
YOLOv4: Optimal Speed and Accuracy of Object Detection
논문리뷰를 해보겠다.
https://colab.research.google.com/drive/15b-V7ATZL2sYCM27_WF5EvT9thBfsO6i?usp=sharing
먼저 논문을 읽기전, 기본적인 object detection관련 내용은 위 코랩에 정리가 잘 되어있으니 참고하길 바람.
1. Introduction
최근 성능 좋은 네트워크들은 real time이 아니며 많은 GPU를 필요
GPU 하나만 사용하고, real time으로 동작하는 네트워크를 만들자
기여
효율적이고 강력한 객체탐지모델
BoF, BoS 사용
최첨단 방법으로 단일 GPU로도 가능
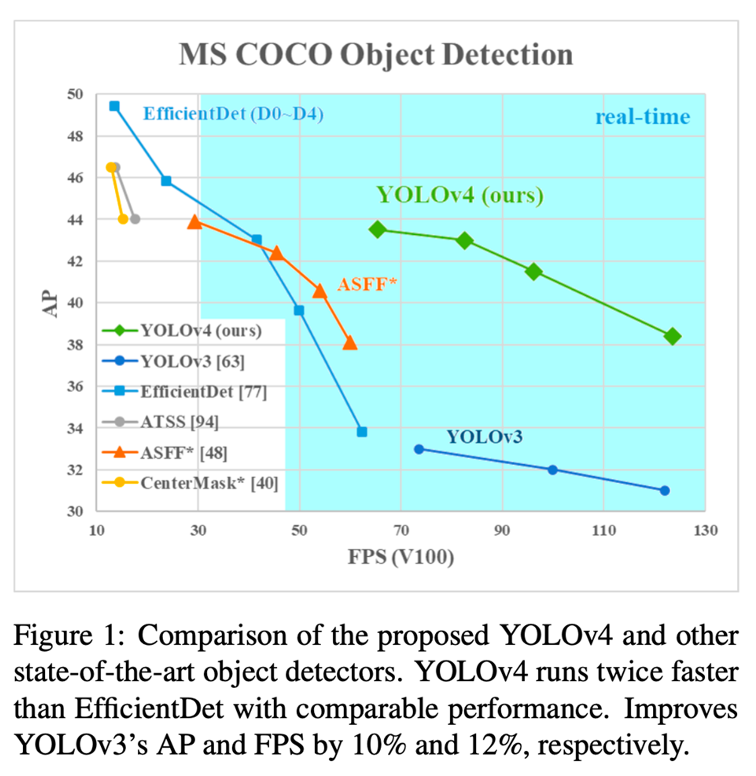
객체 탐지기의 비교
YOLOv4는 비슷한 성능으로 EfficientDet보다 두배 빠름
YOLOv3보다 AP와 FPS가 각각 10%, 12% 향상된 모습
2. Related work
2.1. Object detection models
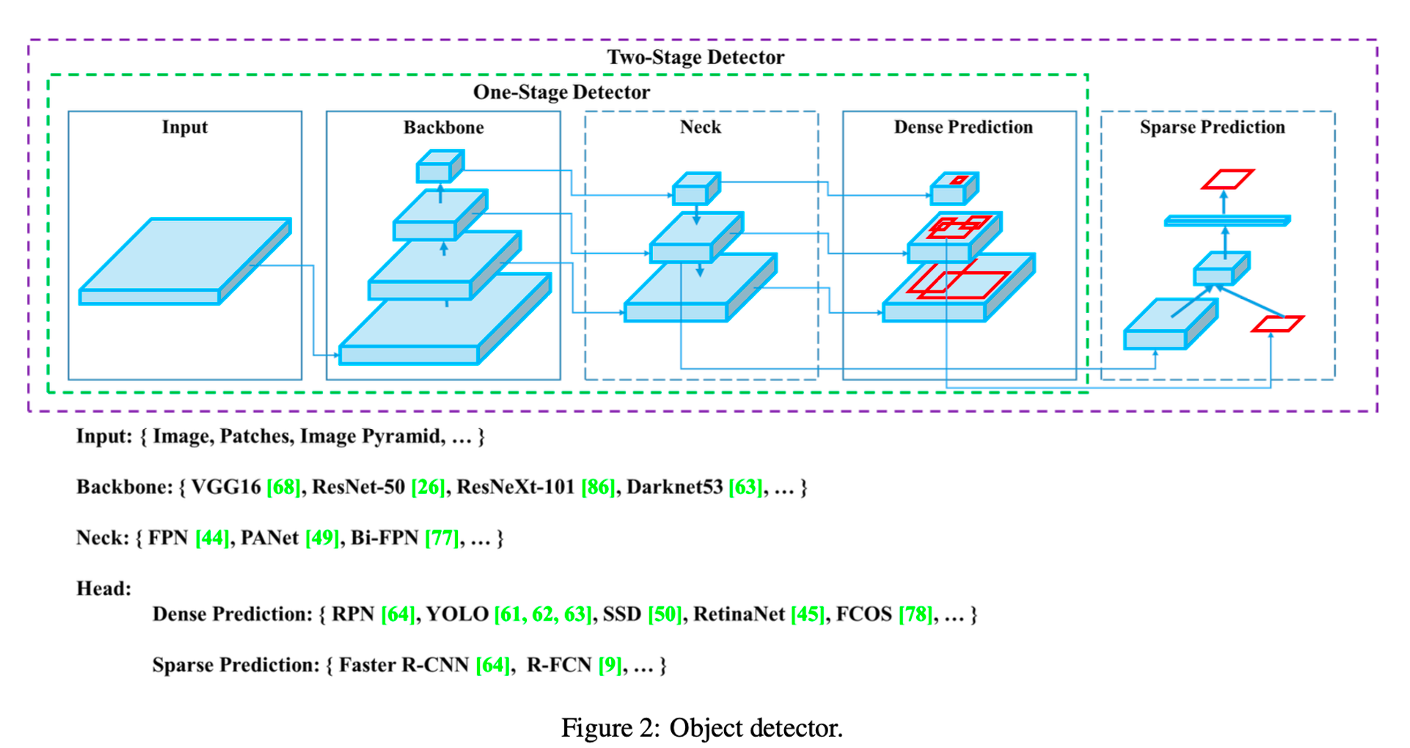
백본:
ImageNet에서 사전 훈련
헤드:
객체의 클래스 및 경계 상자를 예측하는 데 사용
넥:
백본과 헤드 사이에 일부 레이어를 삽입된 것
2.2. Bag of freebies
BOF(Bag of freebies)란: inference 비용을 늘리지 않고 정확도를 향상시키는 방법
2.3. Bag of specials
BOS(Bag of specials)란: inference 비용을 조금 높이면서 정확도를 크게 향상시키는 방법
3. Methodology
3.1. Selection of architecture
목표는
입력 네트워크 해상도, 컨볼루셔널 레이어 수, 매개변수 수(필터 크기 2 필터 채널/그룹) 및 레이어 출력 수(필터) 간의 최적의 균형을 찾는 것
수용 필드를 증가시키기 위한 추가 블록을 선택하고 다양한 검출기 레벨에 대해 다양한 백본 레벨에서 최상의 매개변수 집계 방법을 선택하는 것
아래 표를 참고해서 CSPDarknet53을 backbone으로 삼음
parameter 수가 많음에도 불구하고 속도가 빠르며, receptive field의 크기도 작지 않기 때문
추가모듈은 SPP, 넥은 PANet, 헤드는 YOLOv3의 헤드로 삼음

3.2. Selection of BoF and BoS
BoF와 BoS 중 몇 개를 고름
3.3. Additional improvements
단일 GPU 사용에 더 적합하게 만들기 위해
추가 설계 및 개선해주었음
새로운 데이터 증강 방법인 Mo- saic과 SAT(Self-Adversarial Training) 도입
유전자 알고리즘을 적용하면서 최적의 하이퍼파라미터를 선택
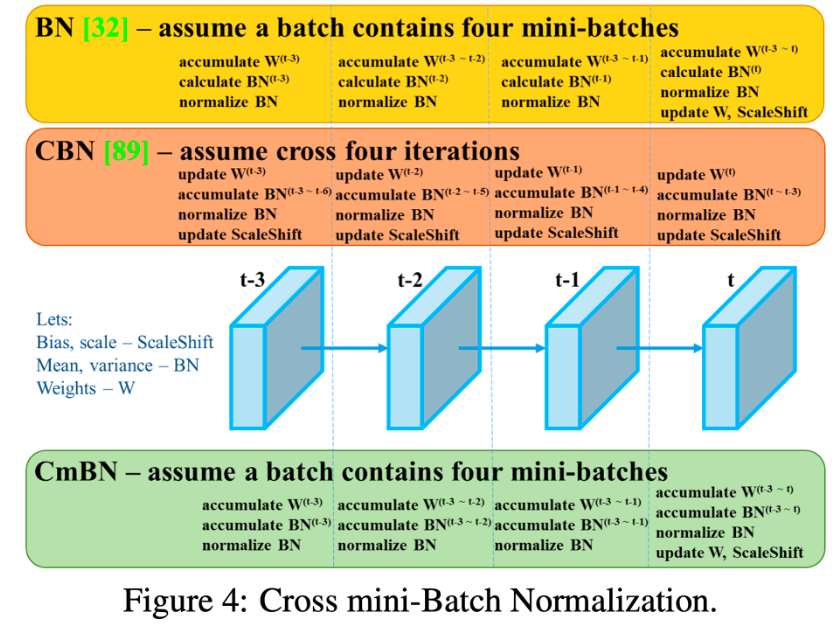
일부 기존 방법을 수정함: modified SAM, modified PAN, Cross mini-Batch Normalization(CmBN)

CmBN: CBN의 수정된 버전으로 single batch 내에서 mini-batches 사이에 대한 통계를 수집
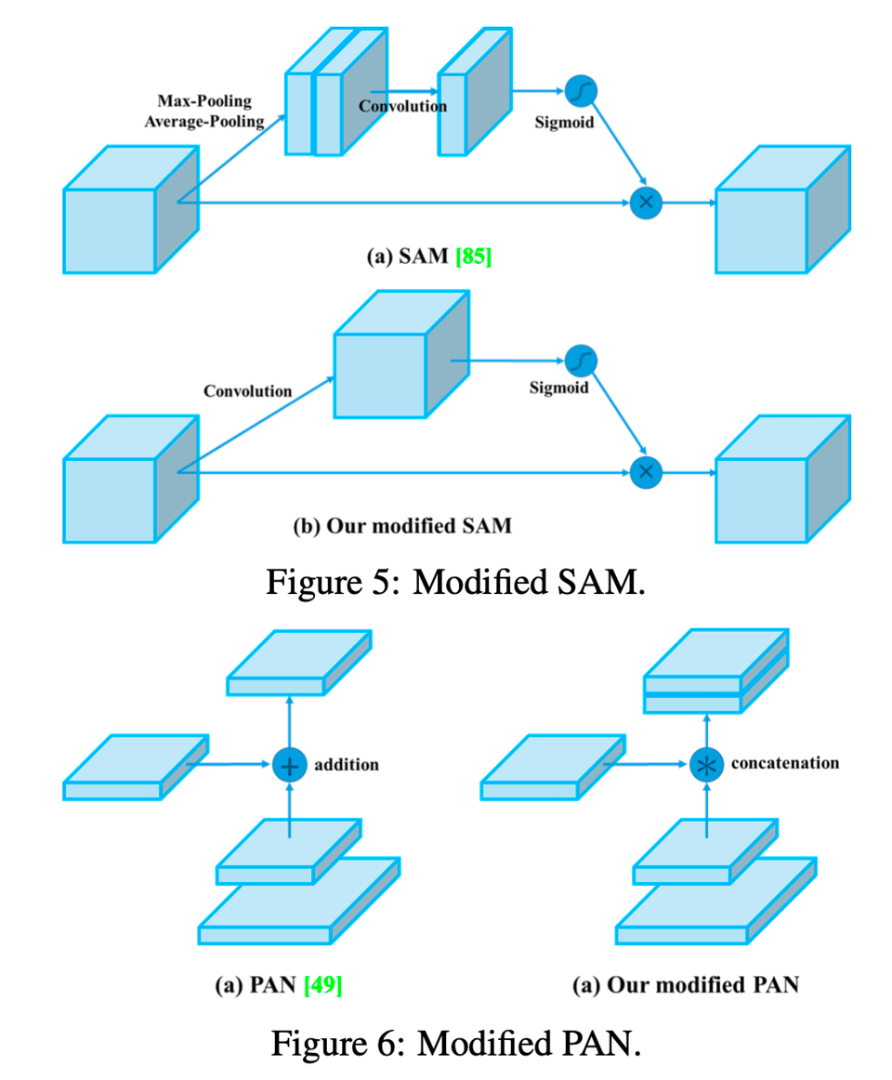
Modified SAM: Spatial-wise attention에서 point-wise attension으로 변경
Modified PAN: Shortcut connection을 concatenation으로 교체
3.4. YOLOv4
최종적으로…
Backbone: CSPDarknet53
Neck: SPP , PAN
Head: YOLOv3
그외…

4. Experiments
4.2. Influence of different features on Classifier training
Classfier training 할 때 서로 다른 feature가 미치는 영향에 대하여 연구
각 feature들 :
Class label smoothing
different data augmentation techniques
bilateral blurring
MixUp, CutMix and Mosaic
different activations (Leaky-ReLU, Swish, Mish)

Data augmentation은 CutMix, Mosaic, Label Smoothing를 사용하고,
추가로 Mish activation을 사용하니 성능이 더 좋았음
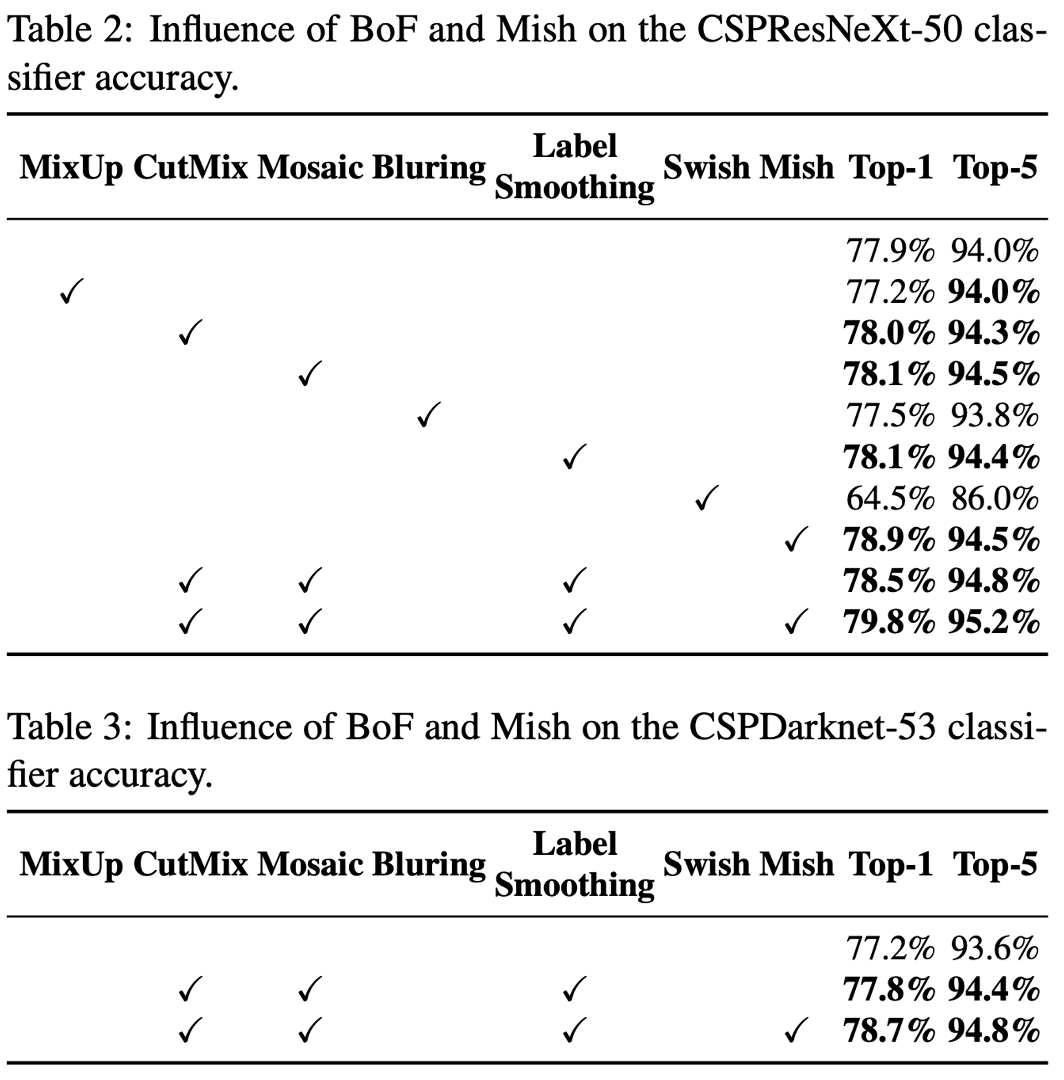
4.3. Influence of different features on Detector training
서로 다른 BoF-detector가 detector training accuracy에 주는 영향을 보기 위하여 추가적인 연구를 진행하였으며, FPS에 영향을 주지 않으면서 detector accuracy를 높히는 다양한 feature들에 대한 연구를 통하여 BoF list를 크게 확장함
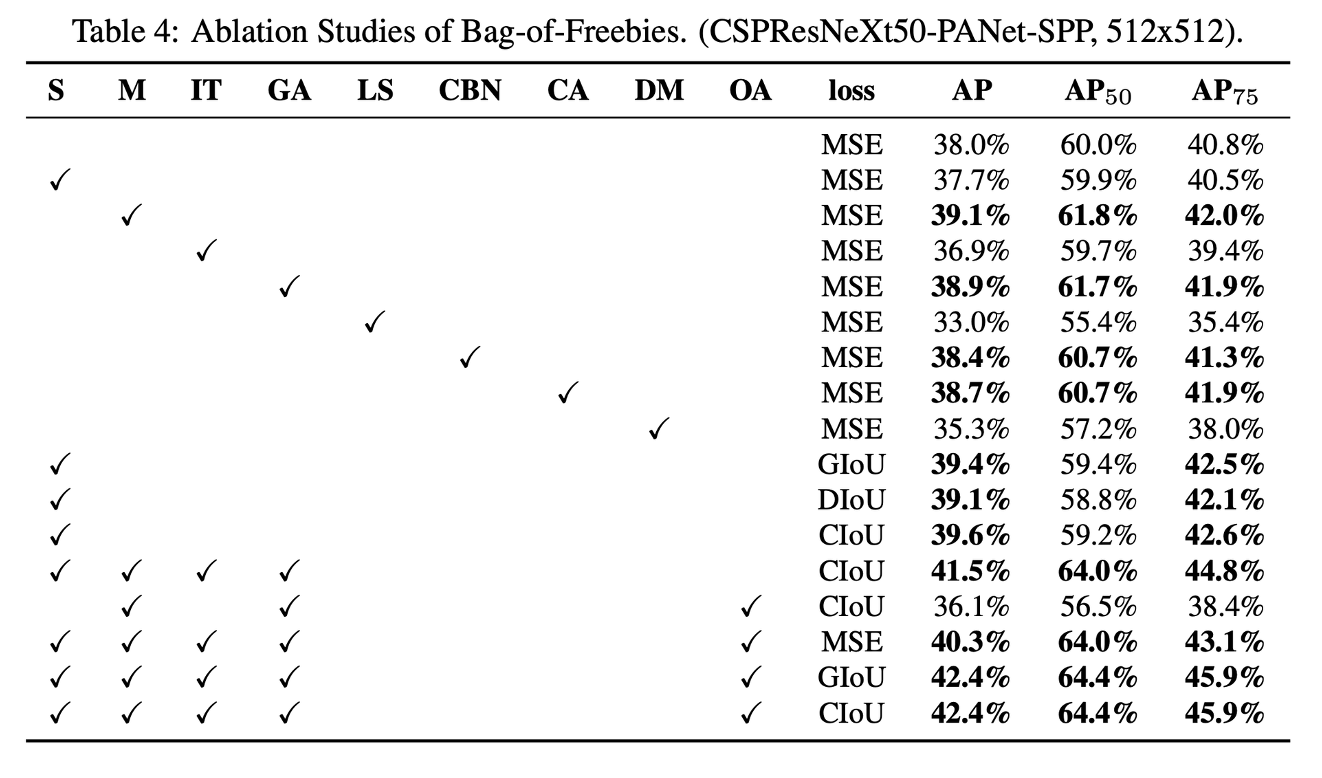
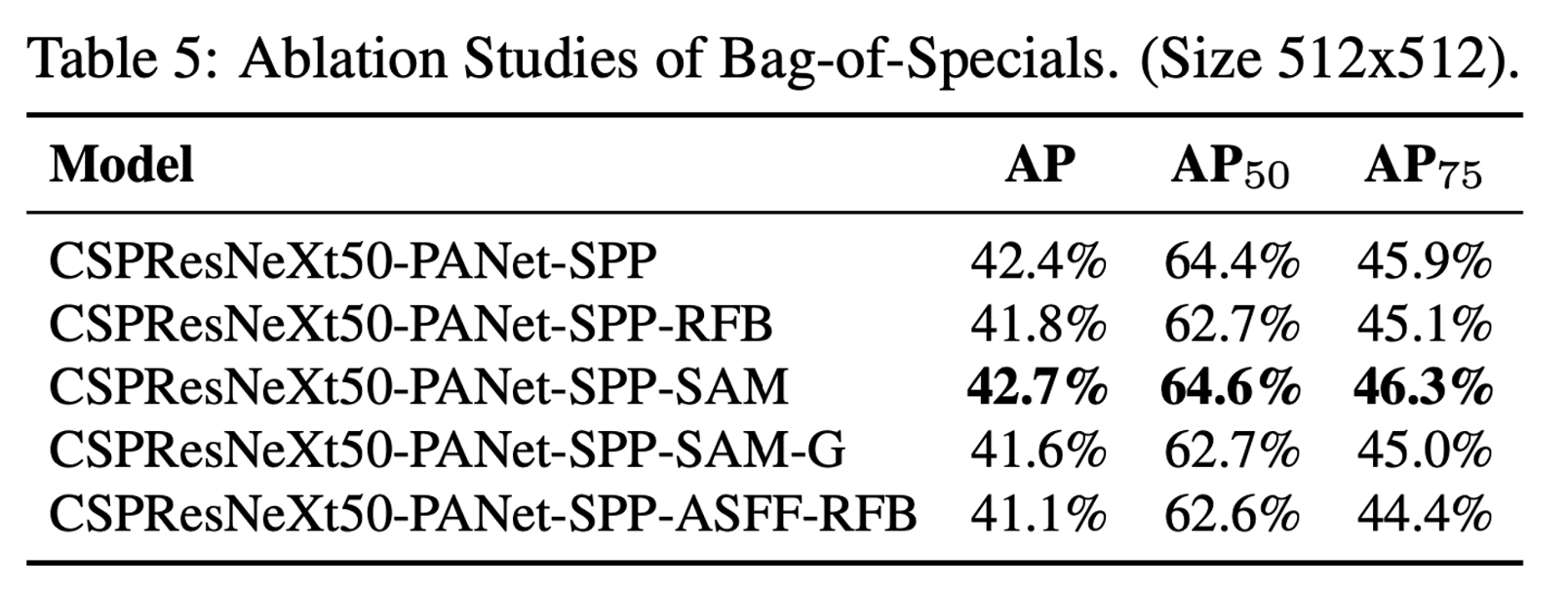
BoS-detector 또한 detector training accuracy의 향상에 있어서 많은 영향을 주었으며 추가적인 연구를 진행하여 SPP, PAN, SAM을 사용하였을 때 가장 좋은 성능을 보임
4.4. Influence of different backbones and pretrained weightings on Detector training
다른 backbone model이 detector accuracy에 미치는 영향을 보기 위하여 추가로 연구
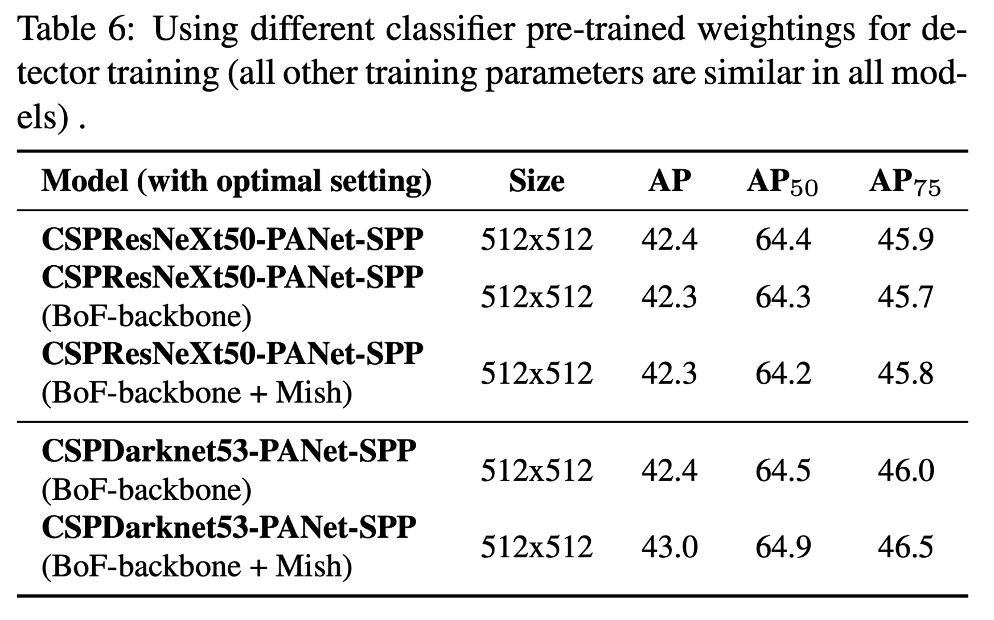
best classification accuracy를 갖는 모델이 항상 best detector accuracy를 갖는 것이 아님을 발견
결론적으로 CSPDarknet53 모델이 detector accuracy를 개선할 수 있는 능력이 더 뛰어남
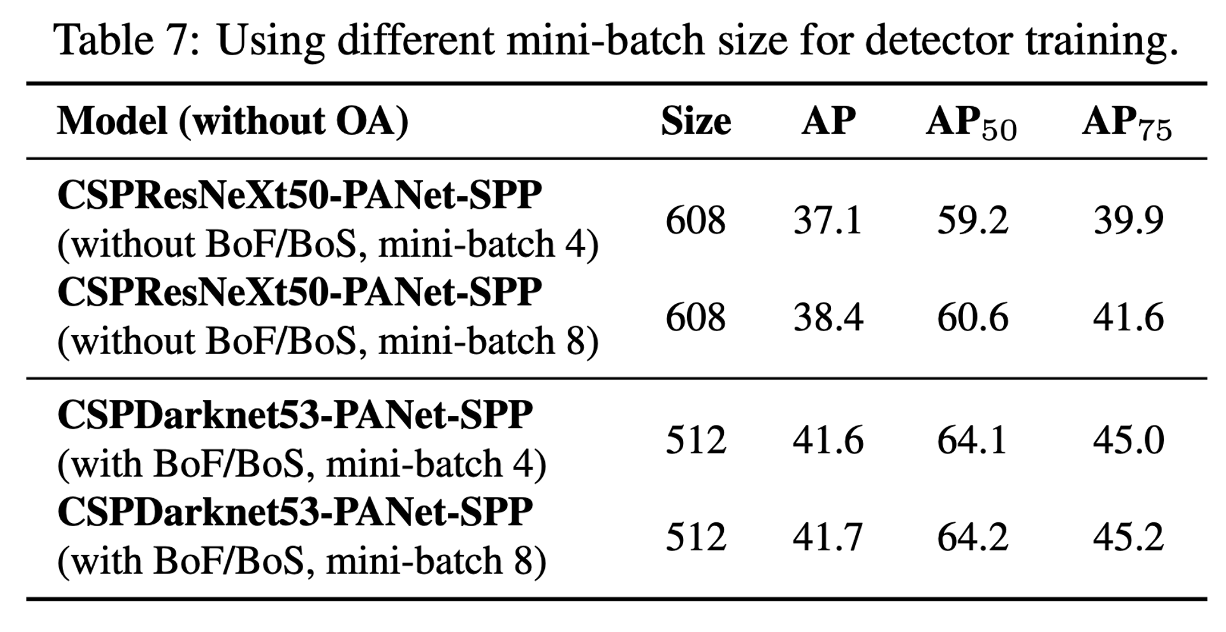
4.5. Influence of different mini-batch size on Detector training
BoF와 BoS training strategy를 추가한 후, mini-batch size는 detector performance에 영향을 거의 미치지 않음
BoF와 BoS를 도입한 후 누구나 개인 GPU를 사용하여 완벽한 detector를 학습시킬 수 있음
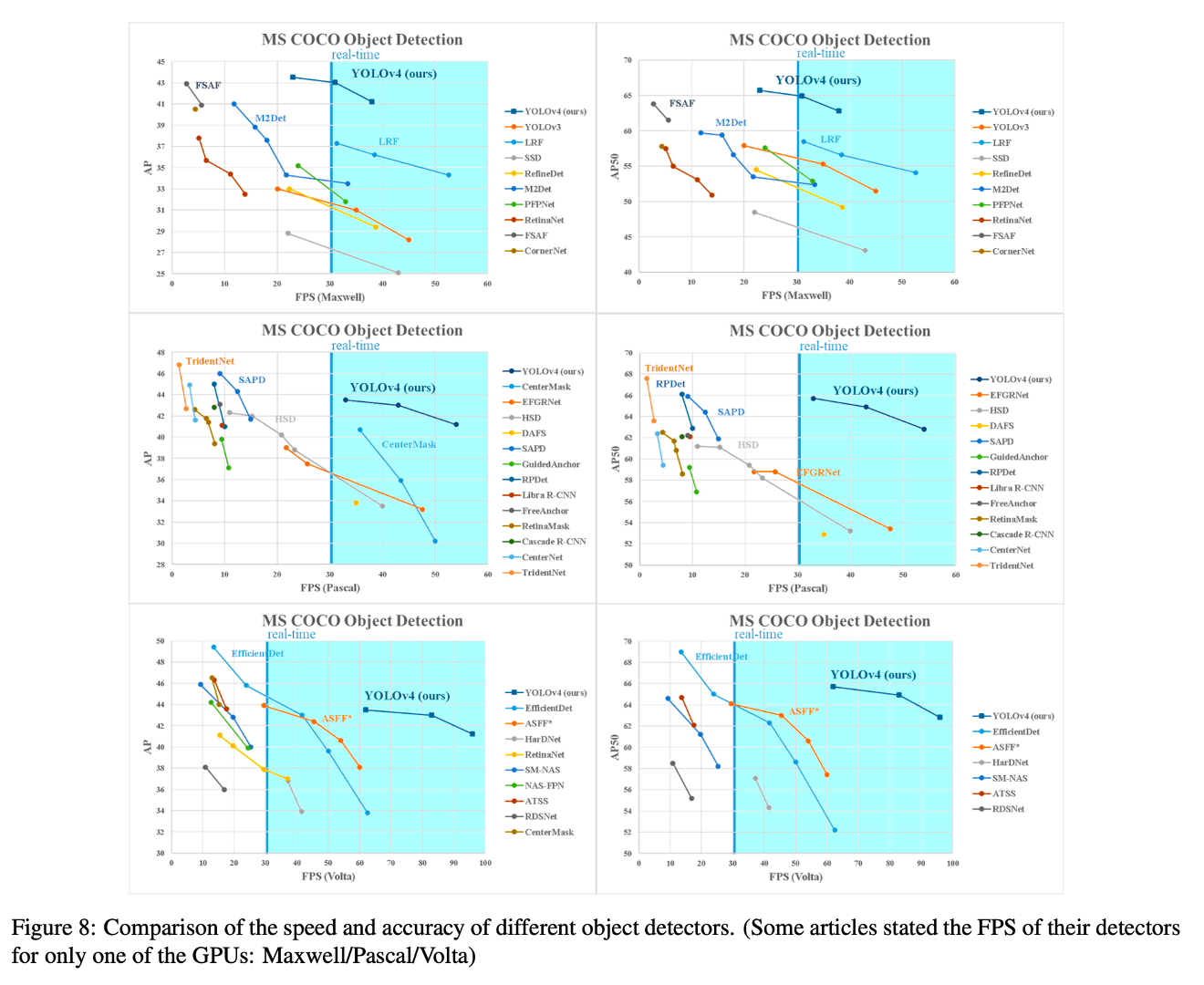
5. Results
Maxwell, Pascal, Volta 아키텍처의 GPU에서 YOLOv4를 작동하고 다른 최신 방법과 비교
YOLOv4 모델이 speed와 accuracy 모두 다른 SOTA 모델에 비하여 뛰어난 성능을 보임
나의 최종 결론 (나의 생각) :
YOLOv4논문리뷰한 나의 결론은...
그냥 많은 모델들을 섞어(이름도 다 모를 정도로 많은 모델들...) 실험을 여러번 반복한 결과 제일 성능이 잘 나오는 결과를 찾은 것 같다.
yolo는 objectdetection의 전체 역사라고 봐도 무방할 정도로 그만큼 많이 발전해왔고 많이 쓰이고 있다. yolo의 최신논문이 4까지밖에 나와있지 않아 4를 리뷰했지만, 현재 깃허브를 찾아보니 8까지도 나온 것 같다.
https://github.com/ultralytics/ultralytics
아마 논문은 더이상 안나오지만 계속해서 업데이트할 것으로 보인다.
