https://dacon.io/competitions/official/236046/overview/description 대회를 참여하며 리뷰한 논문이며
https://www.youtube.com/watch?v=n_FDGMr4MxE 을 참조했습니다.
U-Net : Convolutional Networks for Biomedical Image Segmantation
- 2015년 MICCAI 에서 발표되었습니다.
[배경지식1] 이미지를 인식하는 다양한 방법
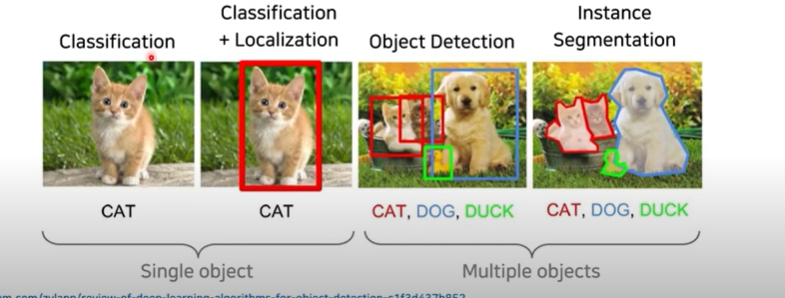
- Object Detection : 여러 개의 객체가 존재할 수 있는 상황에서 각각의 객체에서 Classification & Localization
- Instance Segmentation : 각각의 픽셀마다 어떤 클래스인지 예측
SEMANTIC SEGMENTATION
- 정의 : 정의 : 이미지 내에 있는 각 물체(object)들을 의미 있는(semantic)
- goal : to predict class labels for each pixel in the image
- 이미지가 주어졌을 때, (높이x너비x1) 크기를 가지는 한 장의 분할 맵(segmentation map) 을 생성한다
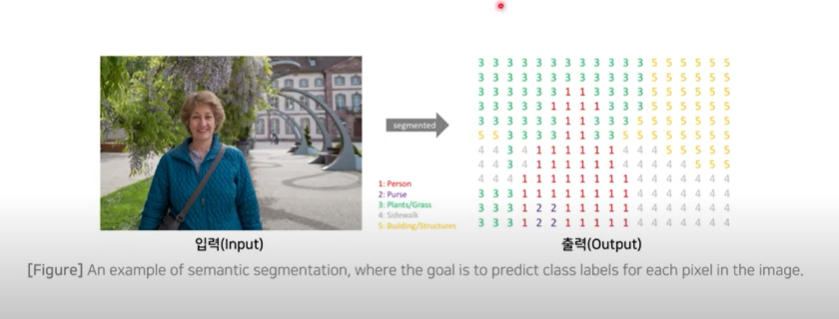
- 이미지와 같은 해상도를 가지지만 각 픽셀들이 label의 번호를 부여받는다
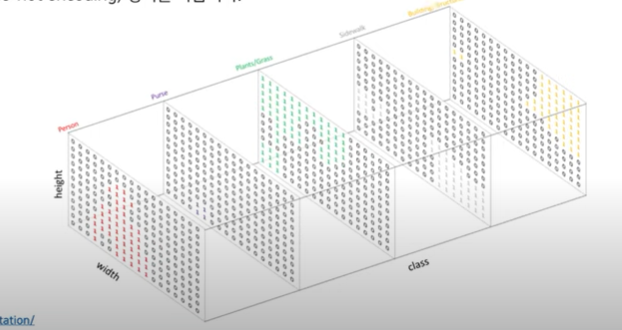
- 각 픽셀마다 N개의 클래스에 대한 확률을 뱉어야 하므로, 정답은 (높이X너비XN) 형태를 갖는다 → 각 픽셀마다 원-핫 인코딩 형식을 따른다.
- 분할 작업을 위한 데이터 세트 생성 비용은 매우 비싸다
- 각 픽셀마다 어던 클래스로 분류되는지 일일이 지정해야 하기 떄문
- 하지만 일반적인 CNN 분류 모델의 형식을 크게 바꾸지 않고 학습할 수 있다.
- 일반적으로 딥러닝 네트워크 구조가 크게 어렵지 않은 편이라는 장점
[배경지식2] CNN 의 동작 과정
- CNN에서는 필터(filter) 혹은 커널(kernel)이라고 불리는 것을 사용한다
- 각 필터는 입력에서 특정한 특징(feature)을 잡아내어 특징 맵(feature map) 을 생성한다
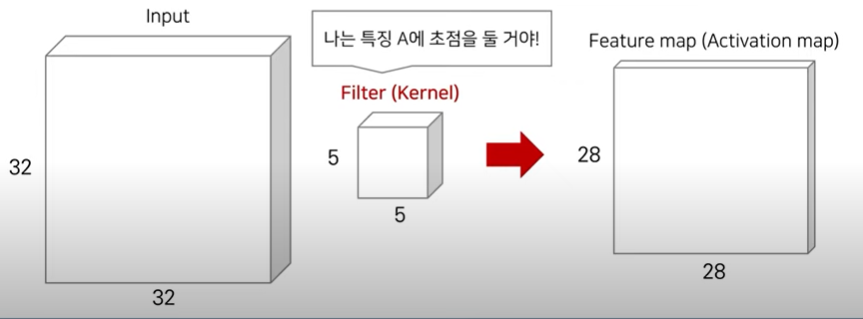
- 하나의 필터는 슬라이딩 하면서 컨볼루션 연산을 통해 특징 맵(feature map)을 계산한다.
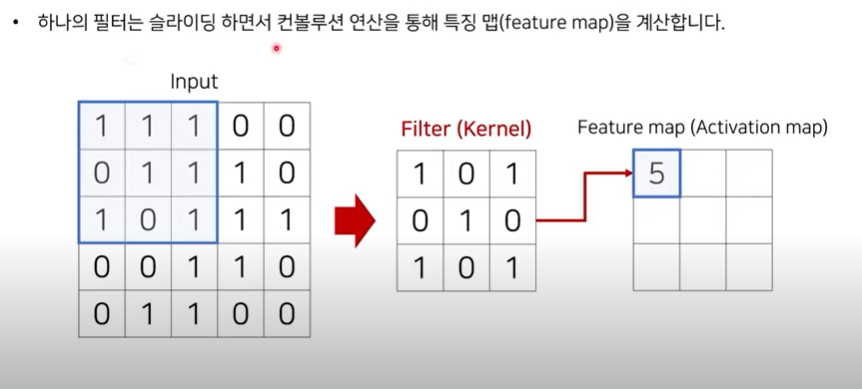
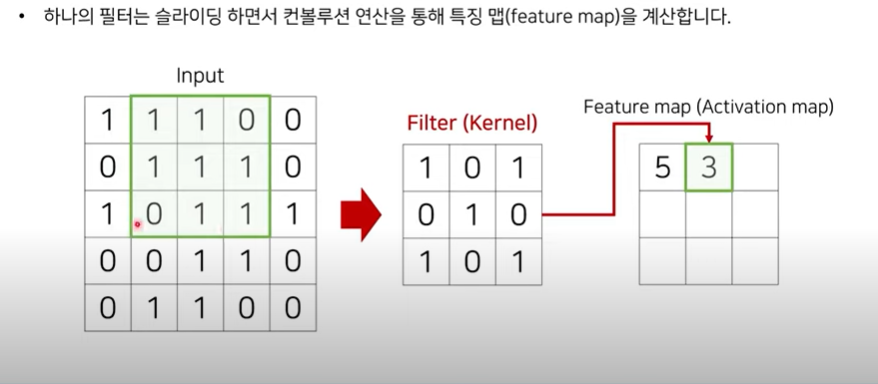
- input X Filter = Feature map
- (32x32x3) x (5x5x3) input 과 filter 의 채널 사이즈는 같아야 한다.(너비와 높이는 달라도 괜찮다)
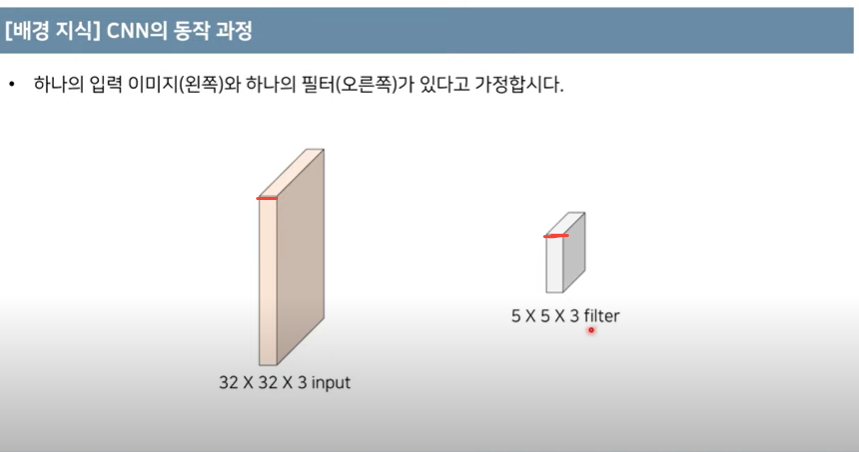
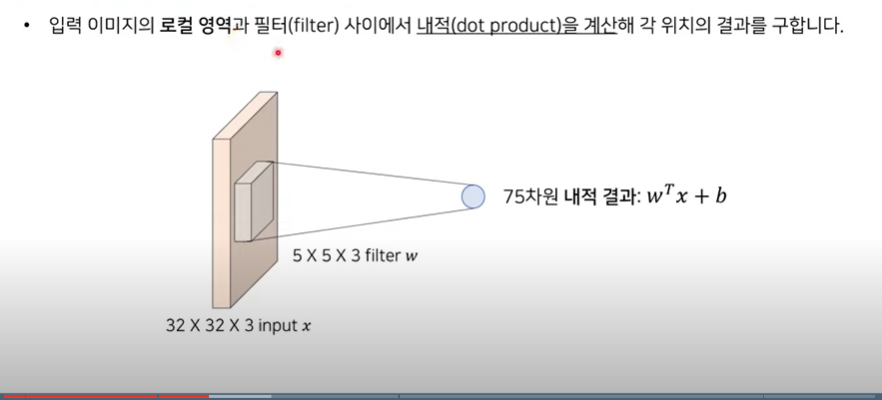
입력 이미지의 로컬 영역과 필터 사이에서 내적을 계산해 각 위치의 결과를 구한다.
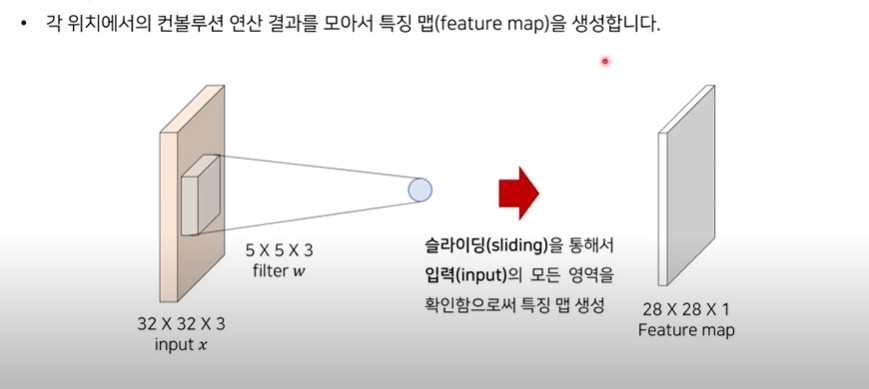
- 제일 왼쪽 위에서 한 칸 씩 슬라이드 한다 → 가장 오른쪽에 닿기 까지 28번의 연산이 가능하다 (?)
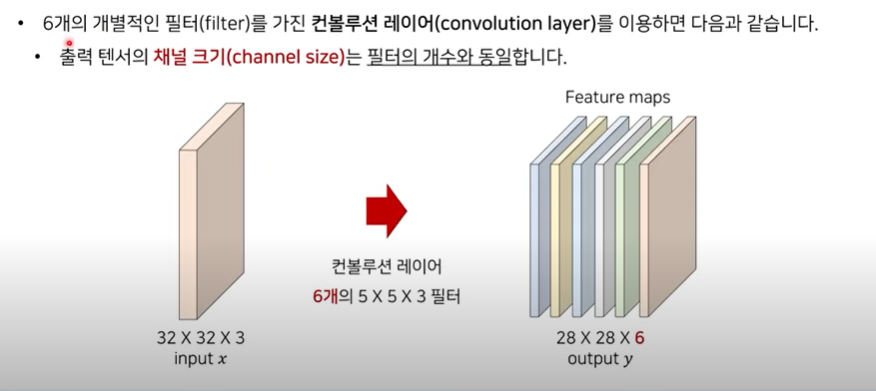
- input tensor 가 존재한다고 할 때, 각각의 필터가 개별적으로 입력 텐서에 적용된다 → 총 6개의 activation map 이 생성된다.
- 레이어를 여러 개 중첩해서 모델을 만들면 → 채널은 커지고 너비와 높이는 감소
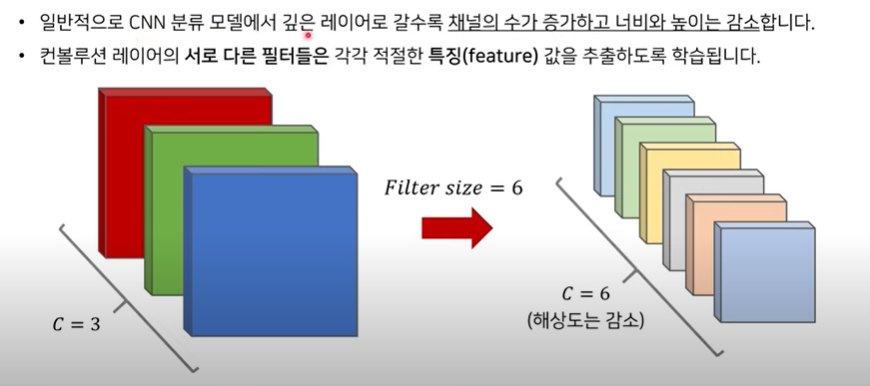
- 필터의 개수가 6개라면 output으로 출력되는 레이어의 개수도 6개!
- 컨볼루션 레이어의 서로 다른 필터들은 각각 적절한 특징 값을 추출하도록 학습된다.
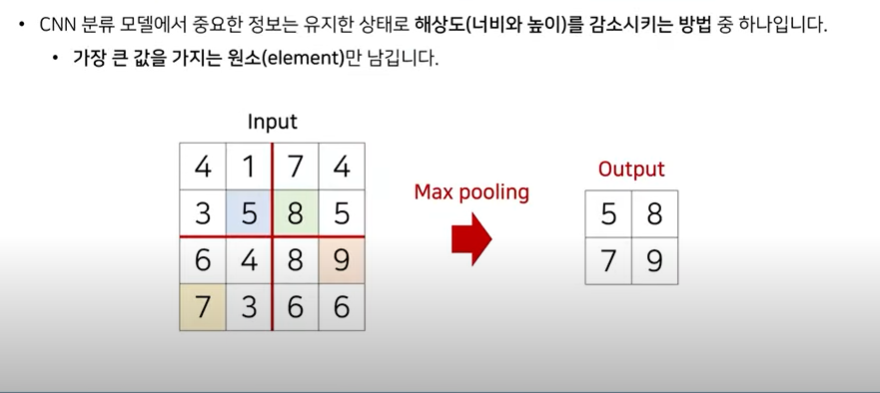
- Max Pooling : 별다른 가중치, 파라미터 없이 너비와 높이를 쉽게 줄일 수 있다.
- 가장 큰 값을 가지는 원소만 남긴다.
- 특정한 특징 맵이 있을 때, 중요한 정보만 유지한 상태로 해상도만 줄여서 원하는 값 사용 가능

- VGG 네트워크

- 작은 크기의 레이어를 깊게 쌓아서 우수한 성능을 도출
- input → conv1, conv2 → maxpooling → conv1, conv2 → maxpooling → fc → softmax
- 결과적으로 1000개의 layer return
- 224 x 224 x 64 :
conv 필터를 통해 채널의 수를 64로 늘려준다 maxpooling을 통해 너비와 높이를 두 배씩 줄여준다,conv 레이어를 통해 채널의 수 128로 증가maxpooling을 통해 너비 높이 <해상도> 두 배씩 줄여주고(56x56),conv 레이어를 통해 채널의 수 256 로 증가 (56x56x256)- 결과적으로 fc 레이어를 거쳐 총 1000개의 클래스에 대하여 확률값을 도출

[논문 소개] U-net
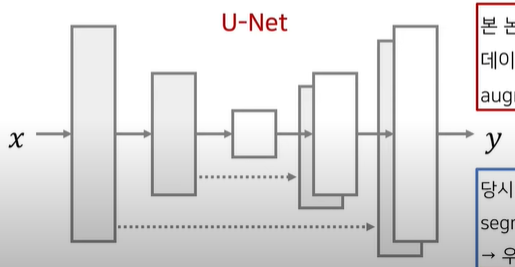
- 본 논문에서는 U자형으로 생긴 네트워크인 U-Net 아키텍처를 제안한다.
- 수축 경로 (contracting path) : 이미지에 존재하는 넓은 문맥(context) 정보를 처리한다.
- 확장 경로 (expanding path) : 정밀한 지역화 (precise localizxation) 이 가능하도록 한다
- 본 논문에서는 레이블 정보가 있는(annotated) 데이터가 적을 때
효율적인 데이터 증진(data augmentation) 기법을 제안한다. - 일반적인 분류 task 에서는 해상도가 계속 줄어들어서 마지막에는 클래스의 개수와 같은 차원을 갖도록 하는 것이 일반적
- semantic segmentation 에서는 단순히 분류 결과를 구하는 것이 아니라, 입력 이미지와 같은 해상도를 가지는 출력 이미지가 나와야 하기 때문에 다른 구조로 만들어야 한다.
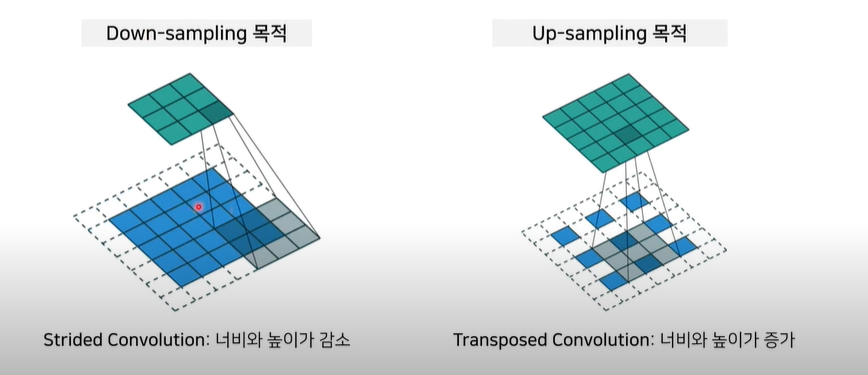
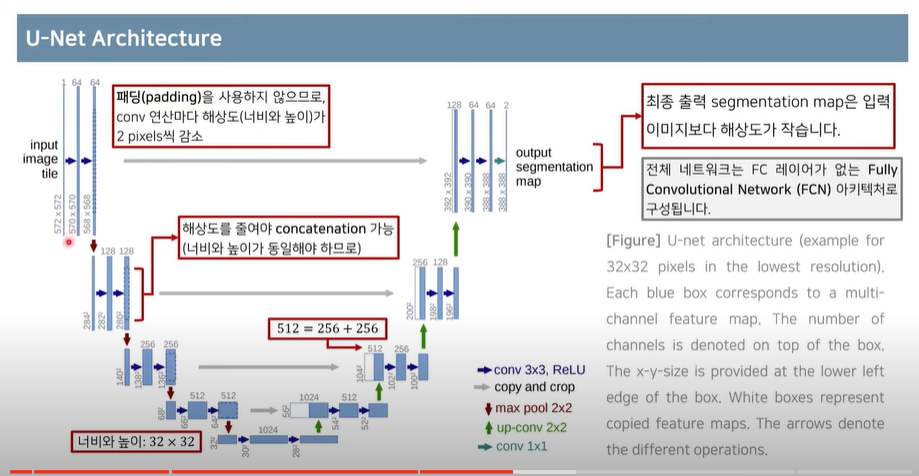
- 해상도가 감소 후 다시 증가 하는 과정

앞부분에서 간단히 해상도를 줄인 후에 뒷부분에 붙이는 과정이 필요하다

- 일부러 입력을 조금 더 크게 넣는다.
- 이미지 경계 부분은 extrapolation 사용 → 미러링 활용

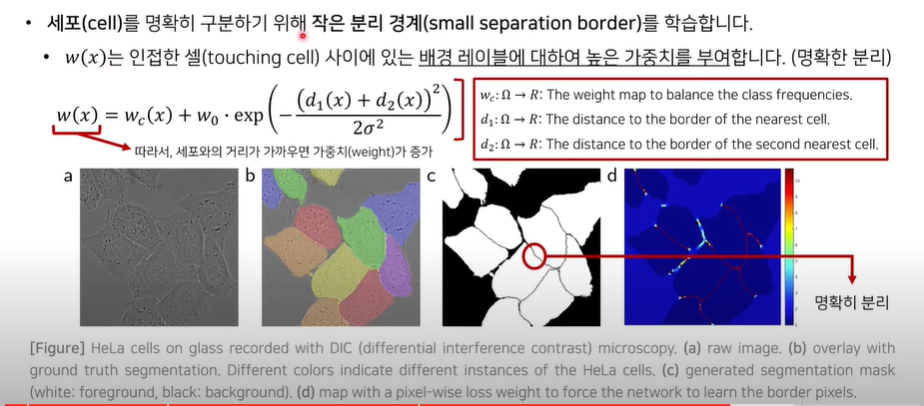
- 세포와의 거리가 가까우면 높은 가중치를 부여한다. → 확실히 배경임을 분리
[U-Net 의 데이터 증진]
- 추가적으로 Elastic Deformation 방법을 사용 → 보다 높은 정확도
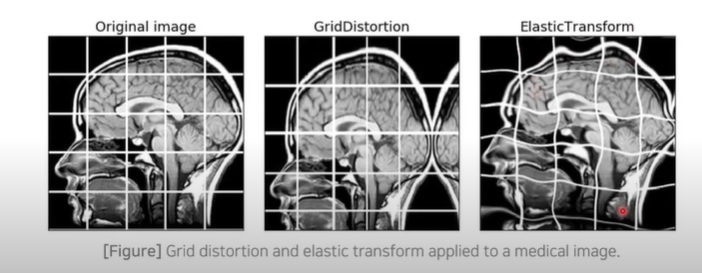
- 비선형적으로 변형을 가한다.
- EM segmentation 대회의 데이터 세트로 평가를 진행한다.
- Warping error 를 기준으로 정렬한 결과 U-Net
[FeedBack]
결과적으로 Unet을 모델링에 활용하지는 않을 예정이지만, CNN 및 비전 기반 딥러닝 모델의 전반적인 모델 구조와 augmentation에 대한 아이디어를 얻어갈 수 있었다.

ML/DL/NLP