Abstract
실제로 동일한 시각적 장면의 저조 및 정상 조명 사진을 동시에 촬영하는 것은 어려움, 페어링된 train 데이터가 부족한 경우도 많음
이런 이미지 쌍 없이도 훈련할 수 있는 효과적인 unsupervised generative adversial network, EnlightenGAN을 제안함
비지도 학습으로 유연성이 커짐

Method
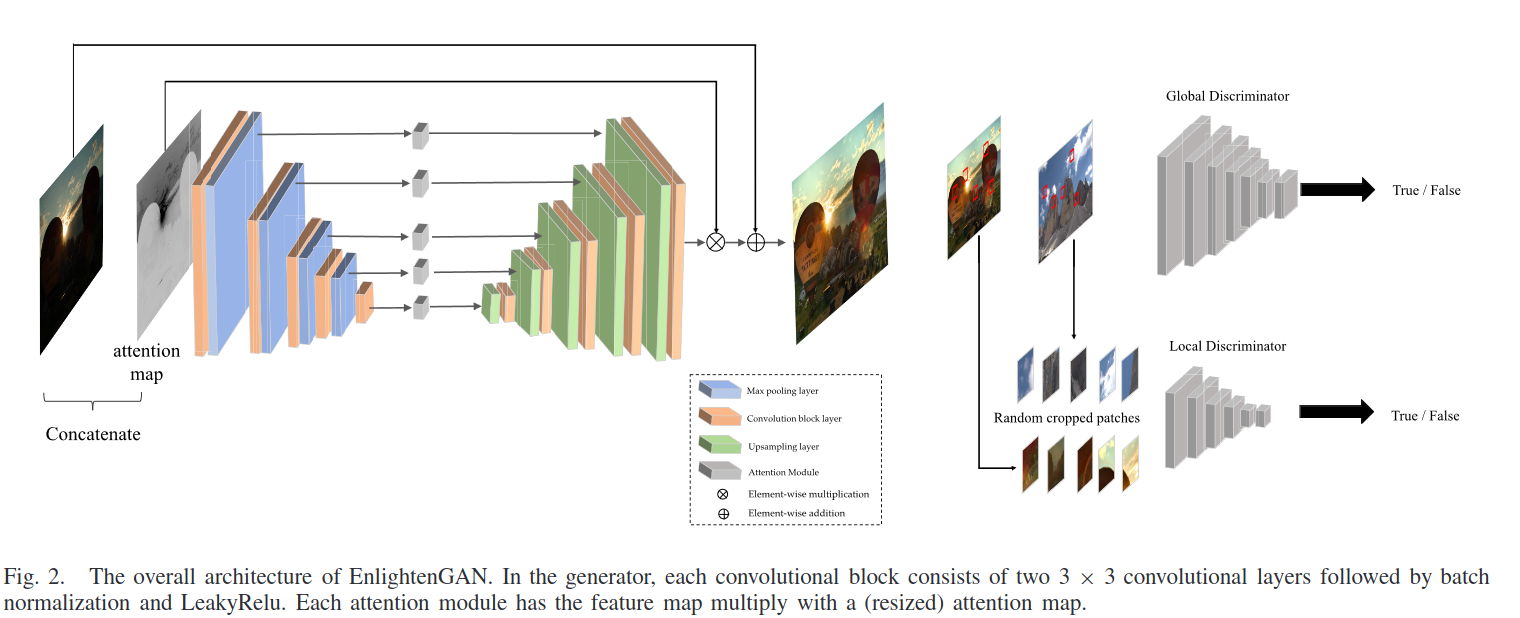
A. Global-Local Discriminators
전체적으로 어두운 배경에서 작은 밝은 영역이 있는 경우 같이 global 이미지 판별자 만으로는 원하는 결과를 못 얻음
global discriminator에 출력과 실제 normal light 이미지에서 임의로 자른 local patch를 사용하여 local discrimator를 더하는 방식으로 함 -> 그것들이 실제 이미지인지 가짜 이미지인지 구별하는 학습을 함
B. Self Feature Preserving Loss
저조 조명 입력과 향상된 정상 조명 출력 간의 VGG-feature 거리를 제약하는 Self Feature Preserving Loss를 제안함

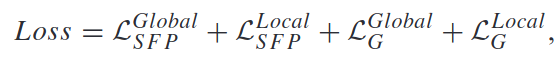
C. U-Net Generator Guided With Self-Regularized Attention
U-Net generator에 대해 easy-to-use attention mechanism을 제안함
(다양한 광 조건의 저조 조명 이미지에서는 항상 밝은 영역 보다 어두운 영역을 더 개선하기, 출력 이미지가 과도한 노출이나 과소 노출이 없도록 하기)
RGB 입력 이미지의 조명 채널 I를 추출하여 [0.1]로 정규화->1-I를 self regularized attention 맵으로 사용-> attention 맵 크기 조정-> 모든 intermediate featuremap, output 이미지와 곱함

AI 개발자