
📢Indexing, Selecting & Assigning
데이터분석 : 1. 데이터 생성 및 읽기
데이터분석 : 2. 인덱싱, 선택 및 할당
데이터분석 : 3. 요약 기능 및 맵
데이터분석 : 4. 그룹화 및 정렬
데이터분석 : 5. 데이터 유형 및 결측값
데이터분석 : 6. 이름 변경 및 결합
📌1. 소개
- 'DataFrame' 또는 'Series'에서 특정 값들을 선택하여 작업하는 것은 거의 모든 데이터 작업에서 암묵적으로 수행되는 단계이므로, 파이썬에서 데이터를 다루는 작업을 시작할 때 가장 먼저 알아야 할 것은 빠르고 효과적으로 관련 데이터 포인트를 선택하는 방법 일 것이다.
📌2. 데이터 인덱싱
- Python 객체는 데이터를 인덱싱하는 좋은 방법을 제공하고, Pandas는 이러한 방법을 모두 지원하여 시작하기 쉽게 만들어주기 때문에 pandas를 사용하여 진행했다.
객체의 속성에 접근하기
❗속성 접근하기 1
reviews.country0 Italy
1 Portugal
...
129969 France
129970 France
Name: country, Length: 129971, dtype: object
❗속성 접근하기 2
reviews['country']0 Italy
1 Portugal
...
129969 France
129970 France
Name: country, Length: 129971, dtype: object
-
이 두 가지 방법은 DataFrame에서 특정 Series를 선택하는 방법이다.
어느 방법이 문법적으로 더 유효하거나 유효하지 않은 것은 아니지만, 인덱싱 연산자 []는 예약된 문자가 포함된 열 이름을 처리할 수 있는 장점이 있다. -
단일 특정 값을 찾기 위해 인덱싱 연산자 []를 한 번 더 사용할 수 있다.
reviews['country'][0]'Italy'
📌3. 데이터 선택
- 인덱싱 연산자와 속성 선택은 파이썬과 유사하다. 그러나 Pandas는 'loc'와 'iloc'라는 고유한 접근자 연산자를 가지고 있다. 더 고급 작업을 수행할 때는 이러한 접근자를 사용해야 한다.
📝1. 인덱스 기반 선택
- Pandas의 인덱싱은 두 가지이다.
- 첫 번째는 인덱스 기반 선택으로, 데이터의 숫자적 위치를 기반으로 데이터를 선택합니다.
- iloc는 이러한 패러다임을 따른다.
📍iloc
❗첫 번째 행 선택 :
reviews.iloc[0]country Italy
description Aromas include tropical fruit, broom, brimston...
...
variety White Blend
winery Nicosia
Name: 0, Length: 13, dtype: object
- loc와 iloc 모두 행을 먼저 선택하고 열을 나중에 선택한다. 이는 기본적으로 파이썬과는 반대이다. 파이썬은 열을 먼저 선택하고 행을 나중에 선택하기 때문이다.
❗iloc를 사용하여 열선택 :
reviews.iloc[:, 0]0 Italy
1 Portugal
...
129969 France
129970 France
Name: country, Length: 129971, dtype: object
- ':' 연산자는 파이썬에서도 쓰인다. 단독으로 사용할 때 "모든 것"을 의미한다. 그러나 다른 선택기와 함께 사용될 때는 값의 범위를 나타내는 데 사용된다.
❗첫 번째, 두 번째 및 세 번째 행에서 country 열을 선택 :
- ver1
reviews.iloc[:3, 0]0 Italy
1 Portugal
2 US
Name: country, dtype: object
- ver2
reviews.iloc[1:3, 0]1 Portugal
2 US
Name: country, dtype: object
- ver3
reviews.iloc[[0, 1, 2], 0]0 Italy
1 Portugal
2 US
Name: country, dtype: object
- 마지막으로, 선택에 음수를 사용할 수 있다.
❗마지막 5개 선택
reviews.iloc[-5:]
📝2. 레이블 기반 선택
레이블 기반 선택은 속성 선택의 두 번째 패러다임이다.
이 패러다임에서는 위치가 아닌 데이터 인덱스 값이 중요합니다.
📍loc
❗첫번쨰 항목 가져오기:
reviews.loc[0, 'country']'Italy'
- iloc은 개념적으로 loc보다 간단한데, iloc은 데이터 세트의 인덱스를 무시하기 때문이다.
- iloc을 사용하면 데이터 세트를 큰 행렬(리스트의 리스트)처럼 취급하며, 위치에 따라 인덱싱해야 한다.
- loc은 반대로 인덱스의 정보를 사용하여 작업을 수행합니다.
- 대부분의 데이터 세트는 의미 있는 인덱스를 가지고 있기 때문에 loc을 사용하면 일반적으로 작업이 더 쉬워진다.
❗loc을 사용하면 더 쉬운 작업:
reviews.loc[:, ['taster_name', 'taster_twitter_handle', 'points']]
📍'loc', 'iloc' 특징
- loc과 iloc을 선택하거나 전환할 때는 알아두어야 할 포인트가 있다. 바로 두 가지 메서드가 약간 다른 인덱싱 방식을 사용한다는 점이다.
- iloc은 Python 표준 라이브러리 인덱싱 방식을 사용한다. 범위의 첫 번째 요소는 포함되고 마지막 요소는 제외된다. 따라서 0:10은 0부터 9까지의 항목을 선택한다.
-
반면 loc은 포함적으로 인덱싱한다. 따라서 0:10은 0부터 10까지의 항목을 선택한다.
-
이는 데이터프레임의 인덱스가 간단한 숫자 리스트인 경우에 특히 혼동을 줄 수 있다. 예를 들어 0,...,1000인 경우 df.iloc[0:1000]은 1000개의 항목을 반환하고, df.loc[0:1000]은 그 중 1001개를 반환한다.
-
loc을 사용하여 1000개의 요소를 가져오려면 하나 낮게 가서 df.loc[0:999]와 같이 요청해야 합니다.
- df.iloc[0:1000] 0~999 1000개 반환.
-
df.loc[0:1000] 0~1000 1001개 반환한다.
-
그렇지 않은 경우에는 loc을 사용하는 의미론적 측면은 iloc을 사용하는 경우와 동일합니다.
📌4. 인덱스 조건
- 라벨 기반 선택은 인덱스의 라벨로부터 파생된 기능을 제공한다.
- 중요한 점은 사용하는 인덱스가 불변적이지 않다는 것이다.
- 우리는 인덱스를 원하는 대로 조작할 수 있다.
📍set_index()
- set_index() 메서드를 사용하여 작업을 수행할 수 있다.
❗"title" 필드를 인덱스로 설정하는 경우:
reviews.set_index("title")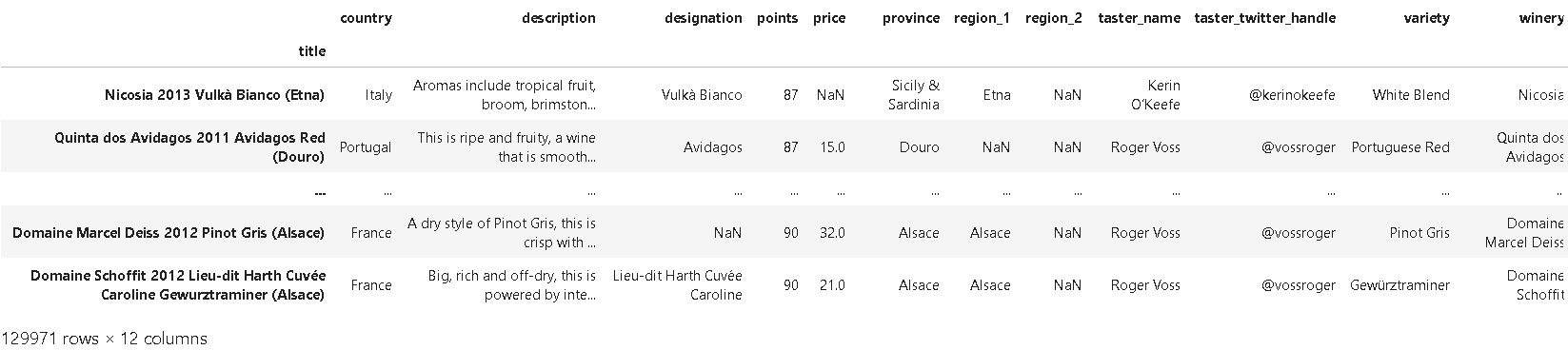
📝조건을 이용한 선택
지금까지는 데이터프레임의 구조적 속성을 사용하여 데이터의 다양한 부분을 인덱싱해왔다.
그러나 데이터를 활용하여 더 고급의 작업을 수행하려면 그에 맞는 조건을 부여해야한다.
예를 들어, 우리가 특히 이탈리아에서 생산된 평균보다 좋은 와인에 관심이 있다면,
❗1. 와인이 이탈리아산인지 여부 확인:
reviews.country == 'Italy'0 True
1 False
...
129969 False
129970 False
Name: country, Length: 129971, dtype: bool
- 이 연산은 각 레코드의 국가에 기반하여 True/False 값을 가진 Series를 생성한다.
❗2. loc를 사용하여 관련 데이터 선택
reviews.loc[reviews.country == 'Italy']
이 DataFrame은 약 20,000개의 행을 가지고 있고, 원본 데이터셋은 약 130,000개의 행을 가지고 있었으므로 이는 와인 중 약 15%가 이탈리아에서 생산된 것을 의미한다.
또한, 우리는 평균 이상의 와인을 알고 싶었다.
와인은 80에서 100점의 점수 체계로 평가되기 때문에, 이는 적어도 90점 이상을 받은 와인을 의미한다고 볼 수 있다.
📍ampersand (&)
이 두 가지 질문을 함께 결합하기 위해 ampersand (&)를 사용할 수 있다.
reviews.loc[(reviews.country == 'Italy') & (reviews.points >= 90)]
reviews.loc[(reviews.country == 'Italy') | (reviews.points >= 90)]
📍isin()
isin() 메서드는 주어진 리스트의 값에 해당하는 데이터를 선택하는 데 사용된다.
예를 들어, 이 코드는 이탈리아나 프랑스에서 생산된 와인만 선택하는 방법을 보여준다.
'country' 열의 값이 'Italy' 또는 'France'에 속하는 경우에만 선택된다.
reviews.loc[reviews.country.isin(['Italy', 'France'])]
📍isnull()
isnull() 메서드는 값이 비어 있거나 NaN(숫자가 아님)인 경우 해당 값을 선택하는 데 사용된다.
❗데이터셋에서 가격 정보가 없는 와인을 필터링하기 위해 'price' 열에 isnull() 사용
reviews.loc[reviews.price.notnull()]
📌5. 데이터 할당
- 상수 값을 할당하거나 다른 열의 값을 할당할 수 있다.
❗상수 값 할당
reviews['critic'] = 'everyone'
reviews['critic']0 everyone
1 everyone
...
129969 everyone
129970 everyone
Name: critic, Length: 129971, dtype: object
or
reviews['index_backwards'] = range(len(reviews), 0, -1)
reviews['index_backwards']0 129971
1 129970
...
129969 2
129970 1
Name: index_backwards, Length: 129971, dtype: int64
