📢Data Creating, Reading
데이터분석 : 1. 데이터 생성 및 읽기
데이터분석 : 2. 인덱싱, 선택 및 할당
데이터분석 : 3. 요약 기능 및 맵
데이터분석 : 4. 그룹화 및 정렬
데이터분석 : 5. 데이터 유형 및 결측값
데이터분석 : 6. 이름 변경 및 결합
📌1. 소개(Introduction)
-
데이터 분석을 위한 Python 라이브러리인 pandas에 대해 배워보자.
-
직접 데이터를 생성하는 방법과 이미 존재하는 데이터를 다루는 방법에 대해 배워보자
-Pandas는 Python에서 데이터 조작과 분석을 위한 강력한 라이브러리다. DataFrame이라는 데이터 구조를 제공한다.
-Pandas는 데이터를 구조화하고 처리하는 데 특화된 기능을 제공하여 데이터 분석 작업을 더 효율적으로 수행할 수 있도록 도와준다.
-Pandas는 데이터 과학 및 데이터 분석 커뮤니티에서 널리 사용되며, 데이터 전처리, 탐색적 데이터 분석, 통계 분석, 기계 학습 등 다양한 분야에서 활용된다. Pandas의 강력한 기능과 사용자 친화적인 인터페이스는 데이터 작업의 생산성을 향상시키는 데 도움을 준다.
📌2. 시작하기(Getting started)
📝Pandas
- Pandas를 사용하기 위해서, 코드를 사용해야한다.
import pandas as pdPansdas에는 두 가지 핵심 객체가 있는데 이는 'DataFrame'과 'Series'이다.
쉽게 말하면, Series는 1차원 데이터, DataFrame은 2차원 데이터라고 생각하면 된다.
이를 알아보자!
📌3. 생성(Creating data)
📚1. 데이터프레임
- DataFrame은 테이블이다. 각각의 엔트리(entry)는 특정 값을 가지고 있고, 각 엔트리는 행(또는 레코드)과 열에 해당한다.
📍pd.DataFrame()
❗간단한 DataFrame:
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']})
-
DataFrame 객체를 생성하기 위해 pd.DataFrame() 생성자를 사용한다.
-
새로운 DataFrame을 선언하기 위한 구문은 열 이름을 '키'로, 엔트리의 리스트를 값으로 하는 '딕셔너리'이다.
-
이는 새로운 DataFrame을 생성하는 표준적인 방법이며, 가장 일반적으로 사용되는 방법이다.
-
딕셔너리-리스트 생성자는 열 레이블에 값을 할당하지만, 행 레이블에는 0부터 시작하는 연속된 숫자(0, 1, 2, 3, ...)를 사용합니다. 때로는 이렇게 자동으로 할당되는 값이 적절하지만, 우리가 직접 레이블을 할당하고자 할 때도 있다.
❗생성자의 index 매개변수를 사용하여 값을 할당:
pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'],
'Sue': ['Pretty good.', 'Bland.']},
index=['Product A', 'Product B'])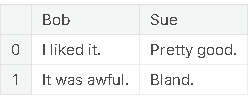
❗📝2. 데이터프레임 응용
❗Pandas 데이터프레임 만들기 ver1
index=['2018', '2019','2020','2021']
YH = pd.Series([143, 150, 157, 160], index=index)
CS = pd.Series([165, 172, 180, 190],index=index)
growth = pd.DataFrame({
'영희' : YH,
'철수' : CS
})
growth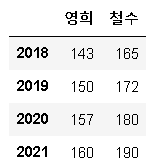
❗Pandas 데이터프레임 만들기 ver2
index=['2018', '2019','2020','2021']
data = {
'영희' :[143, 150, 157, 160],
'철수' :[165, 172, 180, 190]
}
growth = pd.DataFrame(data,columns=['영희','철수'],index=index )
growth❗데이터타입 출력
growth.dtypes❗데이터타입 실수화
growth.astype('float')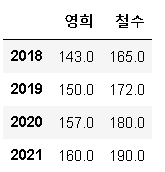
❗사용을 위해 담아두기
growth_float = growth.astype('float') - 나중에도 사용할것이라면 담아둬야한다.
❗특정 컬럼만 바꾸기
growth_float = growth.astype({'영희' : 'float'}) ❗📝3. 다양한 데이터 선택
'영희'의 성장 데이터만 선택
yh_growth = growth['영희']
print(yh_growth)'철수'의 성장 데이터만 선택
cs_growth = growth['철수']
print(cs_growth)'2020'년도의 성장 데이터 선택
row_2020 = growth.loc['2020']
print(row_2020)'민지'의 성장 데이터 추가
mj_growth = pd.Series([155, 162, 170, 175], index=index)
growth['민지'] = mj_growth
print(growth)각 열의 평균 계산
column_means = growth.mean()
print(column_means)각 행의 합계 계산
row_sums = growth.sum(axis=1)
print(row_sums)
📚4. 시리즈
- Series는 데이터 값의 시퀀스이다.
- DataFrame이 '테이블'이라면, Series는 '리스트'이다.
📍pd.Series()
❗리스트로 Series 생성:
pd.Series([1, 2, 3, 4, 5])0 1
1 2
2 3
3 4
4 5
dtype: int64
- Series는 본질적으로 DataFrame의 단일 열이다. 따라서 이전과 마찬가지로 index 매개변수를 사용하여 Series에 행 레이블을 할당할 수 있다. 그러나 Series에는 열 이름이 없고, 전체적으로 하나의 이름만 가지고 있다.
pd.Series([30, 35, 40], index=['2015 Sales', '2016 Sales', '2017 Sales'], name='Product A')2015 Sales 30
2016 Sales 35
2017 Sales 40
Name: Product A, dtype: int64
❗📝5. 직접 만들어보기
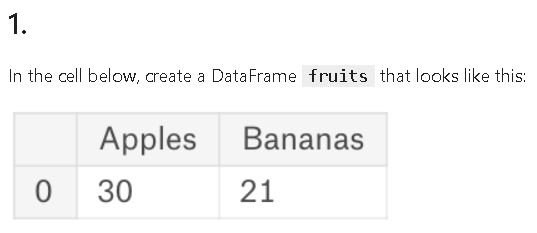
fruits = pd.DataFrame({'Apples': [30], 'Bananas': [21]})
fruits = pd.DataFrame([[30, 21]], columns=['Apples', 'Bananas'])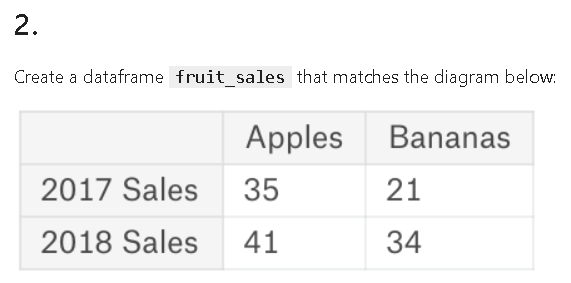
fruit_sales = pd.DataFrame([[35, 21], [41, 34]], columns=['Apples', 'Bananas'],
index=['2017 Sales', '2018 Sales'])
❗첫번째 방법:
ingredients = pd.Series(
['4 cups', '1 cup', '2 large', '1 can'],
index=['Flour','Milk', 'Eggs','Spam'],
name='Dinner')❗두번째 방법:
quantities = ['4 cups', '1 cup', '2 large', '1 can']
items = ['Flour', 'Milk', 'Eggs', 'Spam']
recipe = pd.Series(quantities, index=items, name='Dinner')📌4. 읽기(Reading data files)
- DataFrame이나 Series를 손으로 직접 생성할 수 있는 것은 편리하다. 그러나 대부분의 경우, 실제로는 직접 데이터를 만들지 않고 이미 존재하는 데이터를 사용한다. 그렇기에 데이터 파일을 읽어와야한다.
📍pd.read_csv()
- 데이터는 다양한 형식과 포맷으로 저장될 수 있다. 그 중 가장 기본적인 형식은 CSV(쉼표로 구분된 값) 파일이다. 데이터를 DataFrame으로 읽기 위해 pd.read_csv() 함수를 사용한다.
winemag = pd.read_csv("./winemag-data-130k-v2.csv")📍index_col
winemag = pd.read_csv("./winemag-data-130k-v2.csv",index_col=0)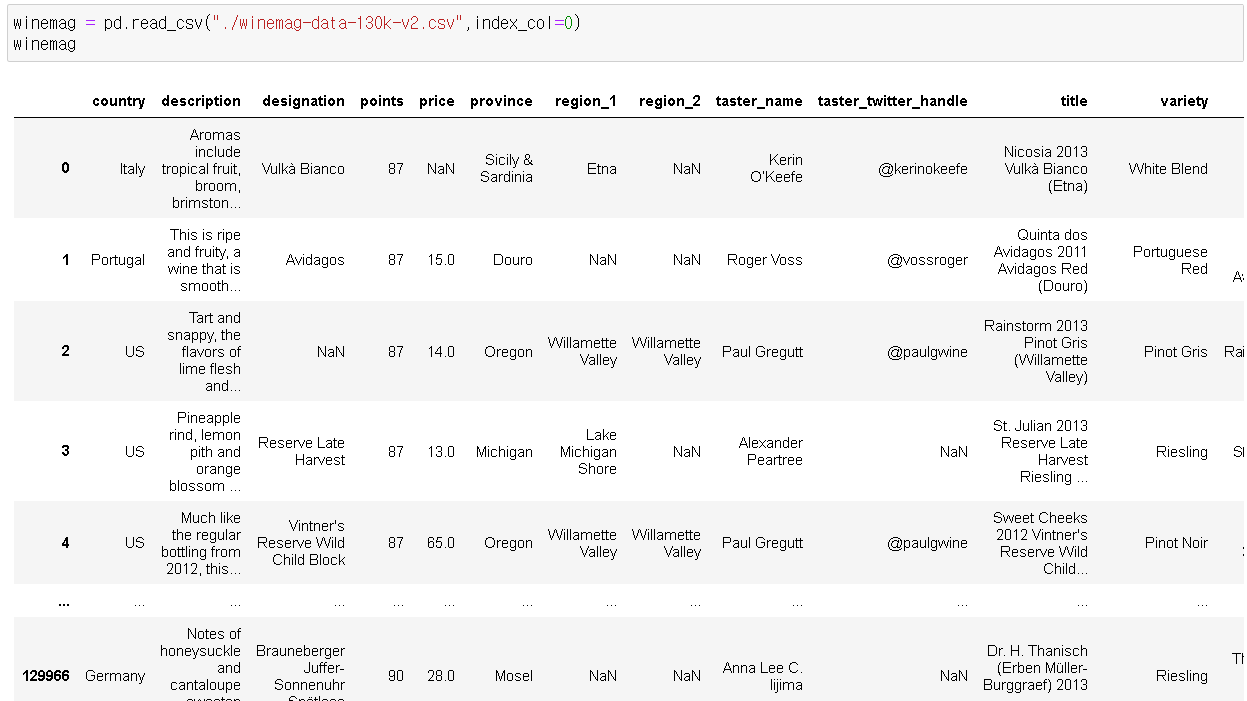
- 인덱스 0번을 인덱스 값으로 사용
📍shape
- shape 속성은 (행 수, 열 수) 형식의 튜플로, DataFrame의 크기를 나타낸다.
winemag.shape(129971, 13)
📍set_option()
- pandas에서 사용되는 옵션 값을 설정하는 함수
winemag = pd.read_csv("./winemag-data-130k-v2.csv",index_col=0)
pd.set_option("display.max_rows", 5) #5 대신 none도 가능 그러나 시간이 오래걸림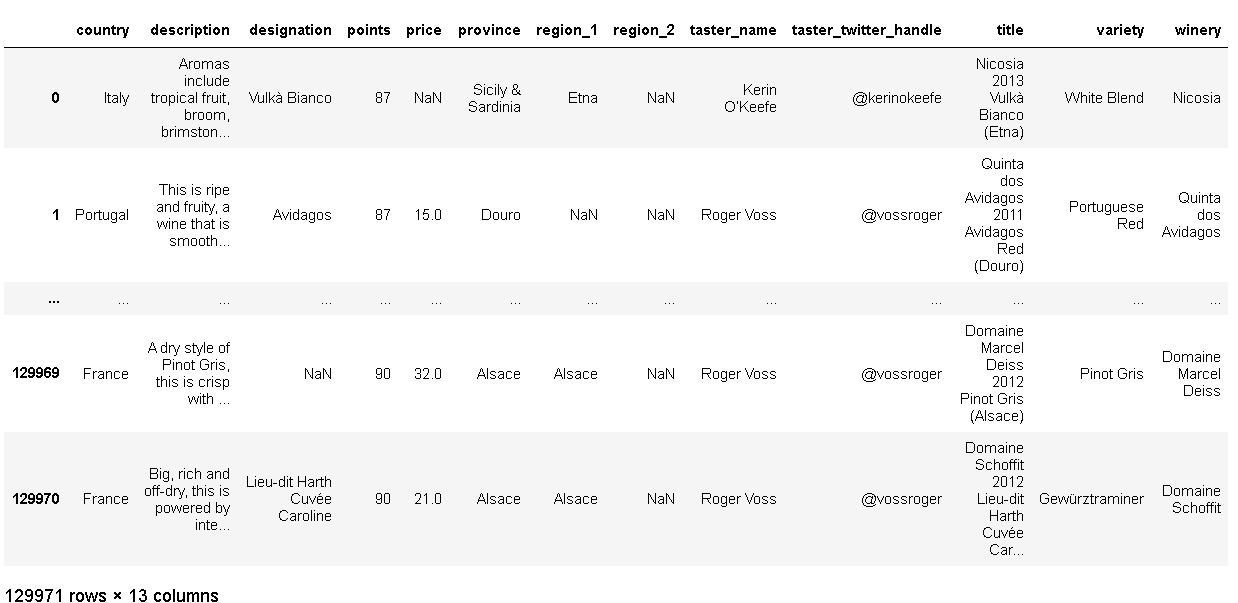
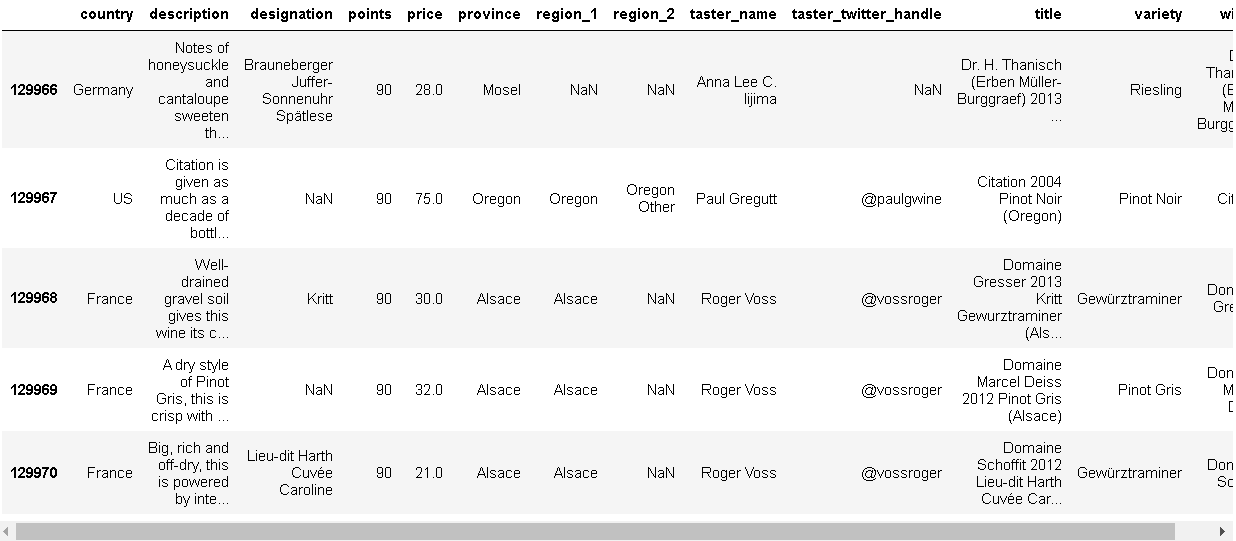
📍head()
- 첫번째 행을 출력
winemag.head()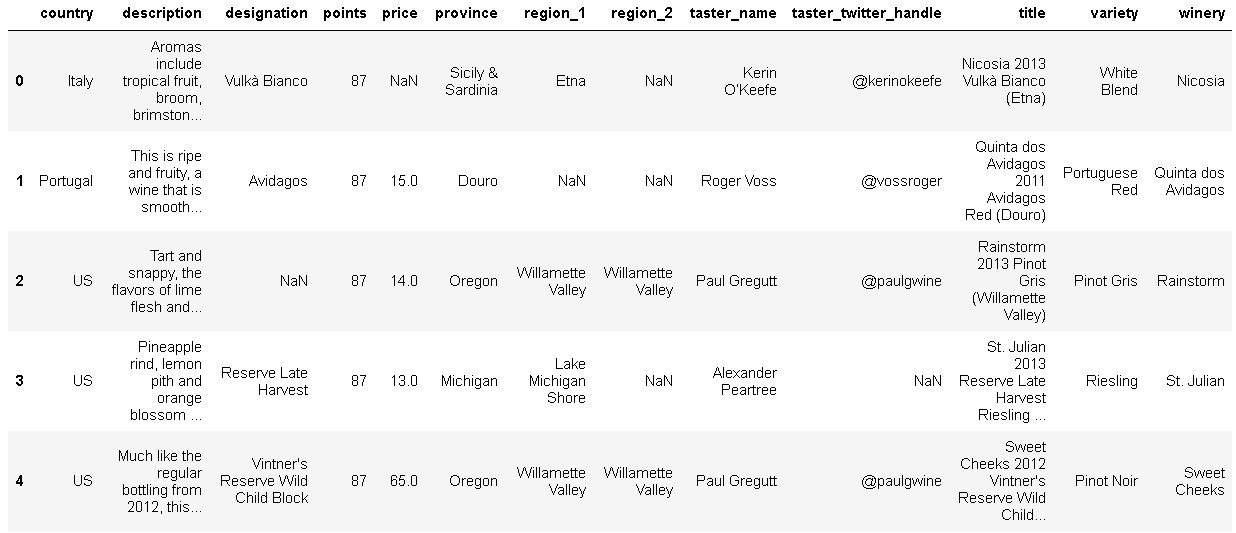
📍tail()
- 마지막 행을 출력
winemag.tail()