인프런 Chris Song님 강의 정리
Section1: 머신러닝 프로젝트 실험관리
실험관리
실험관리가 필요한 이유
- 어떤 데이터로 학습시켰는지 까먹음
- 가장 성능 좋은 모델이 무엇인지 파악해야됨
- Metric에 따른 기록 및 navigation을 해야됨
Weights and Biases
- 실험관리 기능을 기본으로 탑재
- 다양한 python framework에 적용 가능
- Tensorflow, Pytorch, Keras, Scikit-learn ..

- Tensorflow, Pytorch, Keras, Scikit-learn ..
- GPU 사용률 파악
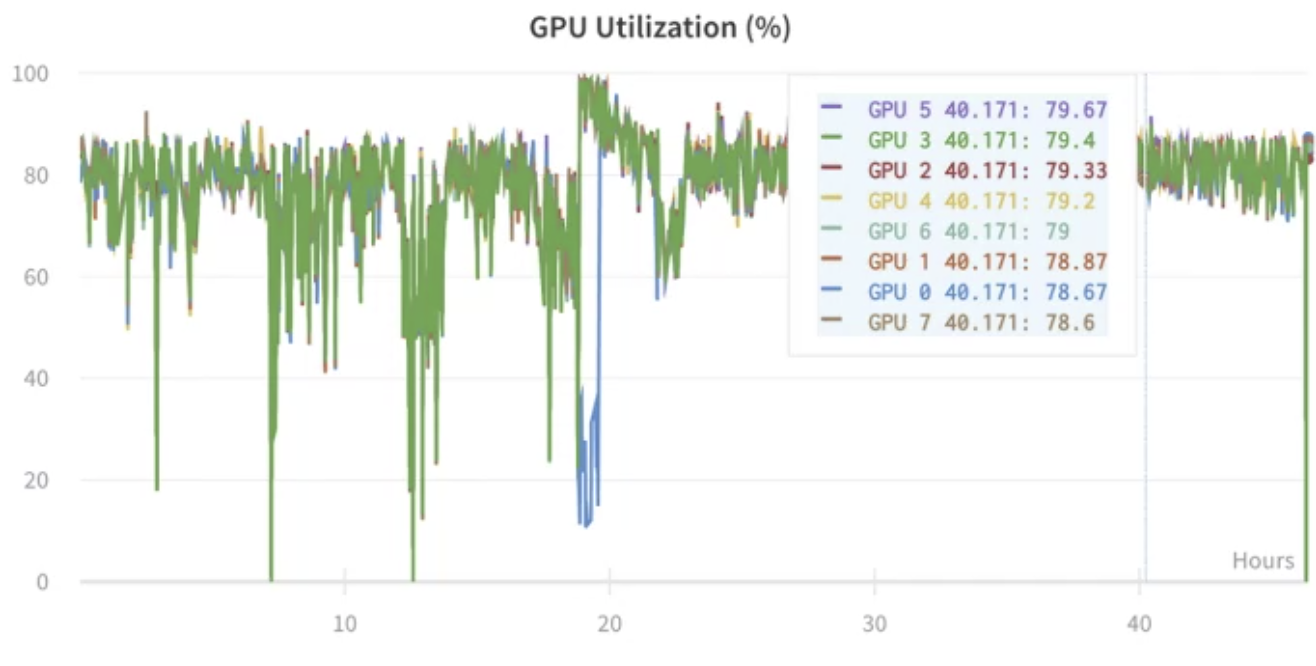
- 실시간으로 퍼포먼스 디버깅을 할 수 있음
실습
import random
import numpy as np
import tensorflow as tf
from wandb.keras import WandbCallback
# Simple Keras Model
# Launch 20 experiments, trying different dropout rates
for run in range(20):
# Start a run, tracking hyperparameters
wandb.init(
project="keras-intro",
# Set entity to specify your username or team name
# ex: entity="wandb",
config={
"layer_1": 512,
"activation_1": "relu",
"dropout": random.uniform(0.01, 0.80),
"layer_2": 10,
"activation_2": "softmax",
"optimizer": "sgd",
"loss": "sparse_categorical_crossentropy",
"metric": "accuracy",
"epoch": 6,
"batch_size": 256
})
config = wandb.config
# Get the data
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train, y_train = x_train[::5], y_train[::5] # Subset data for a faster demo
x_test, y_test = x_test[::20], y_test[::20]
labels = [str(digit) for digit in range(np.max(y_train) + 1)]
# Build a model
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(config.layer_1, activation=config.activation_1),
tf.keras.layers.Dropout(config.dropout),
tf.keras.layers.Dense(config.layer_2, activation=config.activation_2)
])
model.compile(optimizer=config.optimizer,
loss=config.loss,
metrics=[config.metric]
)
# WandbCallback auto-saves all metrics from model.fit(), plus predictions on validation_data
logging_callback = WandbCallback(log_evaluation=True)
history = model.fit(x=x_train, y=y_train,
epochs=config.epoch,
batch_size=config.batch_size,
validation_data=(x_test, y_test),
callbacks=[logging_callback]
)
# Mark the run as finished
wandb.finish()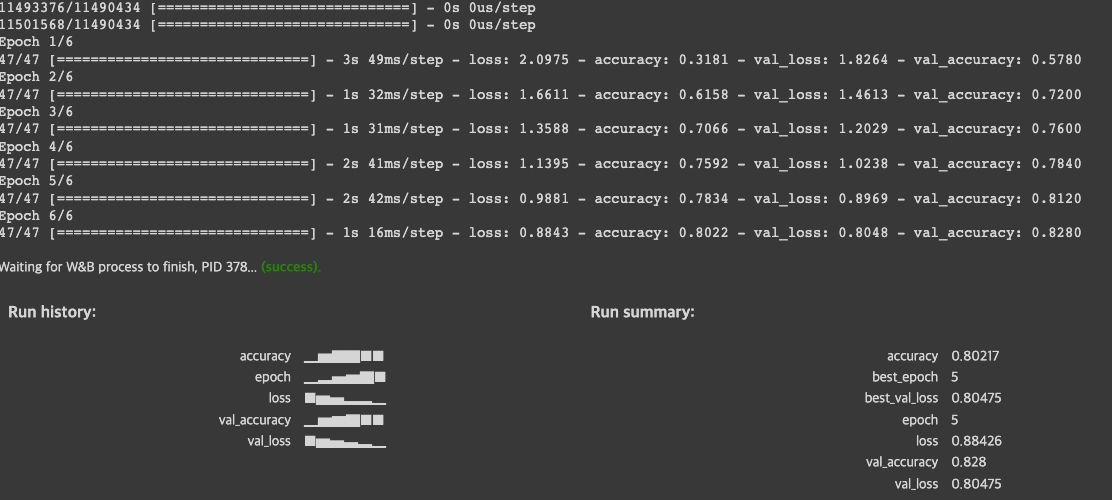
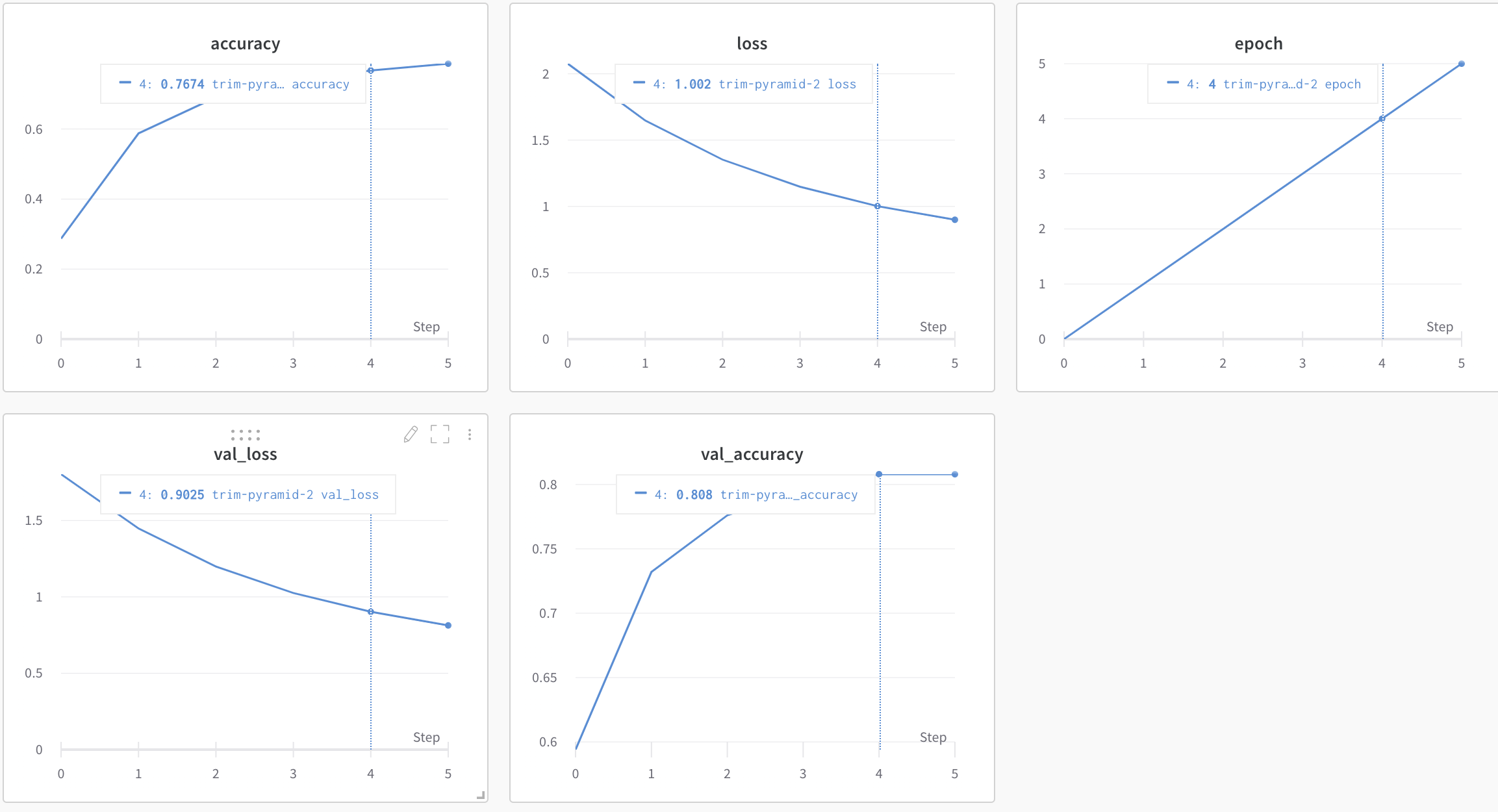
하이퍼 파라미터 최적화
- Hyper Parameter Optimization(HPO)
- 모델 성능 개선에 도움이 됨
- 머신러닝의 반복업무이므로 자동화를 해야함
W&B Sweeps
- Weights and Biases의 하이퍼 파라미터를 자동으로 최적화해주는 도구
실습1
# %load train_lib.py
def train():
import numpy as np
import tensorflow as tf
import wandb
config_defaults = {
'layers': 128
}
wandb.init(config=config_defaults, magic=True)
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
train_images.shape
train_images = train_images / 255.0
test_images = test_images / 255.0
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(wandb.config.layers, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
sweep_config = {
'method': 'grid',
'parameters': {
'layers': {
'values': [32, 64, 96, 128, 256]
}
}
}
import wandb
sweep_id = wandb.sweep(sweep_config)
wandb.agent(sweep_id, function=train)
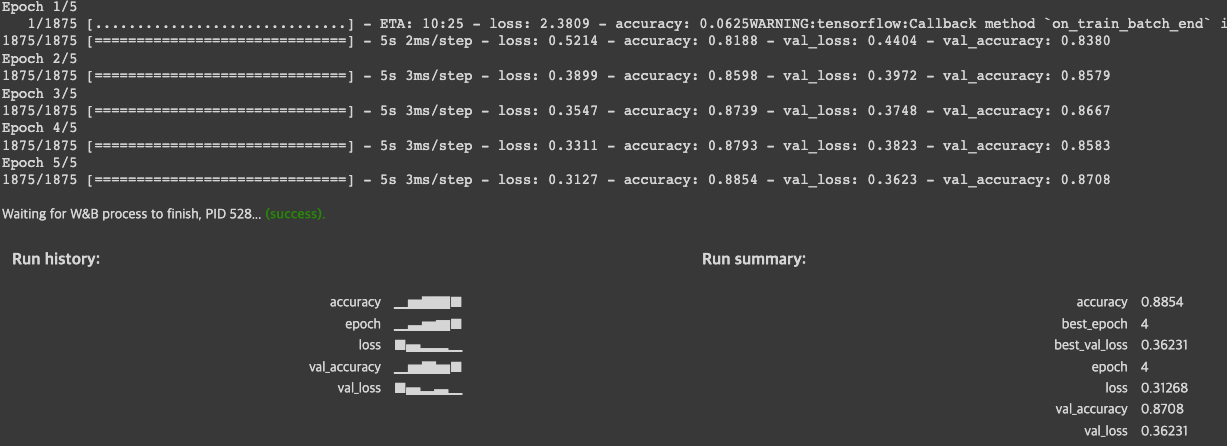
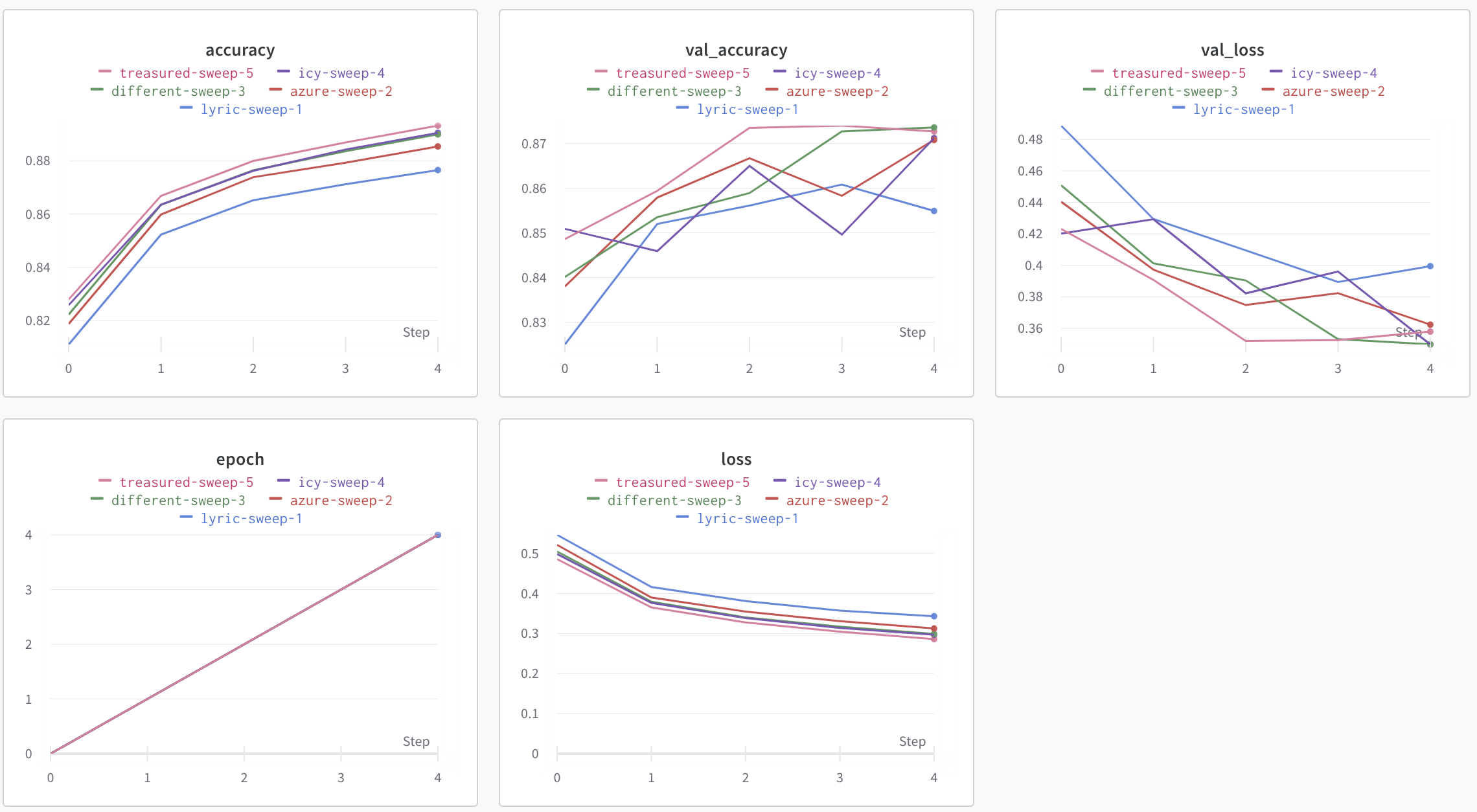
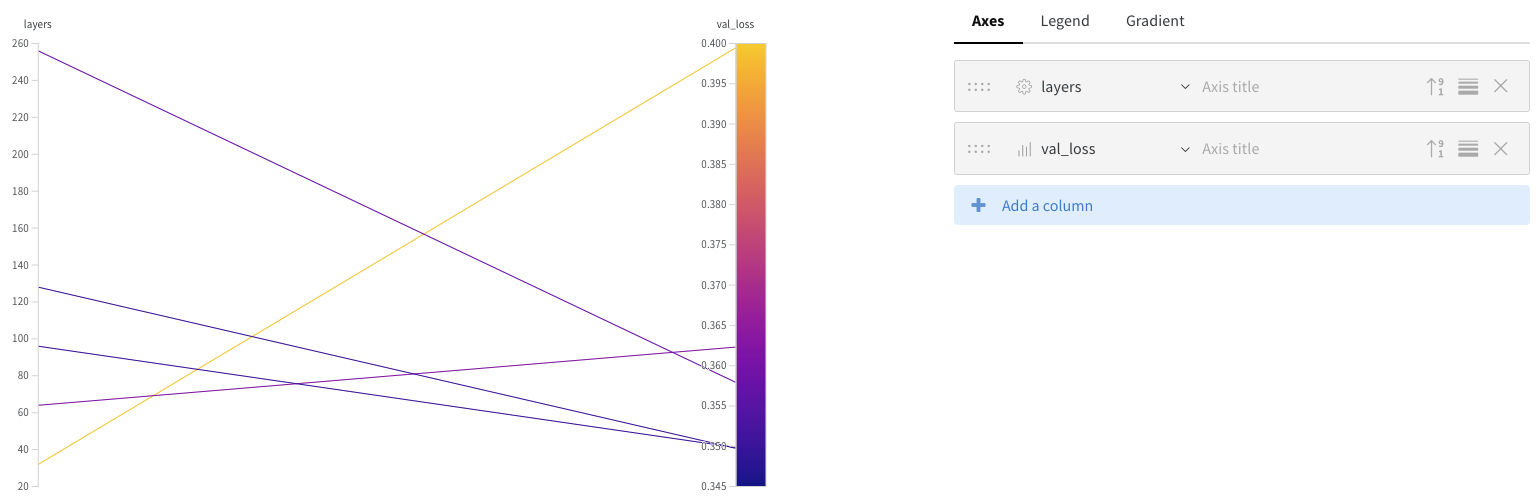
실습2
# %load train_lib.py
def train():
import numpy as np
import tensorflow as tf
import wandb
config_defaults = {
'layer1_size': 128,
'layer1_activation': 'relu',
'dropout_rate': 0.2,
'optimizer': 'adam',
'learning_rate': 0.01
}
wandb.init(
project='sweep-practice',
config=config_defaults,
magic=True)
config = wandb.config
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
train_images.shape
train_images = train_images / 255.0
test_images = test_images / 255.0
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(config.layer1_size, activation=config.layer1_activation),
tf.keras.layers.Dropout(config.dropout_rate),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
if config.optimizer == "rmsprop":
opt = tf.keras.optimizers.RMSprop(learning_rate=config.learning_rate)
else:
opt = tf.keras.optimizers.Adam(learning_rate=config.learning_rate)
model.compile(optimizer=opt,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5,
validation_data=(test_images, test_labels))
sweep_config = {
'method': 'grid',
'parameters': {
'layer1_size': {
'values': [32, 64, 96, 128]
},
'layer1_activation': {
'values': ['relu', 'sigmoid']
},
'dropout_rate': {
'values': [0.1, 0.2, 0.3, 0.4, 0.5]
},
'optimizer': {
'values': ['adam', 'rmsprop']
},
'learning_rate': {
'values': [0.1, 0.01, 0.001]
}
}
}
sweep_id = wandb.sweep(sweep_config, project='sweep-practice')
wandb.agent(sweep_id, function=train)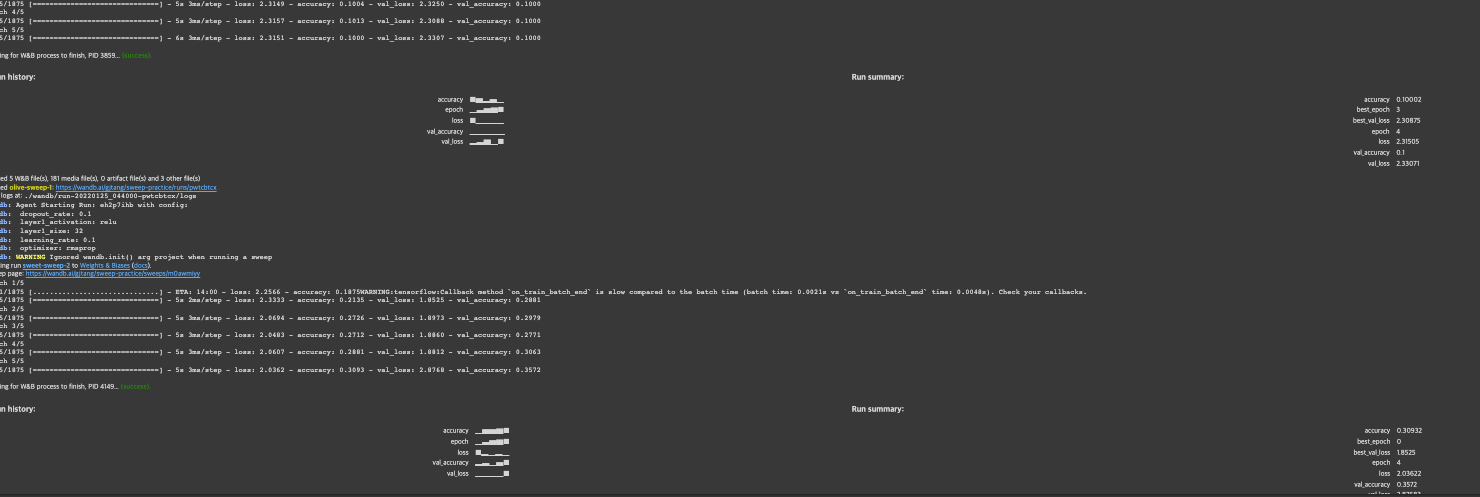
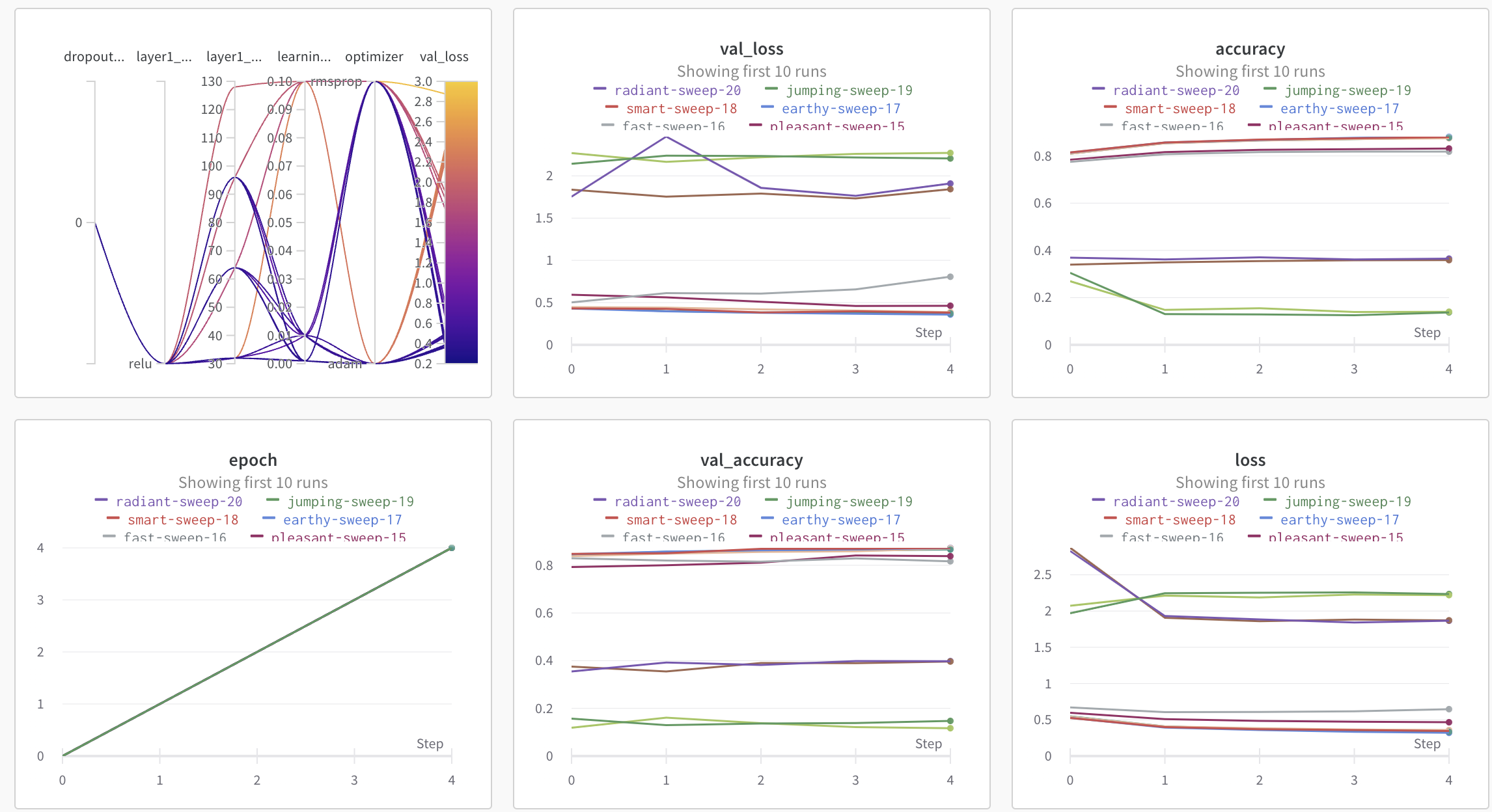
레포트 기능
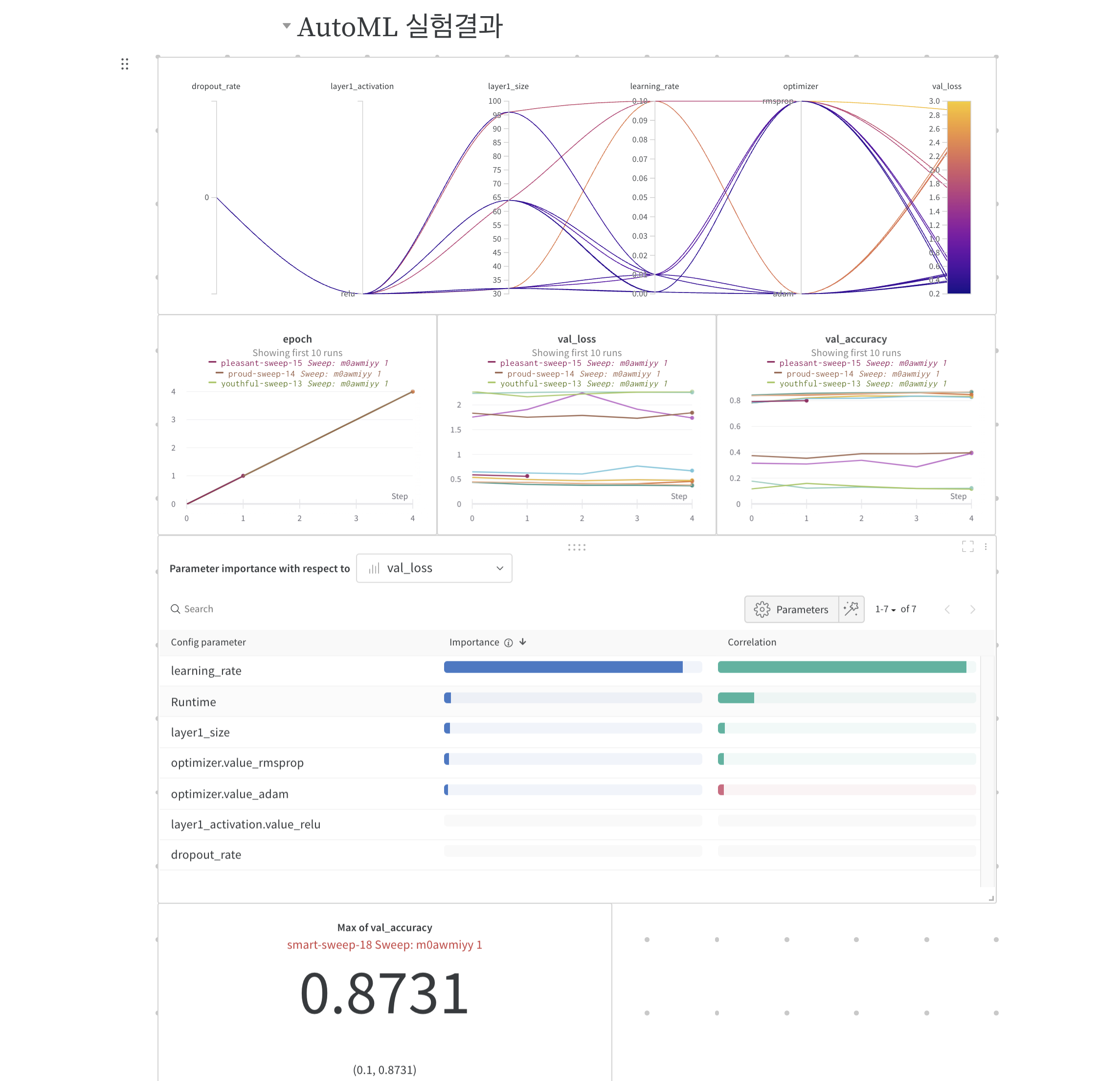
참고

Data Scientist, Data Analyst