈평균 계산
- DataFrame이나 Series에서 열에 대한 특정 요약 통계(평균)를 얻고 싶다면, mean()를 이용한다.
- 할당된 점수의 평균을 확인하려면 (즉, 평균적으로 얼마나 잘 평가된 와인인지) mean() 함수를 사용할 수 있다.
reviews.points.mean()88.44713820775404
❗점수 열을 다시 조정하는 방법 :
review_points_mean = reviews.points.mean()
reviews.points - review_points_mean0 -1.447138
1 -1.447138
...
129969 1.552862
129970 1.552862
Name: points, Length: 129971, dtype: float64
- 위의 코드에서는 왼쪽(시리즈 내의 모든 값)과 오른쪽(평균 값) 사이에서 많은 값을 대상으로 작업을 수행한다.
- Pandas는 이 식을 살펴보고 데이터셋의 모든 값에서 해당 평균 값을 빼는 것을 의도한 것으로 이해한다.
❗가격 열을 다시 조정하는 방법:
centered_price = reviews.price - reviews.price.mean()📍unique()
- 🌈중복없는 고유값
- 고유한 값의 목록을 보려면 unique() 함수를 사용할 수 있다.
- (중복 제외)
reviews.taster_name.unique()array(['Kerin O’Keefe', 'Roger Voss', 'Paul Gregutt',
'Alexander Peartree', 'Michael Schachner', 'Anna Lee C. Iijima',
'Virginie Boone', 'Matt Kettmann', nan, 'Sean P. Sullivan',
'Jim Gordon', 'Joe Czerwinski', 'Anne Krebiehl\xa0MW',
'Lauren Buzzeo', 'Mike DeSimone', 'Jeff Jenssen',
'Susan Kostrzewa', 'Carrie Dykes', 'Fiona Adams',
'Christina Pickard'], dtype=object)
❗unique() 예시
- 데이터셋에는 어떤 국가들이 포함되어 있는지 확인해보자. (중복 제외)
countries =reviews.aggcountry.unique()📍value_counts()
- 🌈빈도수 확인
- 데이터셋에서 고유한 값의 목록과 해당 값들이 얼마나 자주 나타나는지를 확인하려면 value_counts() 메서드를 사용할 수 있다.
reviews.taster_name.value_counts()Roger Voss 25514
Michael Schachner 15134
...
Fiona Adams 27
Christina Pickard 6
Name: taster_name, Length: 19, dtype: int64
📌3. 맵(Maps)
-
맵(Map)은 수학에서 가져온 용어로, 하나의 값 집합을 다른 값 집합으로 "매핑"하는 함수를 의미한다.
-
데이터 과학에서는 종종 기존 데이터에서 새로운 표현을 생성하거나 데이터를 현재 형식에서 나중에 원하는 형식으로 변환해야 할 필요가 있는데 맵(Map)은 이 작업을 처리하는데 사용되며, 작업을 수행하는 데 매우 중요하다.
-
두 가지 자주 사용하는 매핑 메서드가 있다.
📍map()
- 🌈수정된 데이터 값으로 새로운 시리즈로 만듦
- 첫 번째로, map() 메서드가 있다.
- map()은 함수에 의해 변환된 모든 값을 포함하는 새로운 Series를 반환하게 된다.
❗[예시]와인이 받은 점수(points) - 평균(points.mean())을 할 때:
review_points_mean = reviews.points.mean() #<-평균값
reviews.points.map(lambda p: p - review_points_mean) #P-평균값0 -1.447138
1 -1.447138
...
129969 1.552862
129970 1.552862
Name: points, Length: 129971, dtype: float64
- map() 메서드에 전달하는 함수는 Series에서 하나의 값(위의 예시에서는 점수 값)을 기대하고, 해당 값을 변환한 버전을 반환해야 한다.
📍lambda 함수
- 🌈전달 함수
- 람다(lambda) 함수는 익명 함수로서 한 줄로 간결하게 정의될 수 있는 함수이다. 일반적인 함수와 달리 이름이 없으며, 주로 간단한 연산을 수행하거나 다른 함수의 인자로 전달되는 함수로 사용된다.
lambda arguments: expression❗[예시]람다를 이용한 빈도수 찾기 - 와인 병을 설명할 때 사용할 수 있는 단어는 제한되어 있습니다. 와인이 "tropical"이나 "fruity" 중 어떤 것이 더 많이 나왔을까?:
n_trop = reviews.description.map(lambda desc: "tropical" in desc).sum()
n_fruity = reviews.description.map(lambda desc: "fruity" in desc).sum()
descriptor_counts = pd.Series([n_trop, n_fruity], index=['tropical', 'fruity'])어지러워진 나의 머리를 대신해 해석을 돕기위해 GPT의 힘을 빌렸다.
위의 코드는 reviews DataFrame의 description 열에서 "tropical"과 "fruity"가 등장하는 횟수를 세는 작업을 수행하는 예시입니다.
첫 번째 줄에서는 map() 함수와 람다(lambda) 함수를 사용하여 각 description 값을 확인하고, 해당 문자열에 "tropical"이 포함되어 있는지 여부를 판별합니다. 그리고 이 결과를 True(포함) 또는 False(미포함)로 반환합니다. 그리고 sum() 함수를 사용하여 True인 경우의 개수를 계산합니다. 이를 n_trop 변수에 할당합니다.
두 번째 줄에서도 마찬가지로 map() 함수와 람다 함수를 사용하여 각 description 값을 확인하고, 해당 문자열에 "fruity"가 포함되어 있는지 여부를 판별합니다. 그리고 sum() 함수를 사용하여 True인 경우의 개수를 계산합니다. 이를 n_fruity 변수에 할당합니다.
세 번째 줄에서는 pd.Series()를 사용하여 n_trop와 n_fruity 값을 가지는 Series를 생성합니다. 인덱스로는 'tropical'과 'fruity'를 사용합니다.
따라서, descriptor_counts Series에는 'tropical'과 'fruity'가 reviews DataFrame의 description 열에서 각각 얼마나 자주 등장하는지가 저장됩니다.
📍apply()
- 🌈수정된 데이터 값이 들어있는 데이터프레임으로 변환
- 두번째로, apply()는 각 행에 사용자 정의 메서드를 호출하여 전체 DataFrame을 변환하고자 할 때 사용되는 등가 메서드이다.
def remean_points(row):
row.points = row.points - review_points_mean
return row
reviews.apply(remean_points, axis='columns')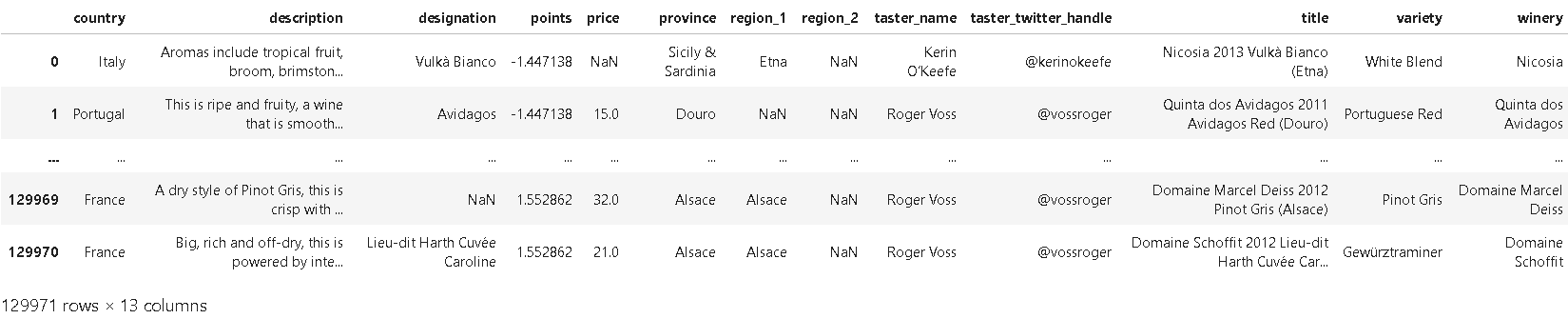
-
만약 reviews.apply()에 axis='index'를 사용했다면, 각 행을 변환하는 함수 대신 각 열을 변환하는 함수를 제공해야 한다.
(🌈axis='columns' : 열에 값 넣기, 🌈axis='index' : 행에 값 넣기) -
참고로, map()과 apply()는 각각 새로운 변환된 Series와 DataFrame을 반환합니다.
-
이들은 호출된 원본 데이터를 수정하지 않는다.
(🌈출력시에만 변환하여 출력하고, 원본값은 바뀌지 않는다.) -
reviews의 첫 번째 행을 살펴보면 원래의 점수 값이 그대로 유지되고 있다.
reviews.head(1)
❗apply 예시
이 와인 리뷰를 웹사이트에 게시하려고 합니다.
하지만 80부터 100까지의 포인트 범위로 된 평가 시스템은 이해하기 어렵습니다.
간단한 별점 평가로 바꾸고자 합니다.
95 이상의 점수는 3개의 별, 85 이상 95 미만의 점수는 2개의 별로 취급하고, 나머지 모든 점수는 1개의 별로 취급하려고 합니다.또한, 캐나다 와인 제조자 협회가 사이트에 많은 광고를 구매했으므로, 캐나다의 모든 와인은 점수와 상관없이 자동으로 3개의 별을 받아야 합니다.
다음과 같이 데이터셋의 각 리뷰에 해당하는 별점 개수를 나타내는 star_ratings Series를 생성합니다.
- axis='columns'사용
def stars(row): if row.country == 'Canada': return 3 elif row.points >= 95: return 3 elif row.points >= 85: return 2 else: return 1
star_ratings = reviews.apply(stars, axis='columns')
- apply() 함수는 DataFrame의 행 또는 열에 함수를 적용하는 메서드이다.
- 여기서는 **axis='columns'**를 사용하여 각 행에 함수를 적용하고, 그 결과를 star_ratings 변수에 할당하도록 한다.
### 📍idxmax()
- 🌈**최대값**
- **idxmax()**는 pandas Series나 DataFrame에서 **최대값**을 가지는 인덱스를 반환하는 함수이다.
#### ❗"최고의 가성비" 와인, 즉 데이터셋에서 포인트 대비 가격 비율이 가장 높은 와인을 찾기 위해 다음과 같이 bargain_wine 변수를 생성:bargain_idx = (reviews.points / reviews.price).idxmax()
bargain_wine = reviews.loc[bargain_idx, 'title']
>- 각 와인에 대해 'points' 열을 'price' 열로 나누어 포인트 대비 가격 비율을 계산
- idxmax() 메서드를 사용하여 최대 비율 값에 해당하는 인덱스를 찾는다.
- .loc[] 인덱싱을 사용하여 최고 비율을 가진 와인의 'title' 열에 접근
### 📍median()
- 🌈**중간값**
- 열의 중간값(median)을 구하는 함수이다.median_points = reviews.points.median()
ormedian_points = reviews['points'].median()
#### ❗데이터셋에서 국가와 지역 정보를 결합하는 간단한 방법
- Pandas는 또한 길이가 동일한 Series 간에 이러한 작업을 수행할 때 어떻게 처리해야 하는지 이해한다.reviews.country + " - " + reviews.region_1
>0 Italy - Etna
1 NaN
...
129969 France - Alsace
129970 France - Alsace
Length: 129971, dtype: object
- 이러한 연산자들은 pandas에 내장된 속도 향상 기능을 사용하기 때문에** map()**이나 **apply()**보다 빠르다.
- 모든 표준 Python 연산자(>, <, == 등)는 이러한 방식으로 작동한다.
>그러나, 이들은 **map()**이나 **apply()**만큼 유연하지 않다.
**map()**이나 **apply()**는 조건부 논리를 적용하는 등 더 고급 기능을 수행할 수 있는 반면, 덧셈과 뺄셈만으로는 수행할 수 없는 작업이다.