인프런 Chris Song님 강의 정리
Section0: 머신러닝 파이프라인 소개
개요 (강의에 없는 내용)
강의에 머신러닝 파이프라인의 개념에 대한 구체적인 설명이 없어서
나와 같은 MLOps 찐초보를 위해 정리했다.
머신러닝 파이프라인이란 명칭은 책에서나 프로젝트를 하면서 많이 들어봤지만,
무엇을 의미하는 것인지 정확히 알지 못했다.
아래에 머신러닝 파이프라인 예시와 관련된 그림 자료를 추가했다.
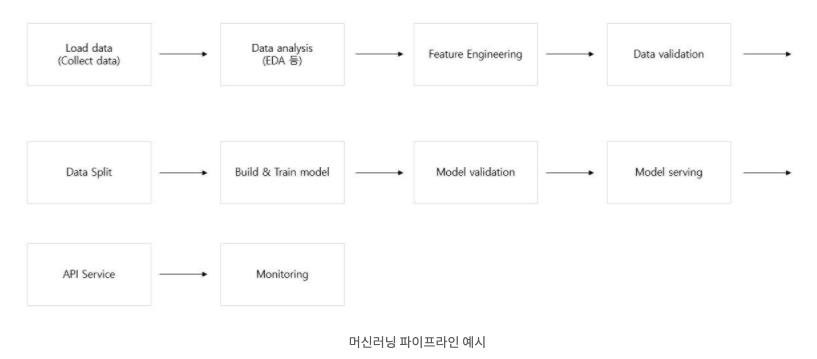

머신러닝은 단순히 모델의 성능만 좋게하면 끝나는 것이 아니었고,
지속적으로 유지보수 관리를 해서 서비스가 잘 되도록 하는 작업이 필요했다.
위 그림에서 Model Serving, API Service, Monitoring 부분이 잘 이루어져 있어야 했다. data Load 관련된 부분은 데이터 파이프라인과 관련된 부분이기 때문에 별도의 공부가 필요할 것 같다.
즉, 머신러닝 파이프라인이 필요한 이유를 간단하게 요약하자면
1. 지속적으로 모델의 품질을 향상시키고
2. Error를 사전 대응할 수 있고
3. 시스템을 유지 관리 할 수 있다.
머신러닝 파이프라인의 이해
파이프라인을 통해 얻는 이점
- 생산성 향상
- 같은 시간에 많은 모델을 만들 수 있음
- 예측 가능한 품질
- 지속적으로 모델의 성능은 떨어짐
- 시스템화를 시켜서 품질을 향상시킴
- 장애 대응능력 향상
- ML은 장애를 인지하기 어렵고 대응도 힘듦
머신러닝 파이프라인의 필요성
- ML 모델 배포(save, predict)는 쉬워졌지만 모델을 운영하기가 힘든 현실
- 시스템을 유지하고 관리하는 비용이 매우 큼
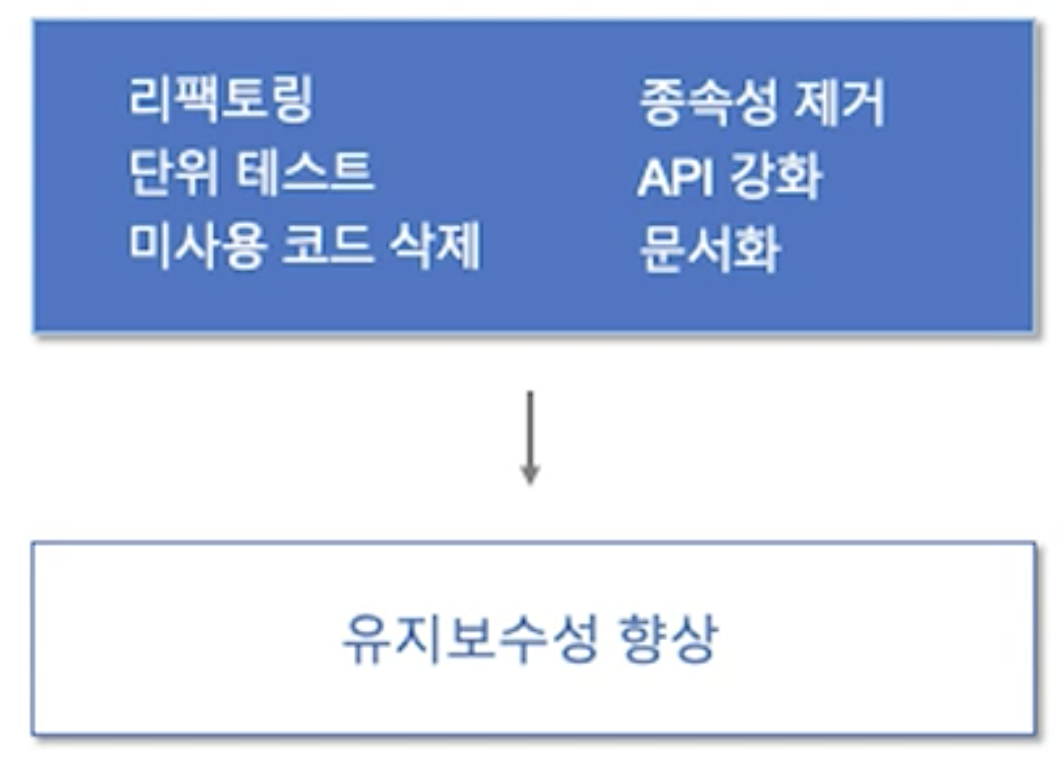
기술부채
- 지금 당장은 쉽게 만들어도 기술부채를 만들면, 언젠가는 내게 피해를 줌 --> 부채
- 아름다운 Architecture 구축 이유: 미래의 발생할 장애를 방지하기 위함
- 방식
머신러닝 문제의 특징
쉬운/어려운 머신러닝 문제


- 머신러닝 문제 (시스템 integration 시)
- online serving: API 서버를 만들어서 real time serving
- 오류가 날 때, 대응할 수 있는 여유가 없음
- offline serving: 전체 user에 대해서 하루에 한번 실행 (좀 더 쉬움)
- 오류가 날 때, 대응을 할 수 있는 여유가 있음
- online serving: API 서버를 만들어서 real time serving
머신러닝 프로그래밍 문제의 특징


- silent failure 방지 필요:
- silent failure: 모델이 error를 내지 않아서 문제가 없어보이지만 실제 결과를 보면 error가 존재하는 경우
- 문제 해결을 위해 신경을 써야할 사항:
- 데이터 엔지니어링에 대한 숙련도가 있어야됨
- Software engineer가 ML 프로젝트 팀 구성 멤버로 존재해야됨
- ML은 본질적으로 실험(파라미터 구성, 알고리즘, 모델링, feature)이기 때문에 실험 관리가 필요함
- 테스팅 방법: ML 시스템 테스트는 즉각적으로 모르는 경우가 있음
- 주가 예측 시, 확인하려면 내일 봐야됨
- 배포가 간단하지 않음
MLOps의 핵심 문제

- 진화하는 데이터에 따른 평가 기준이 달라질 수 있음
- 지속적 통합/배포/학습 pipeline을 만들어야됨
MLOps 성숙도 레벨
Lvl 0
- 우리 나라의 대부분에 해당됨

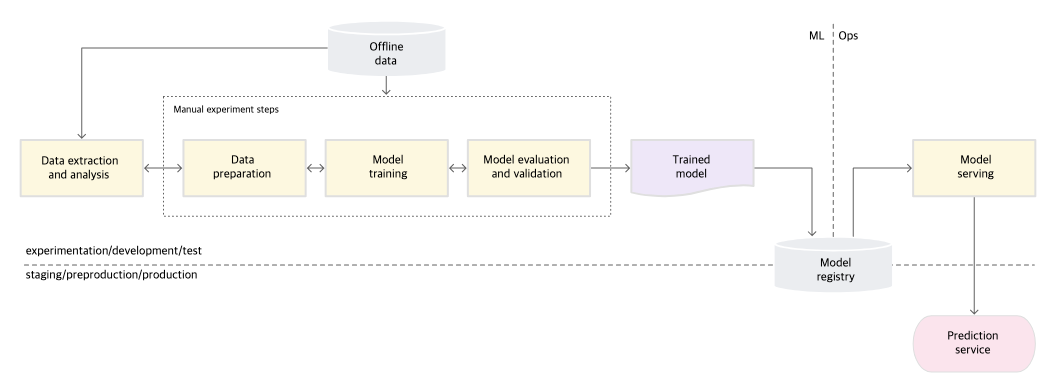
- 모델 registry가 있어야됨
Lvl 1

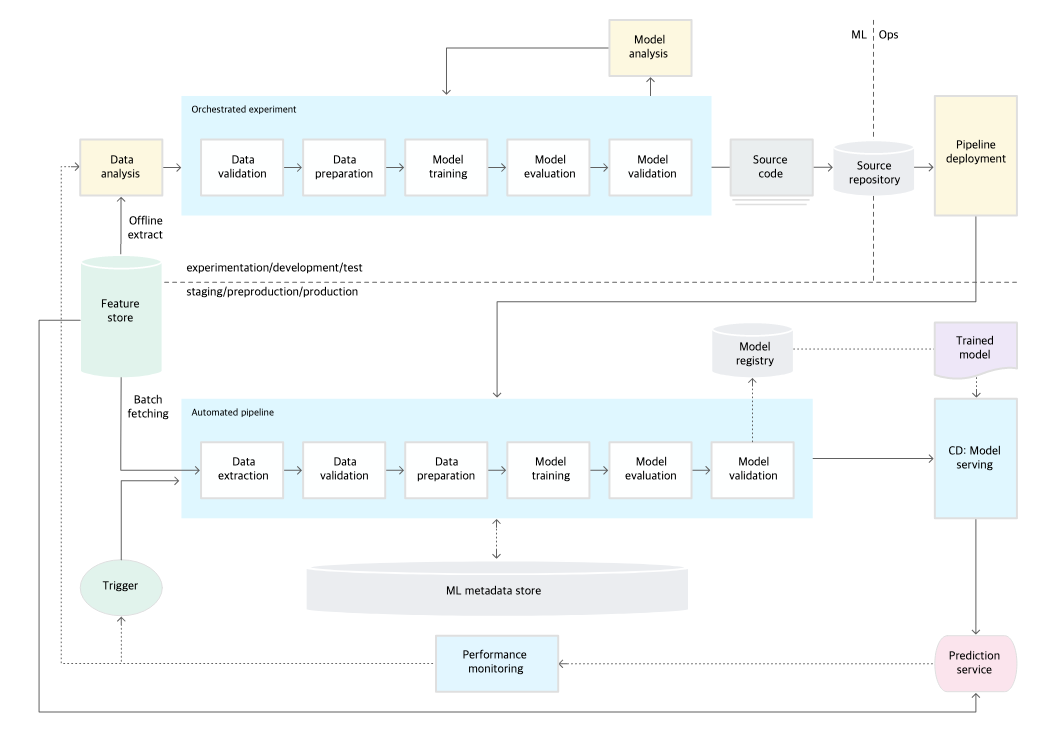
Lvl 2

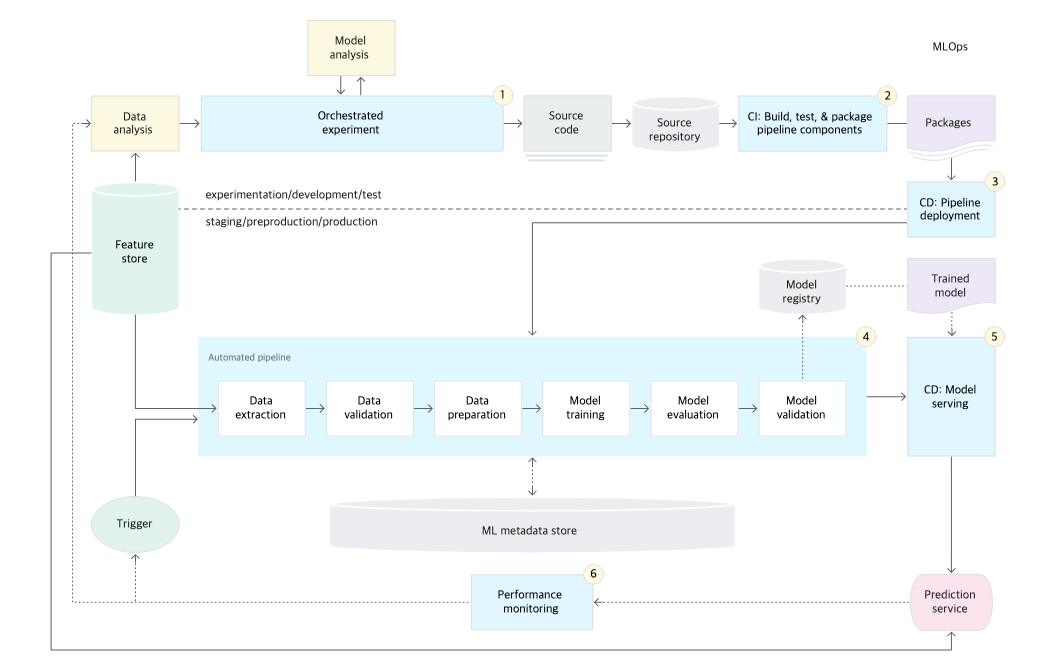
머신러닝 파이프라인 단계
개요
- 새로운 학습 데이터를 수집하는 것으로 시작해서 학습된 모델이 어떻게 작동하고 있는지에 대한 피드백을 받는 것으로 끝남
- 데이터 전처리, 모델 학습, 분석 및 배포 등 다양한 단계가 포함됨
- 수동으로 수행하는 것은 비효율적이기 때문에 자동화가 되어야됨
- 다른 팀과 협업을 하는 것은 커뮤니케이션이 잘 안되는 경우가 대부분
- 제대로 시스템을 구축하지 않으면, 모델 배포 이후 장애 대응만 하는 경우도 존재한다.
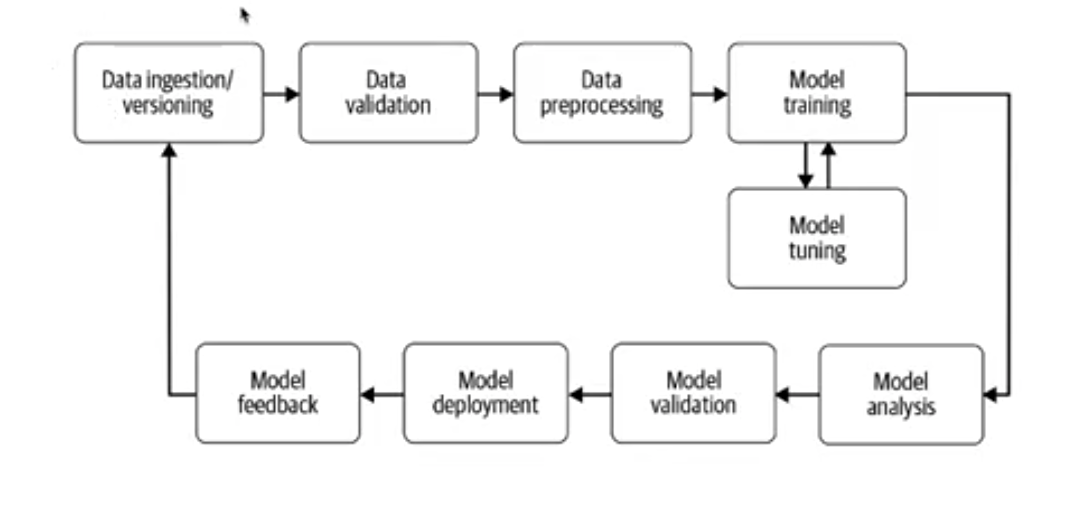
데이터 수집 (Data ingestion/versioning)
- version 관리를 안하면 재현가능성이 떨어짐
- 일반적으로 Cloud기반으로 하기 때문에 Object Storage 방식을 사용
- ex. Amazon S3, GCS
- data injection을 할 때, query를 serialize해서 Object Storage에 저장하는 방식이 좋다.
데이터 유효성 검사 (Data validation)
- 이상 징후 감지될 경우, 경고
- 유효성 검사를 하지 않으면, 데이터가 잘못되다가 파이프라인이 깨지는 경우가 생김
- 개발자가 로그를 공지 없이 변환하는 경우
데이터 전처리 (Data preprocessing)
- 학습 실행에 사용하기 위해 데이터를 사전에 처리해야됨
- ex. embedding, normaliztion, one-hot encoding ...
모델 학습 (Model training)
- 모델 훈련을 효율적으로 분산시키는 것이 중요하다.
- auto ML에 대한 early stop이 중요
모델 튜닝 (Model tuning)
- Auto ML을 얼마나 잘하느냐를 의미
- Parameter 선정, 알고리즘 선정 등
모델 분석 (Model analysis)
- 모델의 학습된 결과값을 가지고 모델 EDA
- ex. AUC, accuracy, recall ...
모델 버전 관리 (Model validation)
- 어떤 모델, 하이퍼 파라미터 세트 및 데이터 셋이 선택되었는지 추적
모델 배포 (Model deployment)
- 1~2개의 모델은 무관하지만, 10개 이상인 경우 관리를 하기 매우 어려움
- ex. tensorflow serving, GRPC ..
- Pytorch는 serving할 때 안좋게 느껴짐
- 코드까지 배포를 하기 때문에, 형상관리를 하기가 어려움
모델 피드백 (Model feedback)
- 새로 배포된 모델의 효과와 성능 측정

Data Scientist, Data Analyst