왜 양자화를 하는지 알아봤으니 모델을 직접 만져보자.
이번에는 허깅페이스에서 모델을 개별 다운로드 받아 gguf 파일로 변환하고 llama-cpp-python 으로 돌려보는 것을 해보겠다.
1. llama.cpp git clone
% git clone https://github.com/ggerganov/llama.cppclone 완료
2. cmake
아래와 같이 실행하면 metal을 사용하게 된다.
% cmake -DLLAMA_METAL=on
% cmake --build . --config Release대충 이런 메시지가 보이면 성공~

3. 허깅페이스에서 모델 선정
exaone3.5:2.4b 너로 정했다. 일단 모든 파일을 다 받았다.
models/EXAONE-3.5-2.4B-Instruct 디렉토리에 받는다.
import os
from huggingface_hub import snapshot_download
huggingface_token = os.getenv("HUGGINGFACE_API_KEY")
snapshot_download(
repo_id="LGAI-EXAONE/EXAONE-3.5-2.4B-Instruct",
local_dir="./models/EXAONE-3.5-2.4B-Instruct",
use_auth_token=huggingface_token
)4. 원본을 gguf 로 변환
4-1. 필요 패키지 설치
% uv pip install -U transformers sentencepiece huggingface_hub torch4-2. convert_hf_to_gguf.py 실행
llama.cpp 는 허깅페이스에서 받은 모델을 바로 사용할 수 없다. gguf로 변환해 보자. --outtype 이 없는 경우 양자화를 하지 않는다.
% python ./convert_hf_to_gguf.py ./models/EXAONE-3.5-2.4B-Instruct --outfile ./models/EXAONE-3.5-2.4B-Instruct/EXAONE-3.5-2.4B-Instruct_Q8_0.gguf --outtype q8_04-3. --outtype 옵션
| 옵션 값 | 데이터 형식 | 설명 |
|---|---|---|
| f32 | 32비트 부동소수점 (Float32) | 가장 높은 정밀도를 가지지만, 파일 크기가 가장 큼 |
| f16 | 16비트 부동소수점 (Float16) | f32보다 정밀도가 낮지만 파일 크기를 절반으로 줄일 수 있음. 일반적으로 많이 사용됨 |
| bf16 | bfloat16 | f16과 유사한 16비트 형식. 더 넓은 지수 표현 범위. 특정 하드웨어(GPU 등)에서 효율적 |
| q8_0 | 8비트 양자화 | 품질 손실은 약간 있으나 파일 크기와 추론 속도 측면에서 균형 잡힌 선택 |
| tq1_0 | TQ1_0 양자화 | 실험적 또는 특정 목적용 양자화 형식 |
| tq2_0 | TQ2_0 양자화 | TQ1_0보다 약간 더 정밀하거나 다른 특성을 가진 실험적 양자화 형식 |
| auto | 자동 선택 | 모델의 첫 텐서 타입에 따라 f16 또는 bf16 중 가장 적합한 형식을 자동 선택 |
4-4. gguf 변환된 파일

5. llama-run 으로 변환된 gguf 파일 테스트
exaone3.5:2.4b 모델은 --outtype 옵션 없이 gguf 변환하면 llama-run 으로 모델을 로드할 수 없었다.
% ./bin/llama-run ./models/EXAONE-3.5-2.4B-Instruct/EXAONE-3.5-2.4B-Instruct_Q8_0.gguf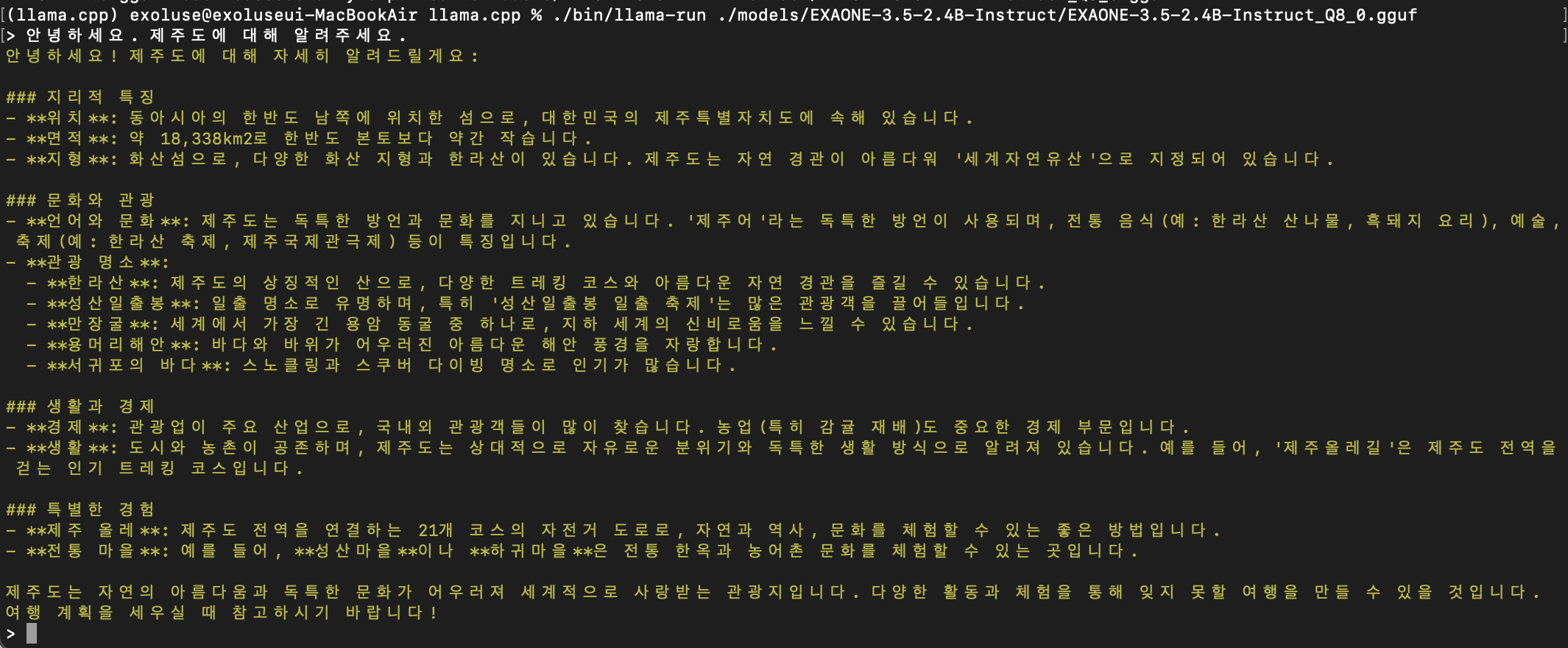
6. llama-cpp-python 으로도 추론이 가능하다.
6-1. llama-cpp-python 설치
# metal 을 사용하기 위함
% CMAKE_ARGS="-DLLAMA_METAL=on"
% FORCE_CMAKE=1
% uv pip install llama-cpp-python --no-binary llama-cpp-python
# metal 없이 간다면
% uv pip install llama-cpp-python6-2. gguf 모델 추론
from llama_cpp import Llama
# 모델 경로
MODEL_PATH = "./models/EXAONE-3.5-2.4B-Instruct/EXAONE-3.5-2.4B-Instruct_Q8_0.gguf" # 경로에 맞게 수정
# 모델 로딩
llm = Llama(
model_path=MODEL_PATH,
n_ctx=512, # 문맥 길이
n_threads=4 # CPU 스레드 수 (시스템에 맞게 조절)
)
# 메타데이터
print(llm.metadata)
# 프롬프트 설정
prompt = (
"[|system|]\n"
"[|user|]안녕하세요. 제주도에 대해 알려주세요."
"[|assistant|]"
)
# 추론 실행
output = llm(prompt, max_tokens=1024, stop=["[|assistant|]"])
# 결과 출력
print(output["choices"][0]["text"])
6-3. 모델의 metadata 중 chat_template
- system 메시지가 생략되어 있으면 [|system|][|endofturn|]를 강제로 삽입
- 각 메시지는 [|role|]내용 형식
- user는 줄바꿈, assistant는 [|endofturn|]으로 끝남
- 최종 프롬프트 끝에 [|assistant|]를 붙여 모델이 응답하도록 유도
{% for message in messages %}
{% if loop.first and message['role'] != 'system' %}
{
{'[|system|][|endofturn|]\n' }}
{% endif %}
{{ '[|' + message['role'] + '|]' + message['content'] }}
{% if message['role'] == 'user' %}
{{ '\n' }}
{% else %}
{{ '[|endofturn|]\n' }}
{% endif %}
{% endfor %}
{% if add_generation_prompt %}
{{ '[|assistant|]' }}
{% endif %}
인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.