고려대학교 산업공학과 정태수 교수님 강의 정리
Week6: 마르코브 결정 프로세스-2
6-1. MDP 가치함수
MDP 구성요소
- 시간공간
- 상태공간
- 행동공간
- 상태전이 확률
- 보상
순차적인 의사결정
- 좋은 선택을 위한 판단 근거가 필요 --> 현재는 보상 정보 활용
- 최적의 의사결정을 내리기 위한 방법 --> 가치함수(Value Function)
가치함수
상태-가치 함수 (State-value function)
- 의사결정 시점 t에서의 상태가 s일 때, t시점부터 정책 를 따른 경우 기대 누적 보상합

벨만 기대 방정식 (Bellman Expectation Equation)
- 식: 재귀적인 식으로 표현 가능

- 예시: 누적보상을 최대화하는 경우 가 좋음

행동-가치 함수 (Action-value function)
- 의사결정 시점 t에서의 상태가 s일 때 행동 a를 취한 후, 다음 시점 t+1이후부터 정책 를 따른 경우 기대 누적 보상합


- 예시

상태-가치함수와 행동-가치 함수의 관계
-
상태 가치함수

-
행동 가치함수
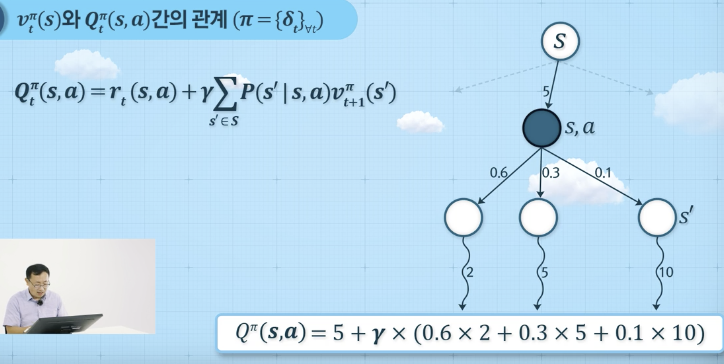
-
재귀식 정의
- 상태가치함수는 라는 정책에 의해서 지금 단계에서 action을 취했을 때의 행동가치함수 값과 같다.
- a에 대입, 아래 파랑색 공식은 정책이 확률적으로 주어졌을 때 재귀식을 정의한 것


- Q함수 재귀식 정의


최적 정책, 최적 가치함수
- 목적: 누적 보상합을 최대화 할 수 있는 정책을 찾는 법
- 최적 정책():

- 최적 가치함수 (optimal value function):

최적 가치함수 구하는 법
- 방법: 벨만 최적 방정식
- 확정적인 상황에서의 동적계획법

- 확정적인 상황에서의 동적계획법
- 벨만 최적 방정식

- 라는 행동을 했을 때 얻을 수 있는 누적보상 합의 최대값

- 라는 행동을 했을 때 얻을 수 있는 누적보상 합의 최대값
Finite-horizon MDP 해법
- 역진귀납법(backward induction)
- terminal reward부터 시작해서 backward로 recursive equation 계산 진행
- 궁극적으로 모든 단계에서, 모든 상태에서의 누적 보상 값을 최대로 하는 최적 가치함수 값을 구할 수 있음
- 각 단계 별 모든 상태에서의 최대값을 주는 action을 모은 것 --> 최적 정책(optimal policy)

6-2. Infinite-horizon MDP
- 프로세스가 무한 지속된다고 가정
- 강화학습의 기본 수학적 모델 (모델 기반의 강화학습으로 불림)
정상성(Stationary) 가정
- 보상과 상태전이행렬이 의사결정시점(단계) t에 의존적이지 않음

- 현재 보상의 기대값과 미래 보상의 기대값이 같다고 가정하는 것

- 상태전이행렬
- Finite-horizon MDP

- Infinite-horizon MDP

- Finite-horizon MDP
정책(Policy)
- 모든 시점에 의사 결정 규칙의 조합

정상 정책(Stationary Policy)


정책 가 주어졌을 때 상태 s의 가치함수
- 상태 s로부터 정책 를 따라갔을 때 받을 것으로 예상되는 감가율이 고려된 총 보상 합의 기대치

- Infinite-horizon 모델의 경우, 감가율이 중요한 의미를 가짐
- 수렴을 보장하기 위한 수학적인 기계적 장치
감가율(Discount factor)

벨만 기대 방정식(Bellman Expectation Equation)


- 현재 상태에서의 가치함수와 다음 상ㅊ태에서의 가치함수 간의 관계를 나타내는 방정식

정책에 대한 상태가치함수 값을 결정하는 법


- Markov Reward Process와 동일함

정책 평가(Policy evaluation)
- 정책이 주어졌을 때, 모든 상태에 대한 가치함수 값을 산출해내는 과정
최적 가치함수(Optimal value function)

- 상태 s로부터 최적정책을 다를 때 얻을 수 있는 기대 누적 보상합
- 감가율이 고려됨
최적 정책(Optimal policy)


MDP모델을 통해 구하려는 것은?
- 최적의 정책 도출
- 의사결정의 근거는?
- 벨만최적방정식
- 확정적인 동적계획법
- 일반적인 MDP 모델
- 벨만최적방정식
벨만최적방정식

Infinite horizon Model에서의 벨만최적방정식

- 정상성을 가정했기 때문에 가능

- 최적 정책: 모든 단계에서 앞서 도출한 최적 의사결정 규칙이 돌일하게 적용된 의사결정 모음
- recursive equation을 통해 구함
최적행동-가치함수
- 상태 s에서 행동 a를 결정한 이후, 최적정책을 따를 때 얻을 수 있는 기대값
- 누적보상 합의 최대값을 주는 행동을 판단



Data Scientist, Data Analyst