💡 PPO
-
PPO(Proximal Policy Optimization)는 2017년에 소개된 강화학습 알고리즘의 일종이다.
-
강화학습은 기본적으로 아무것도 모르는 상태에서 직접 다 수행해보고 방황하며 지식을 얻고 최적의 결정을 내려나가는 학습을 의미한다.
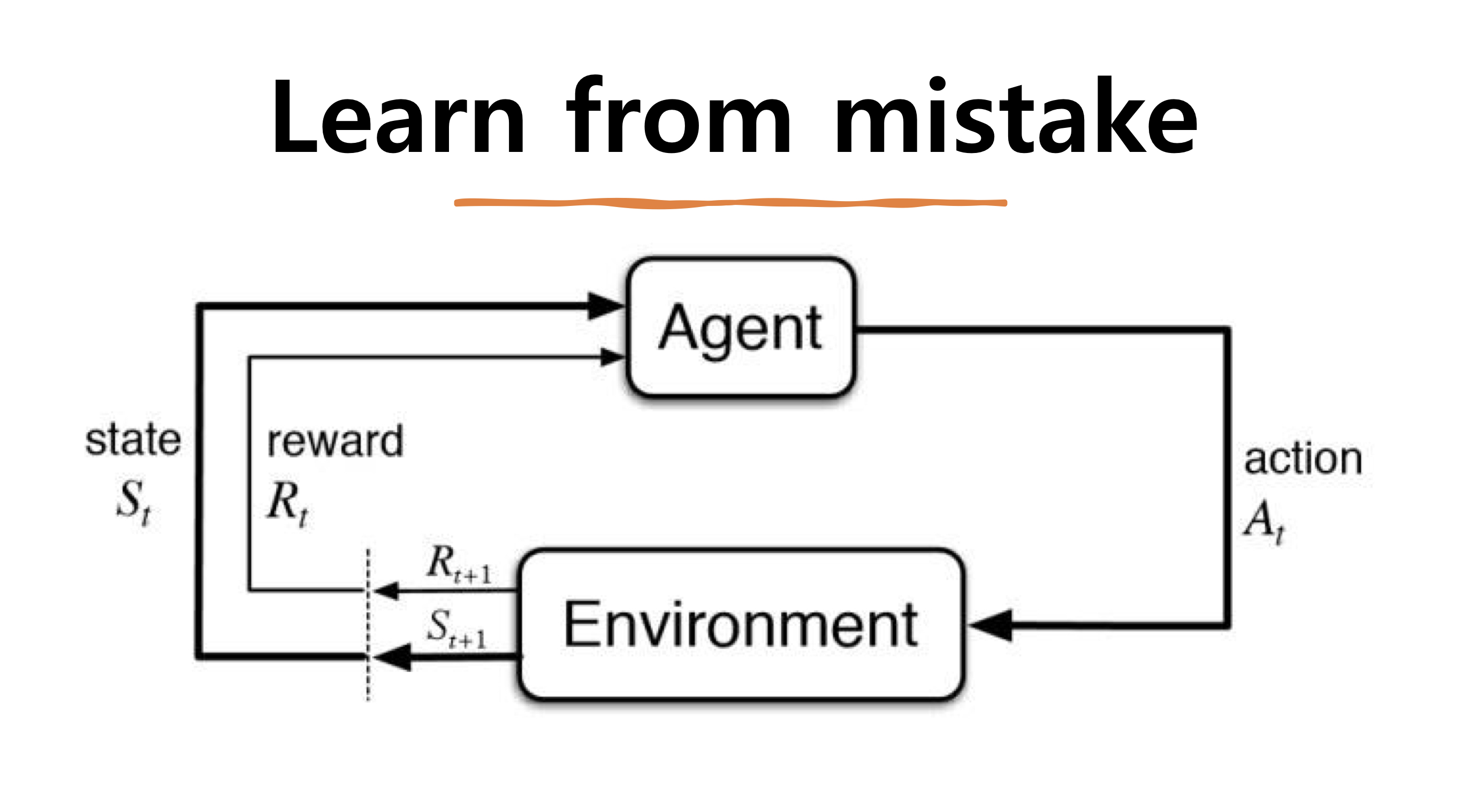
출처 | [HUFS RL] 강화학습 : Reinforcement Learning: PPO (Proximal Policy Optimization)
📍 기본적인 용어
아타리 게임을 통해서 강화학습을 처음 구현해보는 경우가 많기 때문에 아래에 위의 게임의 상황을 가정하고 예시를 함께 들었다.
- Agent : 학습하는 대상으로 환경속에서 행동하는 주체를 의미한다.
→ 아래 네모박스를 움직이는 주체 - State : 현재 Agent가 판단을 내리기 위해 반영되는 상태
→ 박스가 n개 깨져있고, 공은 네모박스와 얼마정도 떨어진 상태 - Environment : Agent가 속해있는 환경으로 Agent의 행동에 따라 변화하기도 한다.
→ 벽돌깨기 아타리 게임 - Action : Agent가 Environment속에서 현재 State일 때 취하는 행동을 의미한다.
→ 오른쪽으로 5번 움직이기 - Reward : Agent가 현재 취하는 행동에 따라 주어지는 보상을 의미한다. 결국 에이전트가 학습하는 목적은 이 보상을 최대화하기 위함이다. 다만 꼭 한번 행동을 했을 때 한번 주어지는게 아니거나 미래에 여러 행동의 결과가 한꺼번에 반영되어 주어지는 경우가 있다. 이것이 근본적으로 강화학습을 어렵게 만드는 요인이다.
→ 게임의 점수
PPO는 여러 강화학습 중에서도 Model-free, Policy Optimization, On-Policy 방법에 속한다. 여기서 Policy는 현재 State에 따른 Action의 확률분포를 나타내는 것이다. 즉 최적의 Policy(= 현재 상황에서 해야하는 가장 좋은 행동을 아는 것)를 찾는 것이 목적이다.
📚 Model-free vs Model-based
Model-based는 Environment의 다음 State와 Reward가 어떨지에 대해서 Agent가 어느정도 알고 Action을 선택하는 것을 의미한다. Model-free는 현재 Model에 대한 정보가 전혀 없는 상태에서 Onteraction을 통해서 하나씩 학습해나가는 것을 의미한다.
📚 Policy optimization vs Q-learining
Policy Optimization은 말그대로 Policy 함수( )를 모델링하고 학습과정에서 이를 최적화 시키는 것을 의미한다. Q-learning은 Q함수(Q(s,a) = 현재 State s에서 Action a를 한 뒤 끝까지 진행했을 때 얻는 리워드)를 직접 모델링하고, 이를 최적화 시킨다. 둘 모두 현재 State s에서 어떤 Action을 해야할지 판단하는 최적의 정책을 얻고자 한다는 점에서는 동일하다.
📚 On-Policy, Off-Policy
On-Policy는 실제로 행동을 하고 있는 가장 최신 버전의 Policy로 수집된 데이터만 Policy 업데이트에 사용하는 방식이다. Off-Policy는 이전 정책으로 탐색한 결과까지 학습 데이터로 사용하는 방식이다.
하지만 강화학습은 그 특성상 명확하게 위와 같은 태그를 분리하기가 쉽지 않다. PPO도 On-Policy로 설명하지만 실제 학습시에는 Off-Policy와 같이 업데이트 된다. PPO는 TRPO라는 이전의 강화학습 알고리즘을 계산하기 쉽고 학습 안정성을 높이는 방향으로 개선시킨 알고리즘이다.
요약하자면 기존에 TRPO는 믿을 만한 구역 안에서만 Policy가 업데이트 되도록 Constraint를 거는데, 이것이 TRPO가 상당히 복잡한 계산식을 갖도록 했다. 하지만 PPO는 이를 Clipped Surrogate Objective를 사용하여 더 간단한 형태로 풀어내어 학습해 최적의 성능을 내었다.
[출처 | 딥다이브 Code.zip 매거진]
