
퍼셉트론 (Perceptron) :
다층 퍼셉트론 (Multi-Layer Perceptron: MLP) :
기본 구조
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
# 1. 데이터
x = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17])
y = np.array([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17])
x_train = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
y_train = np.array([1,2,3,4,5,6,7,8,9,10,11,12])
x_test = np.array([ 17, 18, 19, 20])
y_test = np.array([ 17, 18, 19, 20])
#validation 실습 = training 검증
x_val = np.array([13, 14, 15, 16])
y_val = np.array([13, 14, 15, 16])
#2. 모델구성
model = Sequential()
model.add(Dense(14, input_dim=1))
model.add(Dense(50))
model.add(Dense(1))
# 3. 컴파일 훈련 = validation 실습2
model.compile(loss='mse', optimizer='adam')
model.fit(x_train, y_train, epochs=100, batch_size=1,
validation_data=[x_val,y_val],
verbose=0
) # - validation
# val_loss: 5.1012e-07
# loss : 1.5123705452424474e-06
# 21의 예측값 : [[20.998455]]
# 4. 예측 평가
loss = model.evaluate(x_test, y_test) # 앞써 훈련을 test 하는 코드
print('loss : ', loss)
result = model.predict([21])
print('21의 예측값 : ', result)
옵티마이저 (Optimizer) :
# 3. 컴파일, 훈련
model.compile(loss='mse', optimizer='adam')
adam이 최적합활성화 함수 (Activation Function) – Sigmoid, ReLU, Softmax :
# 2. 모델 구성
model = Sequential()
model.add(Dense(100,activation='linear', input_dim=8)) # 컬럼 수랑 동일
model.add(Dense(100,activation='relu'))
model.add(Dense(100,activation='linear'))
model.add(Dense(100,activation='relu'))
model.add(Dense(1,activation='linear'))
#2. 모델 구성(wine, iris)
model = Sequential()
model.add(Dense(100, input_dim=13))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(3, activation='softmax'))
#2. 모델 구성(cancer)
model = Sequential()
model.add(Dense(100, input_dim=30))
model.add(Dense(100))
model.add(Dense(50))
model.add(Dense(20))
model.add(Dense(1, activation='sigmoid')) 정확도 accuracy score
#artmax로 accuracy score 구하기
y_predict = model.predict(x_test)
y_predict = y_predict.argmax(axis=1)
y_test = y_test.argmax(axis=1)
argmax_acc = accuracy_score(y_test, y_predict)
print('argma_acc : ', argmax_acc)
걸린 시간 : 3.4314193725585938
loss : 0.10653208196163177
acc : 0.9629629850387573 ┐
argma_acc : 0.9629629629629629 ┘ Validation split
hist = model.fit(x_train, y_train,
epochs=100000,
batch_size=100,
validation_split=0.2,
callbacks=[EarlyStopping,mcp],
verbose=3)Overfitting
과적합 과정
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
import time
# 1.데이터
datasets = load_iris()
x = datasets.data
y = datasets.target
# one-hot-encoding 추가
from keras.utils import to_categorical
y = to_categorical(y)
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.6, test_size=0.2, random_state=100, shuffle=True)
# 2. 모델 구성
model = Sequential()
model.add(Dense(100, input_dim=4))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(3, activation='softmax'))
#3. 컴파일, 훈련
model.compile(loss='categorical_crossentropy',
optimizer='adam', metrics= 'accuracy')
#earlyStopping
from keras.callbacks import EarlyStopping, ModelCheckpoint
EarlyStopping = EarlyStopping(monitor= 'val_loss',
patience=100,
mode='min',
verbose=1,
restore_best_weights=True )
# restore_best_weights가 default 값이 False이기에
# 최적의 weight를 위해 True로 변경 필요
# Model Check Point
mcp = ModelCheckpoint(
monitor='val_loss',
mode='auto',
verbose=3,
save_best_only=True,
filepath='./_MCP/tf18_iris.hdf5'
)
# 저장 완료
# Epoch 833: val_loss did not improve from 0.00062
# Epoch 833: early stopping
# 1/1 [==============================] - 0s 23ms/step - loss: 0.0153 - accuracy: 1.0000
start_time = time.time()
model.fit(x_train, y_train,
epochs=100000,
batch_size=100,
validation_split=0.2,
callbacks=[EarlyStopping,mcp],
verbose=3)
end_time = time.time() - start_time # 시간에서 시작시간 빼면 남는시간이 걸린 시간
#4. 평가 예측
loss, acc = model.evaluate(x_test, y_test)
#시각화
# epochs=1000, patience=50,
# Epoch 859: early stopping
# 걸린 시간 : 21.07933807373047
# epochs=1000, patience=100,
#arallelism_threads for best performance.
# 걸린 시간 : 25.180851697921753
# epochs=100000, patience=100,
# Restoring model weights from the end of the best epoch: 867.
# Epoch 1003: early stopping
# 걸린 시간 : 26.899104595184326
#load 하고 결과
# 1/1 [==============================] - 0s 469ms/step - loss: 0.0153 - accuracy: 1.0000
Early Stopping
#earlyStopping
from keras.callbacks import EarlyStopping
EarlyStopping = EarlyStopping(monitor='val_loss',
patience=100,
mode='min',
verbose=1,
restore_best_weights=True )epochs 500 / patient 50
Epoch 194/500
Epoch 194: early stopping
걸린 시간 : 7.245402812957764epoch 500 /patient 100
Epoch 462/500
Epoch 462: early stopping
걸린 시간 : 15.146538019180298
save model
model.save('./_Save/tf15_cancer.h5') # h5로 모델 저장
Save weight
model.save_weights('./_Save/tf17_weight_cancer.h5')
Model Check Point
# Model Check Point
mcp = ModelCheckpoint(
monitor='val_loss',
mode='auto',
verbose=3,
save_best_only=True,
filepath='./_MCP/tf18_iris.hdf5'
)
CNN 시각화
import numpy as np
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
class_names = ['airplane','automobile','bird','horse','cat','deer','flog','dog','horse','ship','truck']
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i], cmap=plt.cm.binary)
plt.xlabel(class_names[y_train[i][0]])
plt.show()

CNN - MNIST
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D
#1. 데이터
datasets = mnist
(x_train, y_train), (x_test, y_test) = datasets.load_data()
#print (datasets.load_data())
#정규화(Nomalization) => 0~1사이로 숫자 변환
x_train, x_test = x_train/255.0, x_test/255.0
# 합성곱 레이어 전 차원수 맞춰주기
x_train = x_train.reshape(60000, 28, 28, 1)
x_test = x_test.reshape(10000, 28, 28, 1)
#2. 모델구성
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(4,4),
input_shape=(28,28,1)))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128,activation='relu'))
model.add(Dense(10,activation='softmax'))
#3. 컴파일, 훈련
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=10, batch_size=256)
# 4. 예측, 평가
loss, acc = model.evaluate(x_test, y_test)
print('loss : ', loss)
print('acc : ', acc)
----------------------------결과--------------
accuracy: 0.9768
loss : 0.07900256663560867
acc : 0.9768000245094299
# 2차 시도
accuracy: 0.9859
loss : 0.07456976920366287
acc : 0.9858999848365784CNN – Fashion MNIST
import numpy as np
from keras.datasets import fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i], cmap=plt.cm.binary)
plt.xlabel(class_names[y_train[i]])
plt.show()

CNN – cifar10
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPooling2D, Dropout
from keras.datasets import cifar10
import time
#1. 데이터
(x_train, y_train), (x_test, y_test) = cifar10.load_data() # x : 이미지 y : 라벨
print(x_train.shape, y_train.shape) #(50000, 32, 32, 3) (50000, 1)
print(x_test.shape, y_test.shape) #(10000, 32, 32, 3) (10000, 1)
#정규화
x_train = x_train/255.0
x_test = x_test/255.0
#2. 모델 구성
model = Sequential()
model.add(Conv2D(filters=64,
kernel_size=(3,3),
padding='same',
activation='relu', #1 : 흑백 3: 컬러
input_shape=(32,32,3)))
model.add(MaxPooling2D(4,4))
model.add(Dropout(0.3))
model.add(Conv2D(32,(4,4), padding='same', activation='relu'))
model.add(MaxPooling2D(4,4))
model.add(Dropout(0.3))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dense(128, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(10,activation='softmax'))
#3. 컴파일 훈련
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
#earlystopping
from keras.callbacks import EarlyStopping
EarlyStopping = EarlyStopping(monitor='val_loss',
patience=50,
mode='min',
verbose=3,
restore_best_weights=True
)
start_time = time.time()
model.fit(x_train, y_train, epochs = 50, batch_size= 256,
callbacks=[EarlyStopping],validation_split=0.2)
end_time = time.time() -start_time
#4평가 예측
loss,acc = model.evaluate(x_test, y_test)
print('loss : ', loss)
print('acc : ', acc)
print('걸린시간 : ', end_time)
------------------- 결과-----------------------
# loss : 0.8917421698570251
acc : 0.6832000017166138
걸린시간 : 369.0575511455536
# 결과 (epoch 15)
loss : 0.86269611120224
acc : 0.7134000062942505
걸린시간 : 561.7520892620087
# 결과 (epochs 10 )
loss : 0.8976953029632568
acc : 0.6869999766349792
걸린시간 : 300.7744891643524
# 결과(epoch15 )
loss : 1.160928726196289
acc : 0.5870000123977661
걸린시간 : 241.82087182998657
#결과 (epochs = 50, batch_size= 256)
loss : 0.9729036092758179
acc : 0.6543999910354614
걸린시간 : 927.4513821601868
CNN – cifar100

import numpy as np
from keras.datasets import cifar100
(x_train, y_train), (x_test, y_test) = cifar100.load_data()
class_names = ['apple', 'aquarium_fish', 'baby', 'bear', 'beaver', 'bed', 'bee', 'beetle',
'bicycle', 'bottle', 'bowl', 'boy', 'bridge', 'bus', 'butterfly', 'camel', 'can', 'castle',
'caterpillar', 'cattle', 'chair', 'chimpanzee', 'clock', 'cloud', 'cockroach', 'couch', 'crab',
'crocodile', 'cup', 'dinosaur', 'dolphin', 'elephant', 'flatfish', 'forest', 'fox', 'girl',
'hamster', 'house', 'kangaroo', 'computer_keyboard', 'lamp', 'lawn_mower', 'leopard', 'lion',
'lizard', 'lobster', 'man', 'maple_tree', 'motorcycle', 'mountain', 'mouse', 'mushroom', 'oak_tree',
'orange', 'orchid', 'otter', 'palm_tree', 'pear', 'pickup_truck', 'pine_tree', 'plain', 'plate',
'poppy', 'porcupine', 'possum', 'rabbit', 'raccoon', 'ray', 'road', 'rocket', 'rose',
'sea', 'seal', 'shark', 'shrew', 'skunk', 'skyscraper', 'snail', 'snake', 'spider', 'squirrel',
'streetcar', 'sunflower', 'sweet_pepper', 'table', 'tank', 'telephone', 'television', 'tiger',
'tractor', 'train', 'trout', 'tulip', 'turtle', 'wardrobe', 'whale', 'willow_tree', 'wolf', 'woman', -
'worm'
]
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10))
for i in range(100):
plt.subplot(10, 10, i+1)
plt.subplots_adjust(
wspace=0.5, hspace=0.5
)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(x_train[i], cmap=plt.cm.binary)
plt.xlabel(class_names[y_train[i][0]])
plt.show()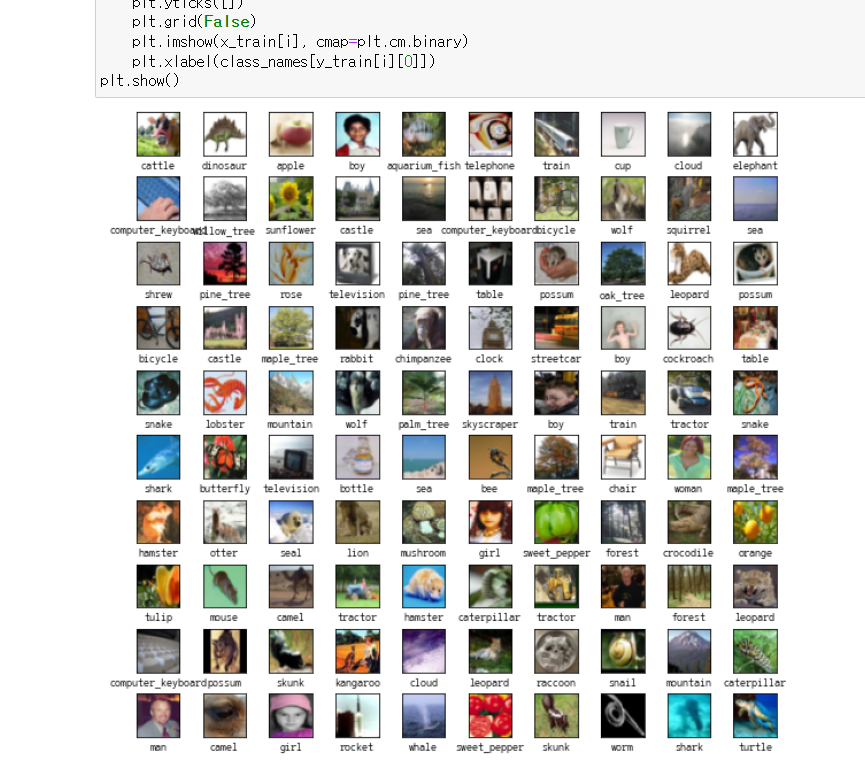
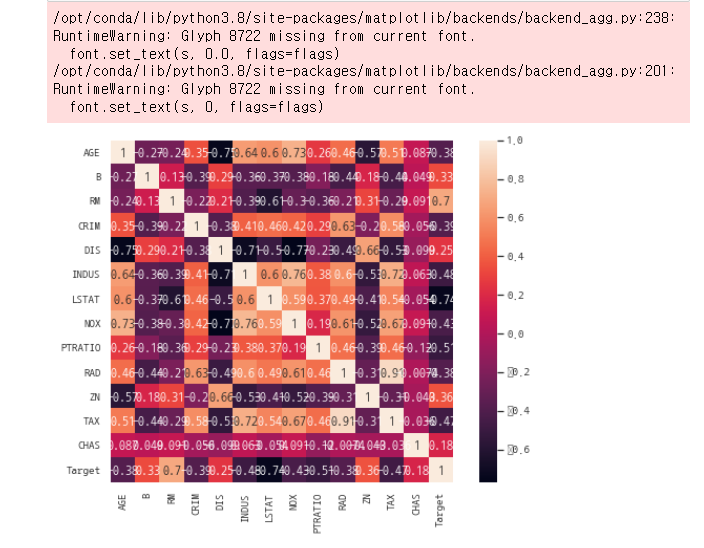
Pandas(Heatmap (matplotlib + seaborn))
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
#1. 데이터
path = './_data/'
datasets = pd.read_csv(path + 'Boston_house.csv')
print(datasets.columns)
print(datasets.head(7))
#head 명령어는 데이터의 첫head 출력해줌
Index(['AGE', 'B', 'RM', 'CRIM', 'DIS', 'INDUS', 'LSTAT', 'NOX', 'PTRATIO',
'RAD', 'ZN', 'TAX', 'CHAS', 'Target'],
dtype='object')
AGE B RM CRIM DIS INDUS LSTAT NOX PTRATIO RAD \
0 65.2 396.90 6.575 0.00632 4.0900 2.31 4.98 0.538 15.3 1
1 78.9 396.90 6.421 0.02731 4.9671 7.07 9.14 0.469 17.8 2
2 61.1 392.83 7.185 0.02729 4.9671 7.07 4.03 0.469 17.8 2
3 45.8 394.63 6.998 0.03237 6.0622 2.18 2.94 0.458 18.7 3
4 54.2 396.90 7.147 0.06905 6.0622 2.18 5.33 0.458 18.7 3
5 58.7 394.12 6.430 0.02985 6.0622 2.18 5.21 0.458 18.7 3
6 66.6 395.60 6.012 0.08829 5.5605 7.87 12.43 0.524 15.2 5
ZN TAX CHAS Target
0 18.0 296 0 24.0
1 0.0 242 0 21.6
2 0.0 242 0 34.7
3 0.0 222 0 33.4
4 0.0 222 0 36.2
5 0.0 222 0 28.7
6 12.5 311 0 22.9
x = datasets[['AGE', 'B', 'RM', 'CRIM', 'DIS', 'INDUS', 'LSTAT', 'NOX', 'PTRATIO',
'RAD', 'ZN', 'TAX', 'CHAS']]
y = datasets[['Target']]
print(x.shape, y.shape) #(506, 13) (506, 1)
x_train, x_test, y_train, y_test = train_test_split(
x,y,test_size=0.2, shuffle=True, random_state=77
)
print(x_train.shape, y_train.shape)# (404, 13) (404, 1)
print(x_test.shape, y_test.shape) # (102, 13) (102, 1)
# 상관계수 히트맵 - 만약 seaborn이 안될 경우 pip install seaborn
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font_scale = 1.2)
sns.set(rc = {'figure.figsize':(9,6)})
sns.heatmap(data = datasets.corr(), # 상관관계
square = True,
annot = True,
cbar = True
)
plt.show()
Tokenizer
# 데이터
docs = ['재밌어요', '지루하다', '숙면했다', '돈 낭비다', '최고에요', '꼭 봐라',
'또 보고 싶다', 'N회차 관람', '배우가 잘생겼다', '발연기다', '최악이다',
'후회한다.', '돈 아깝다', '글쎄요', '보다 나왔다', '망작이다', '연기가 어색하다', '차라리 기부한다',
'다음편 완전 기대된다', '다른 거 볼걸', '감동이다', '추천해요']
#긍정 1, 부정 0
labels = np.array([1,0,0,0,1,1,
1,1,1,0,0,
0,0,0,0,0,0,0,
1,0,1,1])
#Tokenizer
token = Tokenizer()
token.fit_on_texts(docs)
print(token.word_index)
'''
{'돈': 1, '재밌어요': 2, '지루하다': 3, '숙면했다': 4, '낭비다': 5, '최고에요': 6, '꼭': 7, '봐라': 8, '또': 9, '보고': 10, '싶다': 11, 'n회차': 12, '관람': 13, '배우가': 14, '잘생겼다': 15, '발연기다': 16, '최악이다': 17, '후회한다': 18, '아깝다': 19, '글쎄요': 20, '보다': 21, '나왔다': 22, '망작이다': 23, '연기가': 24, '어색하다': 25, '차라리': 26, '기부한다': 27, '다음편': 28, '완전': 29, '기대된다': 30, '다른': 31, '거': 32, '볼걸': 33, '감동이다': 34, '추천해요': 35}Embedding
from keras.layers import Dense, Embedding, LSTM
model = Sequential()
model.add(Embedding(500,16, input_length=100))
#imdb.load_data(num_words=500) = input 500,
model.add(LSTM(8))
model.add(Dense(1, activation='sigmoid'))
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 16) 8000
lstm (LSTM) (None, 8) 800
dense (Dense) (None, 1) 9
=================================================================
Total params: 8,809
Trainable params: 8,809
Non-trainable params: 0
_________________________________________________________________Rueters – 로이터 46개의 뉴스 토픽 기사(다중분류)
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM, Dropout
from keras.datasets import reuters
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import time
#1. 데이터
(x_train, y_train), (x_test, y_test) = reuters.load_data(
num_words = 10000
)
print(x_train.shape, x_test.shape)
#(8982,) (2246,)
print(y_train.shape, y_test.shape)
print(len(np.unique(y_train)))
# (8982,) (2246,)
# 46
print('뉴스 기사의 최대 길이 : ', max(len(i) for i in x_train))
print('뉴스 기사의 평균 길이 : ', sum(map(len,x_train)) /len(x_train))
# 뉴스 기사의 최대 길이 : 2376
# 뉴스 기사의 평균 길이 : 145.5398574927633
# pad_sequences
x_train = pad_sequences(x_train, padding = 'pre', maxlen=100)
x_test = pad_sequences(x_test, padding = 'pre', maxlen=100)
print(x_test.shape, y_test.shape) #((2246, 100) (2246,)
print(x_train.shape, y_train.shape)#(8982, 100) (8982,)
#2. 모델 구성
model = Sequential()
model.add(Embedding(input_dim = 10000, output_dim = 100))
model.add(LSTM(128, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.35))
model.add(Dense(64, activation='relu'))
model.add(Dense(46, activation='softmax'))
model.summary()
# Model: "sequential_3"
# _________________________________________________________________
# Layer (type) Output Shape Param #
# =================================================================
# embedding_3 (Embedding) (None, None, 100) 1000000
# _________________________________________________________________
# dropout_12 (Dropout) (None, None, 100) 0
# _________________________________________________________________
# lstm_3 (LSTM) (None, 128) 117248
# _________________________________________________________________
# dropout_13 (Dropout) (None, 128) 0
# _________________________________________________________________
# dense_9 (Dense) (None, 64) 8256
# _________________________________________________________________
# dropout_14 (Dropout) (None, 64) 0
# _________________________________________________________________
# dense_10 (Dense) (None, 64) 4160
# _________________________________________________________________
# dropout_15 (Dropout) (None, 64) 0
# _________________________________________________________________
# dense_11 (Dense) (None, 46) 2990
# =================================================================
# Total params: 1,132,654
# Trainable params: 1,132,654
# Non-trainable params: 0
# _________________________________________________________________
# 컴파일 훈련
#earlyStopping
from keras.callbacks import EarlyStopping
EarlyStopping = EarlyStopping(monitor='val_loss',
patience=100,
mode='min',
verbose=1,
restore_best_weights=True )
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',metrics='accuracy')
model.fit(x_train, y_train, epochs=200, batch_size=512, verbose=1, callbacks=[EarlyStopping], validation_split=0.3)
#평가 예측
loss, acc = model.evaluate(x_test, y_test)
print('loss : ', loss)
print('acc : ', acc)
# loss : 1.9554272890090942
# acc : 0.5026714205741882
#epochs : 200
# loss : 2.339970588684082
# acc : 0.3971504867076874
Imdb - 긍정 부정 영화 리뷰(이진분류)
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM
from keras.datasets import imdb
from keras.preprocessing.text import Tokenizer
from keras_preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
#!. 데이터
(x_train, y_train), (x_test, y_test) = imdb.load_data(
num_words = 10000
)
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape)
#` (25000,) (25000,) (25000,) (25000,)
#최대 길이와 평균 길이
print('리뷰의 최대 길이 : ', max(len(i) for i in x_train))
#리뷰의 최대 길이 : 2494
print('리뷰의 평균 길이 : ', sum(map(len,x_train)) /len(x_train))
#리뷰의 평균 길이 : 238.71364
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print(x_train.shape, y_train.shape) # (25000,) (25000, 2)
print(x_test.shape, y_test.shape) # (25000,) (25000, 2)
# pad_sequences
x_train = pad_sequences(x_train, padding = 'pre', maxlen=100)
x_test = pad_sequences(x_test, padding = 'pre', maxlen=100)
print(x_test.shape, y_test.shape) #(25000, 100) (25000,)
print(x_train.shape, y_train.shape)# (25000, 100) (25000,)
