
Abstract
low light에서 imaging은 광자수와 SNR이 낮아서 어려움
그에 대한 해결책으로 다양한 잡음 제거, 흐림 제거 개선 기술이 제안되었지만 비디어 속도로 저조한 조도에서 이미지 처리는 어렵다.
이 논문은 저조한 조도에된의 어두운 곳에서 짧은 시간동안 노출된 이미지와 긴 노출 참조 이미지의 데이터 셋을 이용하여 fully-convolutional network의 end to end training에 기반으로 low-light image 처리를 위한 파이프라인 개발함
Dataset
-
짧게 노출된 이미지 5094개 - 길게 노출된 이미지 424개 쌍으로 존재
(길게 노출된 이미지 한 개에 짧게 노출된 이미지 여러 개일 수도 있음용 -
실내, 실외 이미지 모두 포함
실외 이미지- 달빛, 거리 조명 아래, 조도: 0.2~5 lux
실내 이미지- 조명이 꺼진 닫힌 방에서 촬영, 희미한 간접 조명, 조도: 0.03~0.3 lux -
input image- 노출은 1/30~ 1/10초로 설정
gt- 10초~30초로 설정 -
각 이미지 중 20% test set, 10%가 validation set으로 선택
카메라 - Sony α7S II 및 Fujifilm X-T2 사용
Method
Pipeline
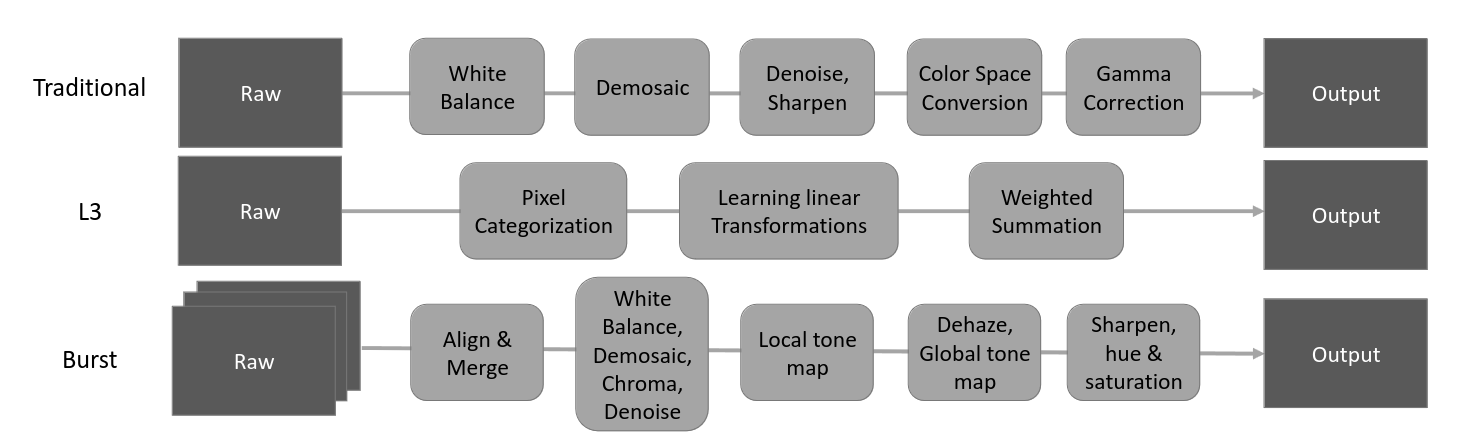
- Traditional pipeline, L3 pipeline
둘다 극저조한 SNR을 다룰수 없으므로 고속 저조한 빛 imaging에 성능 낮음 - Burst pipeline
여러 이미지를 정렬하고 혼합해서 좋은 결과가 나오지만, dense correspondence estimation이 필요하고 비디오 캡처로 쉽게 확장 못한다는 단점이 있음
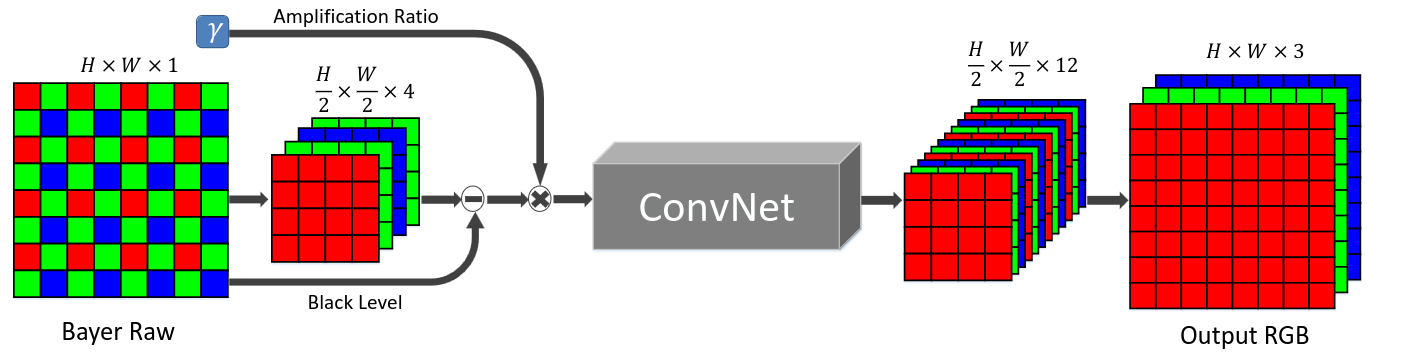
- <과정>
- Bayer array - 입력 데이터가 4개의 채널로 구성하고 각 차원에서 해상도를 반으로 줄이고
X-Trans array - 원시 데이터가 6x6 블록으로 구성-> 9개의 채널로 packing - 블랙 레벨을 빼고 원하는 증폭 비정(100또는 300배)로 스케일 조정
- 이렇게 packing되고 증폭된 데이터는 convolutional layer로 전달
- 출력은 12채널 이미지 (공간 해상도가 절반으로 줄어든)가 됨
- 절반 크기 출력을 원래 해상도로 복원하기 위해 하위 픽셀 layer를 거침
- 완성~
-
Fully-convolutional network: U-net으로 설정
-
증폭 비율- 입력으로 설정할 수 있음

Experiments



AI 개발자