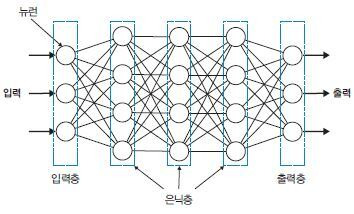
1. 양자화란 무엇인가?
부동소수점(float32)으로 학습된 모델의 가중치(W), 편향(b), 활성값(activation) 들을 더 작은 비트 수 (예: int8)로 표현하는 과정
2. 그래서 뭘 양자화 하는건가?
2-1. 가중치 (Weight)
인공 신경망에서, 노드에 입력되는 각 신호가 결과 출력에 미치는 중요도를 조절하는 매개변수(파라미터)
2-2. 편향 (Bias)
인공 신경망에서, 뉴런의 활성화 조건을 조절하는 매개변수(파라미터)
2-3. 활성화 함수(Activation Function)
인공 신경망에서, 입력받은 신호의 가중합을 다음 노드로 보낼지 말지를 결정하는 함수
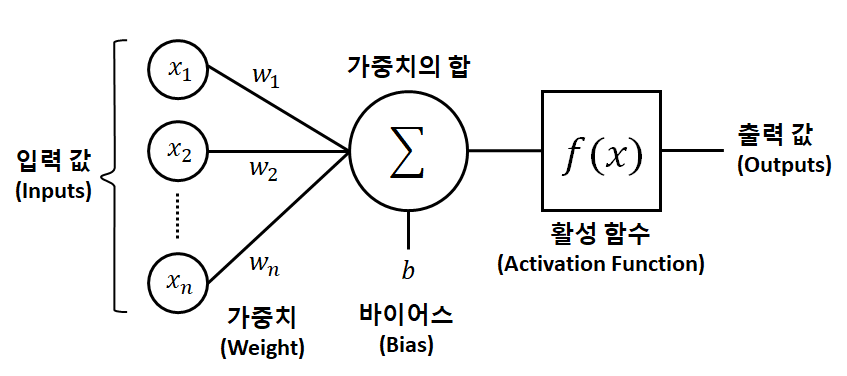
3. 양자화를 하는 이유
모델이 추론을 할 떄에 부동소수점 연산(Floating Point Operations, FLOPs) 을 하기 떄문이다.
3-1. Float32 와 int8 의 차이
그야 당연히 int8 이 연산할때 힘을 덜 쓰니까...
| 항목 | Float32 (FP32) | int8 (INT8) |
|---|---|---|
| 정밀도 | 32비트 부동소수 | 8비트 정수 |
| 연산 속도 | 느림 | 매우 빠름 (최대 4~8배 빠름) |
| 연산 유닛 크기 | 크다 | 작다 (한 사이클에 더 많은 연산 가능) |
| 하드웨어 지원 | 대부분 지원 | TensorRT, CUDA, AVX512, ARM NEON 등 최적화 필요 |
| 메모리 사용량 | 높음 | 1/4 수준 |
| 실제 예시 (NVIDIA GPU) | 1× (기준 속도) | 4~16× 가속 가능 |
3-2. 모델의 부동소수점 연산 횟수
대체적으로 부동소수점 연산 횟수는 이러하다. (근사치)
FLOPs ≈ 2 × (파라미터 수) × (토큰 수)3-3. 모델별 FLOPs 예상치
GPT-2 (345M): 약 7억 FLOPs / 토큰
LLaMA 7B (7B): 약 140억 FLOPs / 토큰
GPT-3 (175B): 약 3500억 FLOPs / 토큰
4. 양자화를 구현해보자.
-
scale 값 구하는 공식
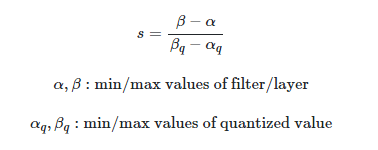
-
zero point 는 보톤 int8 의 최저값인 -127로 설정
# 1. 샘플 float 값들
float_values = [0.0, 10.5, -11.0, 12.0, 7.0, -12.0]
# 2.양자화 파라미터 설정 (데이터로부터 자동 추출)
# 2.1 최소, 최대 값 추출
float_min = min(float_values)
float_max = max(float_values)
# 2.2 int8 범위 설정
int8_min = -128
int8_max = 127
# 2.3 scale과 zero_point 계산
# 2.3.1 scale 계산
scale = (float_max - float_min) / (int8_max - int8_min)
# 2.3.2 zero_point 계산
zero_point = -int8_min
# 3. 양자화 함수
def quantize(x_list):
quantized = []
for x in x_list:
q = round((x - float_min) / scale + int8_min)
q = max(int8_min, min(int8_max, q))
quantized.append(int(q))
return quantized
# 3. 디양자화 함수
def dequantize(q_list):
dequantized = []
for q in q_list:
x = (q - int8_min) * scale + float_min
dequantized.append(float(x))
return dequantized
# 4. 실행
int8_values = quantize(float_values)
restored_floats = dequantize(int8_values)
# 5. 출력
print("scale:", scale)
print("zero_point:", zero_point)
print("int8_min:", int8_min)
print("int8_max:", int8_max)
print("원본 float32:", float_values)
print("양자화된 int8:", int8_values)
print("복원된 float32:", restored_floats)5. 결과


인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.