
1. sys.stdin.readline()
1) 개념
반복적으로 사용자의 입력을 받아야 하는 경우, 실행시간 단축을 위해 input() 대신 sys.stdin.readline()을 사용하는 것이 일반적이다. input 메서드를 오버라이드하는 방법은 아래와 같다.
import sys
input = sys.stdin.readlinesys.stdin.readline() 메서드는 아래와 같은 특징을 가진다.
① 개행 문자를 같이 입력받는다.
- 입력받은 문자열 뒤에 "\n"이 함께 포함되어 있다.
- 개행을 원치 않는 경우, 아래와 같은 방법을 사용할 수 있다.
- strip(): 문자열 양 옆의 \n 혹은 \t를 제거
- rstrip(): 오른쪽의 공백이나 개행 문자를 삭제
- strip(), rstrip()에 문자열에서 제거하고자하는 문자를 매개변수로 입력
import sys
input = sys.stdin.readline
str1 = input().strip()
str2 = input().strip('\n')
str3 = input().rstrip('\n')② sys.stdin.readline를 이용한 입력 값은 항상 문자열로 취급된다.
- 용도에 알맞은 값으로 형변환하는 과정이 필요하다.
2) 사용법
① 하나의 정수를 입력받아야 하는 경우
import sys
input = sys.stdin.readline
num = int(input())② 2~3개의 정수를 입력받아야 하는 경우
import sys
input = sys.stdin.readline
N, M = map(int, input().split())③ 여러 개의 정수를 입력받아야 하는 경우
- 리스트의 형태로 입력받는다.
numbers = list(map(int, input().split()))④ 문자열을 입력받아야 하는 경우
- 문자열 자체가 필요한 경우
import sys
input = sys.stdin.readline
s = input().strip() # Hello, World! 입력
print(s) # Hello, World! 출력- 문자열을 공백으로 구분한 배열이 필요한 경우
import sys
input = sys.stdin.readline
s = input().split() # Hello, World! 입력
print(s) # ['Hello,', 'World!'] 출력2. 파이썬 내장 함수
import 없이 사용할 수 있는 기본 함수들을 알아두면 유용할 수 있다. 대표적으로 print, sum, sort/sorted, min, max, reverse 등이 있다. 또한, 파이썬의 기본 라이브러리인 str도 별도의 import 없이 사용할 수 있는데, 대표적으로 len, upper, lower, replace, split 등이 있다.
그 중에서도 헷갈리기 쉬운 sort/sorted 메서드에 대해 자세히 알아보기로 하자. 두 함수 모두 리스트를 정렬하기 위한 목적으로 사용된다는 점은 동일하지만, 약간의 차이점이 존재한다.
① sort
- 원래의 리스트에서 제자리 정렬을 수행하기 때문에 기존 리스트가 변경된다.
- 정렬을 수행하고자 하는 리스트에 dot operator를 사용하여 정렬한다.
- 기본적으로 오름차순 정렬이 수행되므로, 내림차순으로 정렬하고 싶다면,
reverse=True를 매개변수로 전달하면 된다.
my_list = [3, 1, 2]
my_list.sort() # dot operator를 이용해 호출
print(my_list) # [1, 2, 3] 출력
my_list.sort(reverse=True) # 내림차순 정렬
print(my_list) # [3, 2, 1] 출력② sorted
- 기존 리스트는 그대로 두고, 정렬된 새로운 리스트를 반환한다.
- 정렬을 수행하고자 하는 리스트를 매개변수로 전달한다.
- 내림차순 정렬을 수행하는 방법은 sort와 동일하다.
my_list = [3, 1, 2]
sorted_list = sorted(my_list) # 리스트를 매개변수로 전달
print(sorted_list) # [1, 2, 3] 출력
print(my_list) # [3, 1, 2] 출력
sorted_list_desc = sorted(my_list, reverse=True)
print()참고로, 정렬 조건이 2개 이상일 경우, 우선 순위가 낮은 정렬 조건부터 차례로 적용하여 정렬해야 한다.
# 1. 길이가 짧은 순으로 정렬
# 2. 길이가 같으면 사전 순으로 정렬
my_list.sort() # 사전 순 정렬 먼저 실행
my_list.sort(key=len) # 길이 순으로 오름차순 정렬3. 리스트
1) 리스트의 각 원소를 띄어쓰기로 출력하기
문제를 풀다보면 배열의 값을 띄어쓰기로 구분하여 출력해야 하는 경우가 있다. 예를 들어 배열에 [4, 3, 2, 5, 1]이 들어있을 때 4 3 2 5 1을 출력해야 한다면, 아래의 두 가지 방법을 고려할 수 있다.
① Unpacking 연산자 * 사용
- 직관적이면서도 간단한 방법이다.
lst = [4, 2, 5, 3, 1]
print(*lst) # 4 2 5 3 1 출력② 문자열 변환 후 공백을 구분자로 결합
- 공백 뿐 아니라 ','나 '\n' 등의 구분자와 결합해야 하는 경우에도 적용할 수 있다.
lst = [4, 2, 5, 3, 1]
print(' '.join(map(str, lst))) # 4 2 5 3 1 출력2) 리스트의 중복 값 제거하기
리스트에 포함된 중복 값을 제거해야 하는 상황은 빈번하게 발생한다. 이와 같은 상황에서 사용할 수 있는 것은 집합(Set) 자료구조이다. 집합에서는 기본적으로 중복을 불허하기 때문에, 자연히 중복 값이 제거되는 효과를 얻을 수 있다. 그러므로, List를 Set으로 변환 후 다시 List로 변환함으로써, 중복 값을 효과적으로 제거할 수 있다.
set_list = set(lst)
distinct_lst = list(set_list)간혹 중복 값 제거와 함께 정렬을 요구하는 경우가 있는데, 반드시 중복 값 제거를 먼저 한 후에 정렬을 수행해야 한다. (먼저 정렬을 수행한 후 리스트를 Set으로 변환할 경우, 정렬이 유지되지 않는다.)
3) 리스트의 크기 사용하기
리스트의 크기를 이용할 때에는 len 함수를 이용한다. 익히 잘 알고 있는 내용일 것 같으니, 사용법만 간단히 알아보기로 하자.
my_list = [1, 2, 3, 4, 5]
size = len(my_list)
print(size) # 5 출력4) 중첩 리스트
리스트의 각 원소가 꼭 Single Value일 것이라는 보장은 없다. 실제로 리스트의 원소가 Multi Value인 경우도 많기 때문에 중첩 리스트(Nested List)의 사용법도 반드시 알아두어야 한다. 아래와 같은 문제가 있다고 하자.
>> 백준 10814번
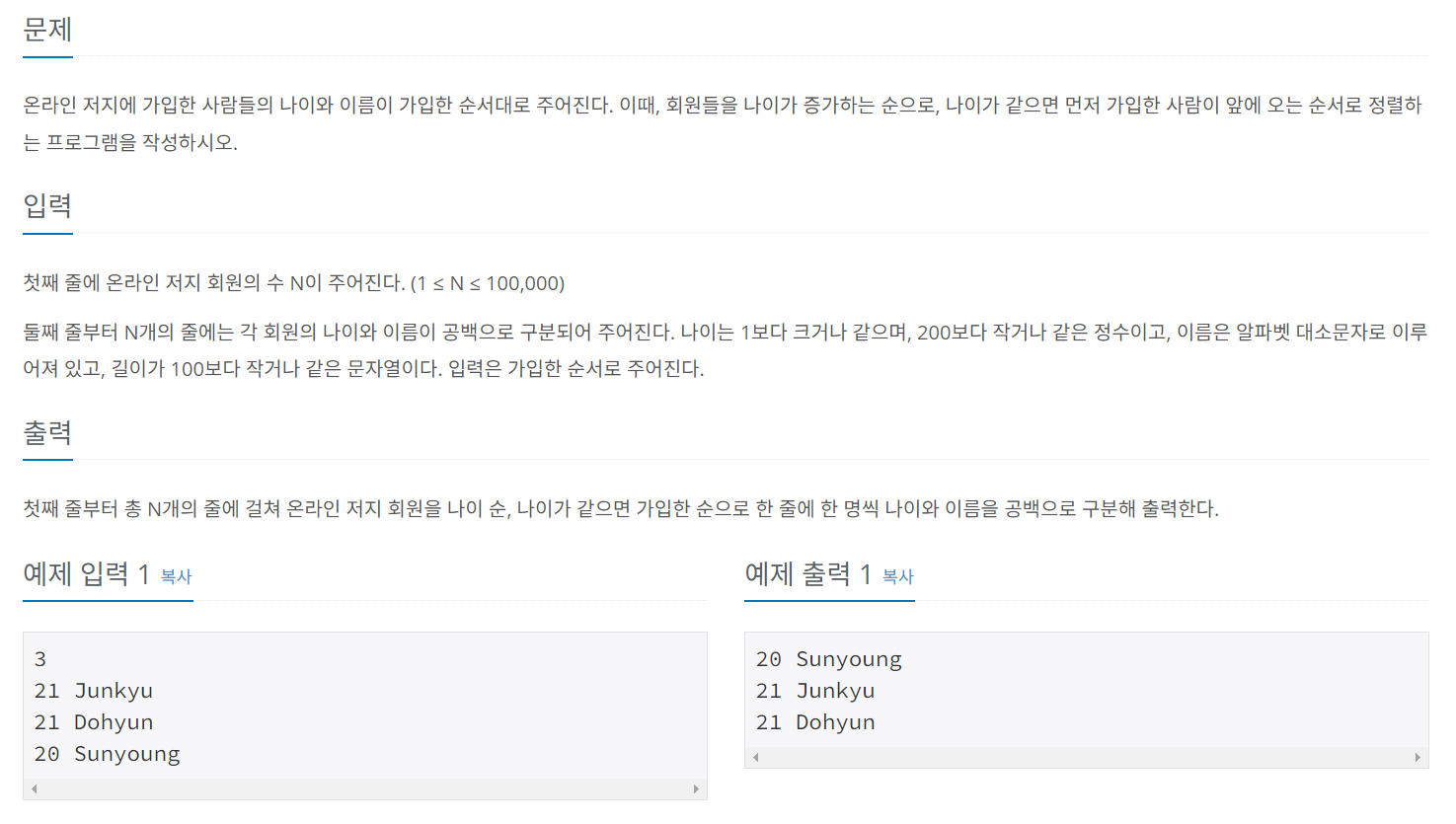
리스트의 각 원소로 나이와 이름을 모두 저장해야 한다. 이러한 상황에서는 리스트를 append()의 매개변수로 전달하면 된다.
import sys
input = sys.stdin.readline
N = int(input())
lst = []
for i in range(N):
age, name = input().split()
lst.append([int(age), name])
lst.sort()
...하지만, sort에 의해 정렬되는 리스트는 나이순 > 알파벳순으로 정렬되기 때문에 문제의 조건을 충족시키지 않는다. 문제에서 요구하는 바는 기존 리스트에서 나이순으로만 정렬하는 것이므로, sort()/sorted()의 정렬 조건을 '나이'로 지정해주는 작업이 필요하다. sort()/sorted() 메서드에 사용자 정의 정렬 조건을 적용하는 방법은 아래와 같다.
my_list = [(2, 'b'), (3, 'a'), (1, 'c')]
my_list.sort(key=lambda x: x[0]) # 첫 번째 요소를 기준으로 정렬
# 또는 sorted_list = sorted(my_list, key=lambda x: x[0])따라서 위 문제는 아래와 같이 풀이할 수 있다.
import sys
input = sys.stdin.readline
N = int(input())
lst = []
for i in range(N):
age, name = input().split()
lst.append([int(age), name])
lst.sort(key=lambda x:x[0])
for i in lst:
print(i[0], i[1])5) 리스트가 비어있는지 확인하기
파이썬에서는 리스트가 비어있는지 확인하기 위한 방법으로 리스트 자체를 조건식에 전달하는 간결한 문법을 사용한다. 이는 결과 배열이 비어있을 때 -1을 출력하라는 문제나, Queue가 빌 때까지 pop() 해야 하는 문제에서 유용하게 사용될 수 있다.
my_list = []
if not my_list:
print("리스트가 비어있습니다.")6) 리스트의 인덱스와 원소 순회하기
리스트를 순회하는 방법은 크게 인덱스 순회와 원소 순회로 구분된다.
① 인덱스 순회
lst = [1, 2, 3, 4]
N = len(lst)
for i in range(N):
print(lst[i])② 원소 순회
lst = [1, 2, 3, 4]
for i in lst:
print(i)자주 사용되지는 않지만, enumerate 메서드를 사용하여 인덱스와 원소를 동시에 순회하는 방법도 있다.
lst = [1, 2, 3, 4]
for idx, num in enumerate(lst):
print(idx, num)4. 딕셔너리
1) 딕셔너리 생성하기
① 중괄호 사용
- 기본적인 방법이자 자주 사용되는 방법이다.
// 딕셔너리명 = {키: 값, ...}
person = {'name': 'Chrome', 'age': 20, 'univ': 'Inha'}② dict() 함수 사용
- 위의 방법과 동일한 딕셔너리가 생성된다.
person = dict(name='Chrome', age=20, univ='Inha')2) 딕셔너리 요소 조작하기
① 요소 추가하기
딕셔너리명[Key] = Value의 형태로 딕셔너리에 요소를 추가할 수 있다.
person[gender] = 'Male'② 요소 변경하기
딕셔너리명[Key] = Value의 형태를 동일하게 이용하되, Key 값은 기존에 존재하던 값이어야 한다.- 딕셔너리에서 키 중복을 불허하는 이유가 바로 이것 때문이다.
person[age] = 26③ 요소 제거하기
- pop() 메서드의 입력인자로 Key 값을 전달하면 된다.
person.pop(age)- 딕셔너리 내에 모든 요소를 제거할 때에는 clear() 메서드를 사용한다.
person.clear()3) 딕셔너리 요소에 접근하기
딕셔너리 내에는 순서가 존재하지 않기 때문에 인덱스를 이용한 요소 접근은 불가하다. 대신, 딕셔너리에서는 Value에 접근하기 위해 Key 값을 이용한다.
① 기본 접근법
딕셔너리 명[Key]의 형태로 해당하는 값을 반환 받을 수 있다.
print(person['age'])② get() 메서드
- 딕셔너리 내에 존재하지 않는 Key 값을 입력해도 None을 반환할 뿐 에러가 발생하지 않기 때문에, 권장되는 방식이다.
person.get('gender')4) 딕셔너리에 특정 Key가 있는지 확인하기
in 연산을 활용하여 딕셔너리에 특정 Key가 있는지 확인할 수 있다. 예를 들어 배열 안에 특정 숫자가 몇 개 있는지를 딕셔너리로 나타내야 할 경우, 아래와 같이 코드를 작성할 수 있다.
for i in arr:
if i in dict:
dict[i] += 1
else:
dict[i] = 15) 딕셔너리 순회하기
① Key 순회
dict = {...}
for i in dict:
...② Value 순회
dict = {...}
for i in dict.values():
...5. 소수점 이하 처리
1) 메서드
① 올림
- math 모듈을 import 해야 한다.
math.ceil(-3.14) # -3
math.ceil(3.14) # 4② 내림
- math 모듈을 import 해야 한다.
- floor() 메서드는 내림을 적용하고 int 형변환은 버림을 적용한다.
math.floor(-3.14) # -4
int(-3.14) # -3③ 반올림
- 별도의 모듈 import 없이 내장 메서드인 round()를 사용한다.
- "소수점 이하 셋째 자리에서 반올림하여 둘째 자리까지 출력한다"라는 조건이 있을 때, round의 매개변수에 3을 전달하지 않도록 주의한다.
# 기본적으로 소수 첫째자리에서 반올림
print(round(3.1415)) # 3 출력
# 몇째 자리까지 나타낼지 매개변수를 통해 지정 가능
print(round(3.1415, 2)) # 3.14 출력2) round 메서드 주의사항
① 반드시 소수점 이하 N째자리까지 출력해야 하는 경우
- round는 표시할 소수점 이하 자리 수가 없는 경우, 아무 것도 표시하지 않으므로, 포매팅 코드를 함께 사용해주어야 한다.
## 소수점 이하 둘째자리까지 출력해야 하는 상황 ##
print(round(2.0, 2)) # 2.0 출력
print("%.2f" % round(2.0)) # 2.00 출력② 오사오입
round()메서드의 반올림은 우리가 흔히 아는 반올림의 개념과 조금 다르다.- 4 이하의 숫자는 내리고, 5 이상의 숫자는 올리는 사사오입과 달리,
round()메서드는 오사오입을 적용한다. - 오사오입은 아래와 같이 정의된다.
- 5 미만의 숫자는 내리고, 5 초과의 숫자는 올린다.
- 5를 반올림해야 하는 경우, 5의 앞자리가 홀수이면 올림을, 짝수이면 내림을 적용한다.
- 그러므로, 상황에 따라 사사오입 반올림 함수를 직접 구현해야 할 수도 있다.
## 사사오입 반올림 메서드 ##
def round(num):
if num - int(num) >= 0.5:
return int(num) + 1
else:
return int(num)
## 소수점 이하 둘째자리까지 나타내야 하는 경우 ##
def round(num):
num *= 100
if num - int(num) >= 0.5:
return (int(num) + 1) / 100
else:
return int(num) / 1006. 실행시간 예측
쉬운 문제에서는 조금 비효율적이더라도 간편한 코드가 유리하고, 어려운 문제에서는 복잡하더라도 실행시간이 적은 코드가 유리하다. 예를 들어 O(N^2)으로도 충분히 풀 수 있는 문제를 O(NlogN)으로 푼다던가, 반대로 O(NlogN)으로 풀어야 할 문제를 O(N^2)으로 푼다면, 시간을 크게 낭비하게 된다.
즉, 문제의 난이도에 맞는 코드를 짜기 위해선, 실행시간을 예측할 수 있어야 한다는 것이다. 그러면, 지금부터 실행시간을 예측하는 방법에 대해 알아보기로 하자.
가장 일반적인 계산법은 1억(10^8) 번의 연산을 1초로 가정하는 것이다. 물론, 절대적인 수치는 아니기에 상황에 따라 시간이 초과되지 않을 수도 있지만, 제한 시간에 가까운 알고리즘은 되도록 지양하는 것이 좋다. 시간 예측의 예시를 보자.
① 입력 값의 크기: N=1,000 / 제한 시간: 1초
O(N) = 10^3
O(NlogN) = 3*(10^3)
O(N^2) = 10^6
O(N^3) = 10^9- O(N^3) 알고리즘만 사용하지 않는다면 문제 풀이에 전혀 지장이 없을 것이다.
② 입력 값의 크기: N=10,000 / 제한 시간: 1초
O(N) = 10^4
O(NlogN) = 4*(10^4)
O(N^2) = 10^8
O(N^3) = 10^12- O(N^3) 알고리즘 뿐 아니라, O(N^2) 알고리즘도 피하는 게 좋다.
③ 입력 값의 크기: N=1,000,000 / 제한 시간: 1초
O(N) = 10^6
O(NlogN) = 6*(10^6)
O(N^2) = 10^12- O(NlogN) 알고리즘 사용 시 시간 초과가 발생할 수도 있다.
대략적으로, 반올림했을 때 10^7 정도가 되면(5*10^6 정도), 지양해야 할 알고리즘이라고 생각하면 될 것 같다. 아래의 문제를 보자.
>> 백준 10815번
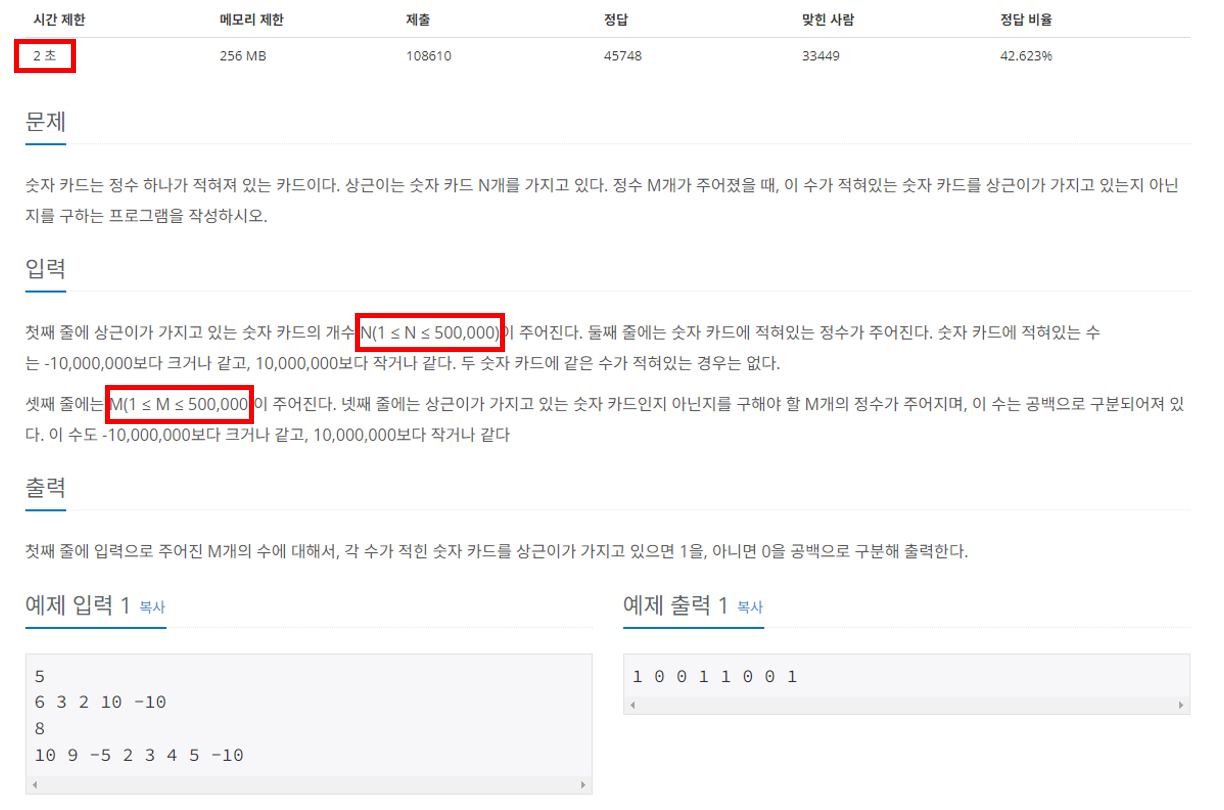
만약 위의 문제를 이중 for문을 이용해 풀이한다면, O(NM)이 되므로 최악의 경우 25*(10^10) 번의 연산이 필요하다. 당연히 시간이 초과될 것이므로, 이중 for문을 이용한 전략은 포기해야 할 것이다. 그러면 이제 고려해볼 방법은 O(NlogN)일텐데, 주어진 리스트 내에서 값을 탐색해야 한다는 점에서 자연히 Binary Search를 이용한 전략을 떠올리게 될 것이다. (집합 자료구조를 이용하면 O(N)의 실행시간으로 풀이할 수도 있다.)
위 문제에 대한 풀이는 입문 수준을 벗어나므로 생략하기로 한다. 다만 여기서 중요한 것은, 실행시간을 대략적으로 예측하여 적절한 알고리즘을 유추해내는 프로세스를 익히는 것이다.
7. 주의 사항
① 증감 연산자의 부재
- 다른 언어에서는 흔히 1씩 증감시키고자 할 때,
++나--를 자주 사용하지만, 파이썬에서는 이와 같은 증감 연산자를 제공하지 않는다. - 그러므로 반드시
+=이나-=으로 대체하여 사용해야 한다.
x = 5
x += 1 # 증감 연산② 논리 연산자
- 다른 언어에서는
&&나||,!등의 논리 연산자를 사용하지만, 파이썬에서는 보다 직관적인 and, or, not을 사용한다.
if not is_odd:
print("This number is even.")③ True/False
- 파이썬에서는 Boolean 값에 오직
True,False만 할당할 수 있다. - 다시 말해,
true/false,TRUE/FALSE모두 사용할 수 없다.
is_even = True
is_odd = False