지난 1월 2일부터 1월 30일까지 학회 멤버들과 함께 데이콘에서 주관하는 <포디블록 구조 추출 AI 경진대회> 에 참여했었다. 대회가 끝난 이후 시도한 방법들에 대해 다뤄보고자 한다.
앞서 나는 이전까지 컴퓨터 비전을 다뤄본 경험이 전무했기 때문에 여러가지로 많이 어려웠고 그 만큼 경진대회를 참여하며 많이 배울 수 있었다.
[결과]

- 결과적으로 우리는 대략 400명 이상이 참여한 대회에서 41등 정도를 달성해 상위 10% 내에 들 수는 있었다. 하지만 상위권 분들의 코드가 공유되고, 우리 팀도 동일하게 떠올렸지만 제대로 구현하지 못한 아이디어들을 실제로 구현해 적용한 것을 보고 많은 아쉬움이 남기도 했다.
- 그럼에도 불구하고, 결과적으로 컴퓨터 비전에 대해 얇지만 넓게 배울 수 있었고 GradCAM 을 사용해보며 '설명가능한' 딥러닝을 이해하기 위해 노력했다는 것에 의의를 두어본다.
- 더불어 해당 경험을 기반으로 나는 컴퓨터 비전 랩실에 학부연구생 컨택 메일을 보내는 자신감을 얻을 수 있었고, 다음 학기부터 해당 랩실에서 학부연구생을 경험할 수 있는 감사한 기회를 얻기도 했다 :).
서론이 길었던 것 같다. 해당 대회에 대해 간략하게 설명하자면 다음과 같다.
[주제]
2D 이미지 기반 블록 구조 추출 AI 모델 개발
[설명]
- 본 경진대회에서는 2D 이미지 내 포디블록의 10가지의 블록 패턴들의 존재 여부를 분류하는 Multi-Label Classification을 수행해야합니다.
- 또한 실험 환경에서 촬영된 이미지가 학습 데이터로 주어지며, 평가(테스트 데이터)는 실제 환경에서 촬영된 이미지로 이루어집니다.
[데이터 톺아보기]
- 정리하자면 우리는 쌓여진 포디블록 구조물을 보고, A-J 까지 존재하는 블록의 구조를 찾아 내야 하는 'Multi-Label' Image Segmentation을 수행해야 하는 것이다.
A 구조

B 구조

C 구조

D 구조

E 구조

F 구조

G 구조

H 구조

I 구조

J 구조

위의 구조에 대하여

- 다음과 같은 구조물의 구조를 Multi-Label 로 라벨링 하는 것이다. 해당 사진의 경우, 다양한 방법으로 이미지 전처리를 위해 우리 생각에 Image Segmentation 과 유사한 모습으로 보이도록 이미지를 전처리한 사진이다.
- 하지만 해당 사진에서도 확인 가능하듯, 뒤에 널부러진 몇몇 블록들까지도 함께 따져서 이러한 부분들이 정확도를 낮춘 것이 아닌가 하는 생각이 든다.
[사용한 기법]
전처리
- 아이디어 : 숨겨진 블록 또한 인식해서 찾아낼 수 있도록 3d 모델링을 통해 직접 이미지를 생산하자.
-> 'test 데이터'에 숨겨진 블록이 있다고 인식하는 것부터 data leakage 가 아닌가? 더불어 3d 모델링은 컴퓨터 비전의 모델 성능 개선이라는 해당 대회와 맞지 않는 것 같다.
-> 그런데 1등의 코드를 확인하니 3d 모델링을 사용했더라.. 음.. - train / test 데이터셋의 배경 누끼를 따자
-> 주어진 test 데이터셋의 경우 어지러운 배경으로 인해 모델이 구조물에 집중을 못하는 것 같았다.
-> 라이브러리를 활용해 다양한 방법으로 배경의 누끼를 따고, 각각 모델링을 진행해 앙상블 하는 방식으로 진행했다. - rmbg 라이브러리 (누끼 딴 png), green (segmentation 기법과 시각적으로 유사한), blur (뒷 배경 블러 처리), black(흑백), noise(뒷 배경 노이즈) 총 5개의 데이터셋을 사용해 모델링을 진행했다.
augmentation
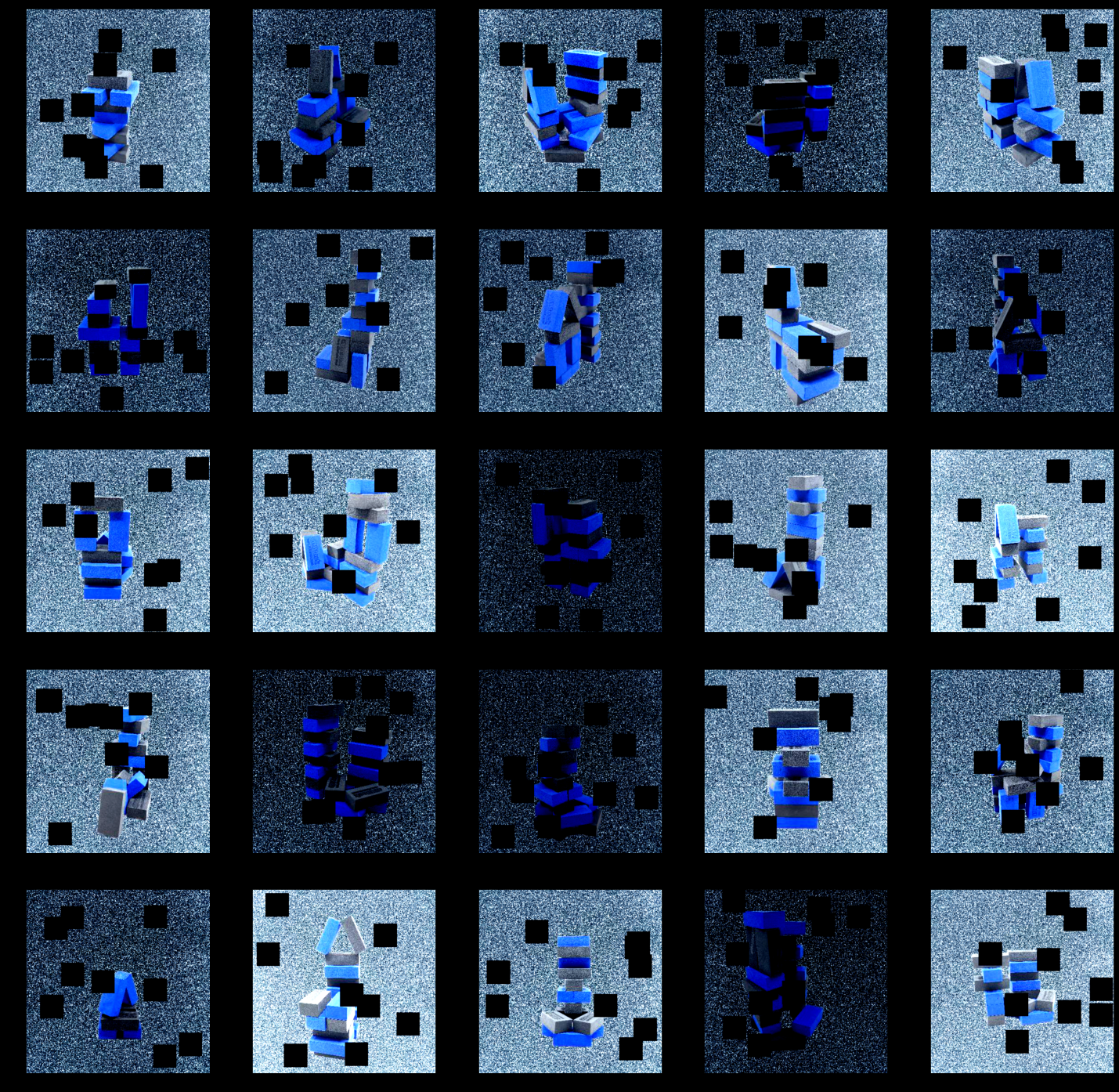
- 좌우반전 / 밝기 대비 / 검은 박스 생성에 대한 아이디어를 가지고
- horizontalflip / randombrightnesscontrast / coarsedropout 의 증식을 진행했다.
- 그런데 결과적으로 앙상블 시 원본 데이터가 성능이 더 좋았다는 ..
모델링
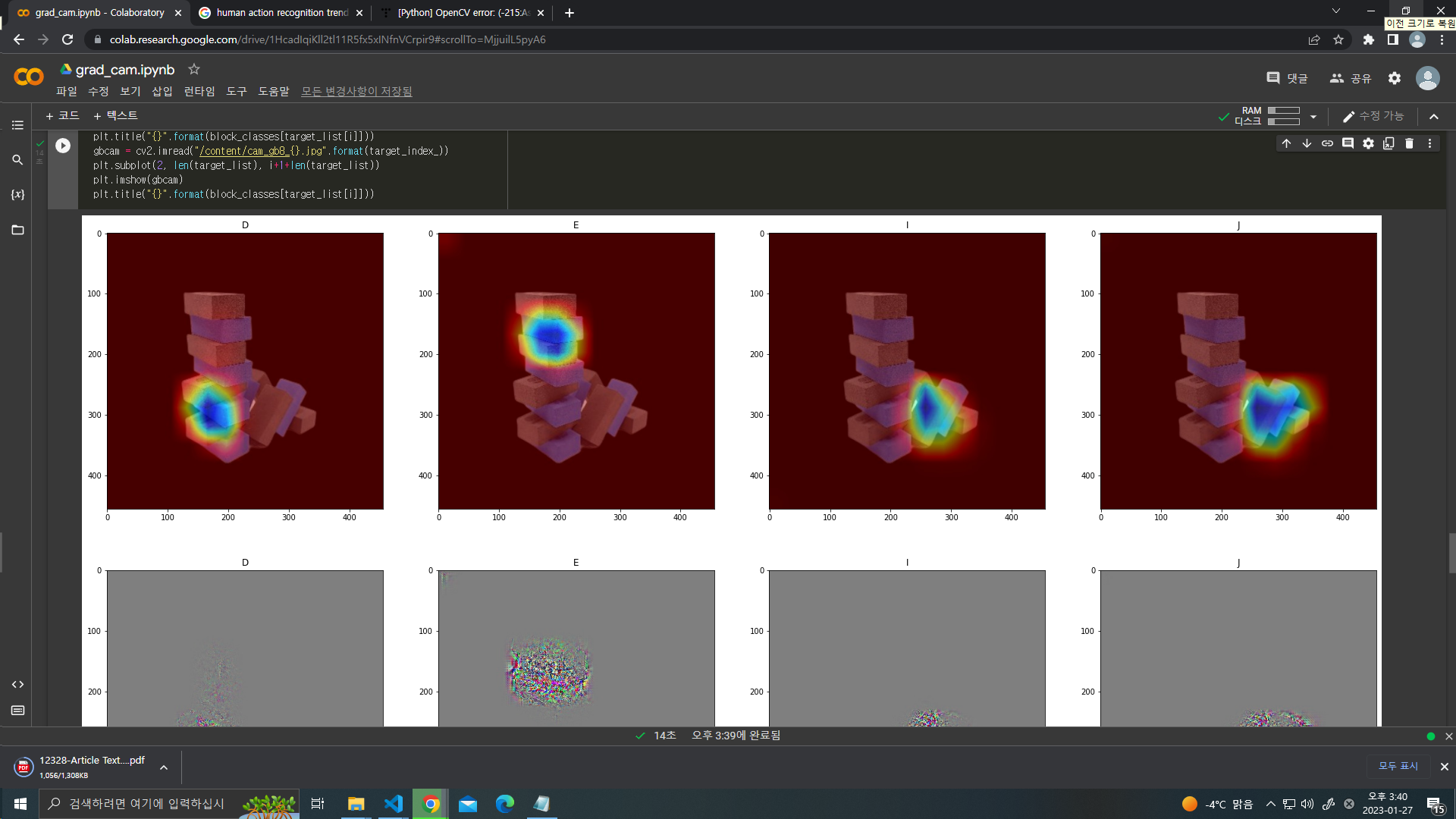
- 우선, 우리는 모델 적용시 모델의 구조를 알 수 없기 떄문에 정확도가 낮아지는 원인을 찾기가 어려웠고, 따라서 GradCAM 을 활용해 어떤 구조를 찾고 / 못 찾는 지 판별해 보고자 했다.
정리하자면 - B 2개 -> E 가 되어 B와 E를 제대로 구분하지 못한다.
- A와 B가 유사해 제대로 구분하지 못한다. 였는데, 어떻게 해결방법을 찾지는 못했다.
- 모델링의 경우 엄청 다양하게 기존 BASELINE 이었던 efficientnetb3 이외에도 efficientnetb1-8, transformer 계열의 다양한 사전 학습 모델들, resnet, 기존 모델에 추가 layer 쌓기, 스케줄러 / 옵티마이저 / 손실함수 바꾸기 등 다양한 방법을 사용했지만
BASELINE 코드가 가장.. 성능이 좋았다. - 결국 단일 efficientnetb3에 대하여 데이터셋들을 학습시키고 각각의 모델에 대해서 가중치를 두어 앙상블 하는 방식을 취했다. 앙상블의 경우에도 가중치에 따라, 또 threshold 에 대해 다른 성능이 보여졌는데 우리의 경우 가중치 5(rmbg library) 3(green) 1(noise) 1(black) 1(blur) 였을 때, threshold 의 경우 각각 모델의 prob >0.5 였을 때 성능이 괜찮게 나와 그렇게 진행했다.
[결론]
- 어렵다! 94% 성능의 벽을 꺠는 것이 너무 어려웠고 성능이 오르지 않아 힘들었다. 학습 한 번에도 너무 오랜 시간이 소요되어 지치기도 했다. 그럼에도 불구하고 파이토치의 ㅍ도 모르던 내가 전처리부터 모델링, 모델의 구조(아주 얇게) 까지 알 수 있게 해주었던 대회였다. 우리 팀원들 또한 비전을 공부해 보지 않은 사람들임에도 불구하고 수상자와 동일한 생각을 바탕으로 모델을 구현하고자 했다는 것이 놀랍고 대단하게도 느껴진다.
- 이렇게 컴퓨터 비전을 맛본 이후로 베이스가 없음에 대해 답답함을 느끼고 더 다양하게 배워보고 싶어 자대 데이터사이언스학부의 비전 랩실 교수님께 학부 연구생 컨택을 드렸고 감사하게도 받아주셔서 다음 학기부터 학부 연구생으로 컴퓨터 비전을 배우게 되었다.
- 아직은 비전이 어렵기도 하고, 컴공의 영역이라는 생각이 강해 이 영역에 발을 들이는 것에 대해 고민이 크지만 배우고 싶다면 배워야지! 라는 생각으로 시도해 보고자 한다. 앞으로 뭘 하고 살아야 할 지 고민이 크다.

ML/DL/NLP