
프로젝트 개요
-
프로젝트 주제 및 선정 배경
주말을 포함한 연휴가 제주도 대중교통 이용량에 영향을 미칠지 분석 -
프로젝트 개요
2019년 9월 12~14일 추석과 2019년 9월 주말의 대중교통 이용량에 영향을 미치는지에 대해 분석
2019년 10월의 개천절, 한글날과 10월 주말이 대중교통 이용량에 동일한 영향을 미치게 될지 예측 -
활용 장비 및 재료(개발 환경 등)
Language : Python
Server : Naver Cloud Platform Server
IDE : Visual Studio Code, Jupyter
Library : Pandas , Numpy , CatBoost , XGBoost , LightGBM, scikit-learn(VotingRegressor Model)
프로젝트발표 (5/19)

발표 후 QNA 질문
1) random값을 너무 높게 설정해도, 0.71밖에 나오지 않았는걸로 보니 주제가 다른 팀과 달라 결과값이 당연히 안나오는게 맞는거처럼 보인다.
혹 주제가 잘못되었다는 생각은 받지 않았는지?
- 주제가 잘못되었다는 생각 보단, 결과값이 다른 조와 다르게 평균치보다 낮게 나온 것은 외부 데이터를 사용할 수 없어서 성능을 뽑아내지 못했던 한계가 있었음을 결론 내렸다.
추가적으로 외부 데이터인 제주시의 관광, 여행, 교통, 인구 데이터를 활용한다면 0.71보다 더 좋은 결과와 결론을 도출할 수 있을 것으로 기대한다.
프로젝트 수행 특징
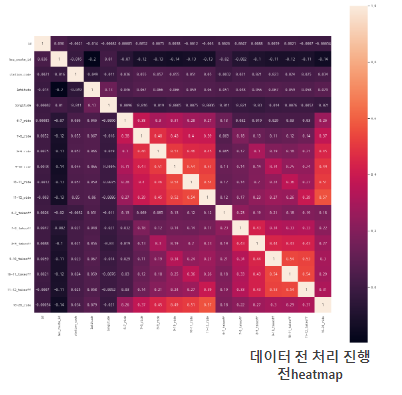
- 컬럼 편집 특징
- 데이터 heatmap에선 컬럼 편집할 부분을 찾기 어렵다 판단
- featurename 그래프에서 삭제할 컬럼을빼고는 모든 데이터의 연관성이 높음


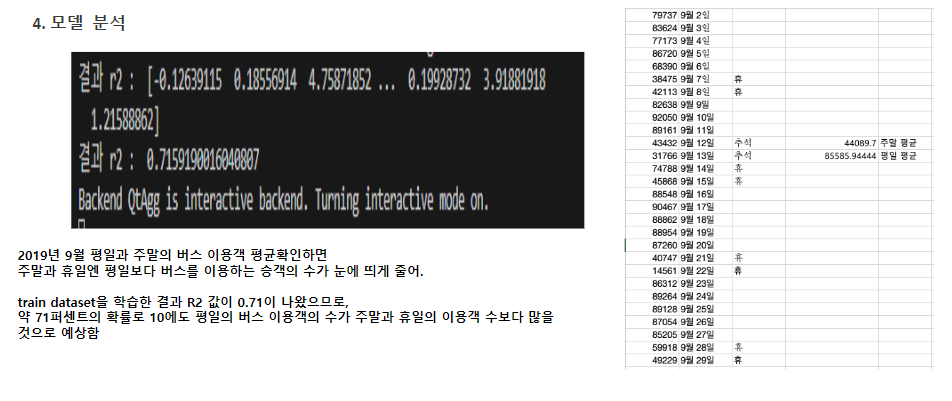
- 모델 성능 결론 : 초기 결과 값 0.60에서
- 최종 R2의 결과값 0.71을 통해 71%의 확률로 10에도 평일의 버스 이용객의 수가 주말과 휴일의 이용객 수보다 많을 것으로 예상 가능.
프로젝트 수행 과정
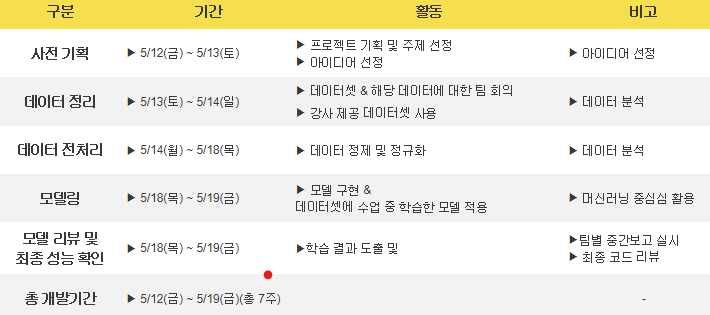
자체 평가 의견
이번 프로젝트를 통해 다양한 머신 러닝 모델을 경험하고 추후 분석 프로젝트 시 모델 선정에 도움이 될 것으로 예상되며, 프로젝트에서 겪은 어려움과 협력활동은 팀의 발전과 성장을 이끌었다고 생각한다.
회의 내용
1차
요약
19년 9월 명절 연휴 교통량을, 주말 평일 교통 이용량과
비교하여 제주도를 관광 도시라는 결론 유도가 가능할 듯 하다.
세부내용
- 2019년 9월 추석이 있음을 확인
= 명절이 껴있는 주와 그렇지 않은 주의 대중교통 이용량 비교해보잔 의견 - 명절이 껴있지 않은 주의 대중교통 이용량과 명절이 껴있는 주의 대중교통 이용량을 비교했을 때 명절이 포함된 주의 대중교통 이용량이 유의미하게 높은 수치를 보이면 명절이 제주도 방문객 수에 영향을 줄 수 있음 확인
- 공항에서 승차하는 승객의 수를 비교해보면 방문객/관광객과 연관짓기 좋음. 추석날에 따른 제주도 공항 근처 버스 이용객 수를 평소 퇴근 버스이용률과 비교하면 사람들이 제주도를 많이 방문하는 이유가 여행임을 확인 가능
= 명절이 있을 때랑 없을 때랑 제주도 관광객 수에 영향이 있고 확실한 차이를 비교
= 제주도를 관광 도시라는 결론 유도 가능 - 추가로, 제주도에서 관광지로 유명한 장소들이 있는 버스 정류장에서 하차하는 승객들의 수를 비교해보는 것도 좋은 방법일듯
2차
요약 : 전처리에 시간 소모가 상당하고 발표가 임박하니 모델 전처리, 모델 성능 향상 연구 파트로 구분하여 진행한다.
세부내용

- 팀원 1,2는 연구 모델을 votingRegressor로 택하고 성능 향상을 위해 다양한 시도를 통해 17일까지 마무리하기로 결정
- 전처리 과정을 다들 처음 하기에 최대한 빨리 하기로 5.16일 까지 마무리하기로 결정
3차
요약 : 전처리 오류로 인해 잘못된 데이터를 갖는 csv 파일을 발견하고, 모델 성능 향상을 위한 노력이 실패하여 추가적인 컬럼 수정을 통해 새로운 train.csv 파일을 생성하기로 결정했다.
세부내용
- 전처리 과정에서 잘못된 코드로 인해 컬럼 수정한 csv 파일이 잘못된 데이터임을 파악하고 다시 전처리르 통해 csv 파일을 생성해야 함을 발견
- 모델 성능 향상을 하여 최대한 좋은 코드값을 내기위해 노력했지만 실패
- 컬럼 수정을 추가적으로 하여 새로운 train.csv 파일을 생성하기로 승인
4차
요약 : 시간 대비 모델 성능 향상을 위해 random_state 값 조정을 작은 값과 큰 값으로 나눠 시도하여 최대치 값을 도출하기로 결정했다.
세부내용
- 모델 값이 향상이 되지 않아 고민한 끝에 randomstate 값을 향상시켜 1대안으론 100이하 2대안으론 1000이상을 내리자는 결론
