Automtic Inside Point Localization with Deep Reinforcement Learning for Interactive Object Segmentation - 논문 리뷰
강화학습 논문 리뷰

논문 출처: https://www.mdpi.com/1424-8220/21/18/6100
Reference
-
Li G, Zhang G, Qin C. Automatic Inside Point Localization with Deep Reinforcement Learning for Interactive Object Segmentation. Sensors (Basel). 2021 Sep 11;21(18):6100. doi: 10.3390/s21186100. PMID: 34577306; PMCID: PMC8472885.
-
Zhang, Shiyin et al. “Interactive Object Segmentation With Inside-Outside Guidance.” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2020): 12231-12241.
-
Y. Huang, G. Wei and Y. Wang, "V-D D3QN: the Variant of Double Deep Q-Learning Network with Dueling Architecture," 2018 37th Chinese Control Conference (CCC), 2018, pp. 9130-9135, doi: 10.23919/ChiCC.2018.8483478.
Interactive Segmentation
CNN 기반의 딥러닝을 이용한 컴퓨터 비전의 최근 비약적으로 발전함에 따라 Segmentation 또한 전성기를 맞이 하였다. 하지만 인공지능이 발전함에 따라 양질의 데이터가 많이 필요한데 이것은 많은 비용을 발생 시킨다. 특히 Segmentation은 Pixel 별로 인간이 Annotation을 작성해야 하기 때문에 다른 비전 분야보다 데이터를 생성하기 까다롭다.
그래서 최근 Interactive Segmentation을 이용해 사람이 조금의 힌트만 주면 딥러닝 모델이 알아서 Segmentation mask를 만들어주는 기술이 개발되고 있고 Insidoe Outside Guidance가 그 중에 하나다..
IOG(Inside-Outside-Guidance)

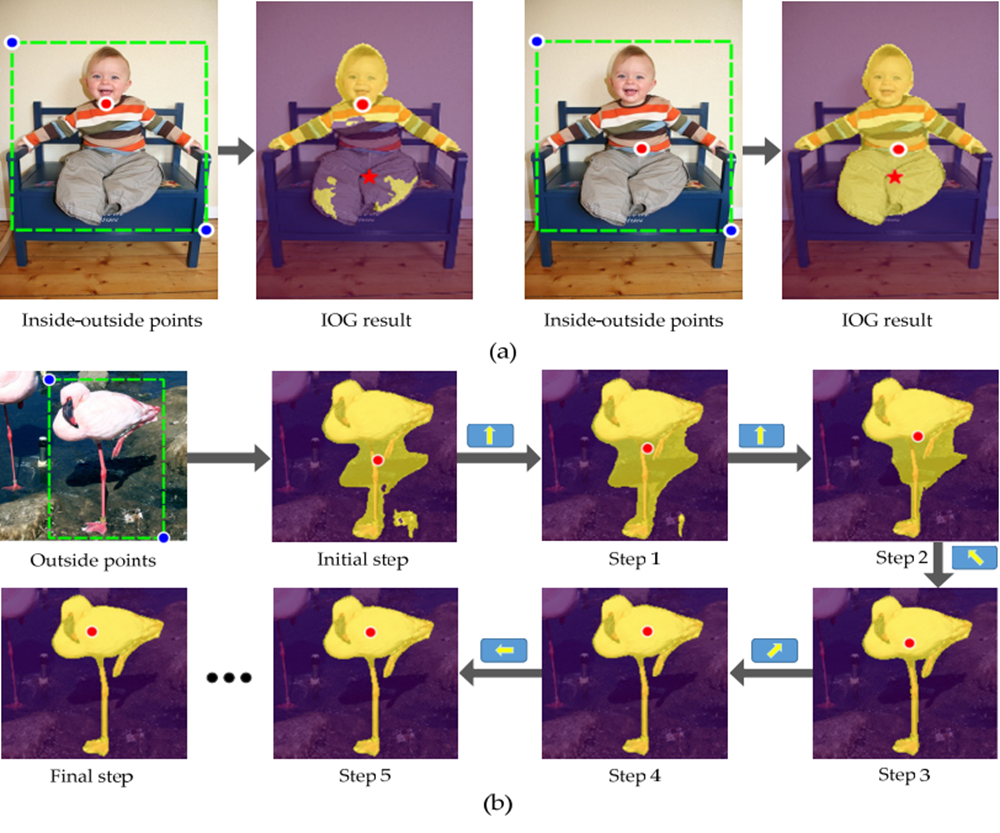
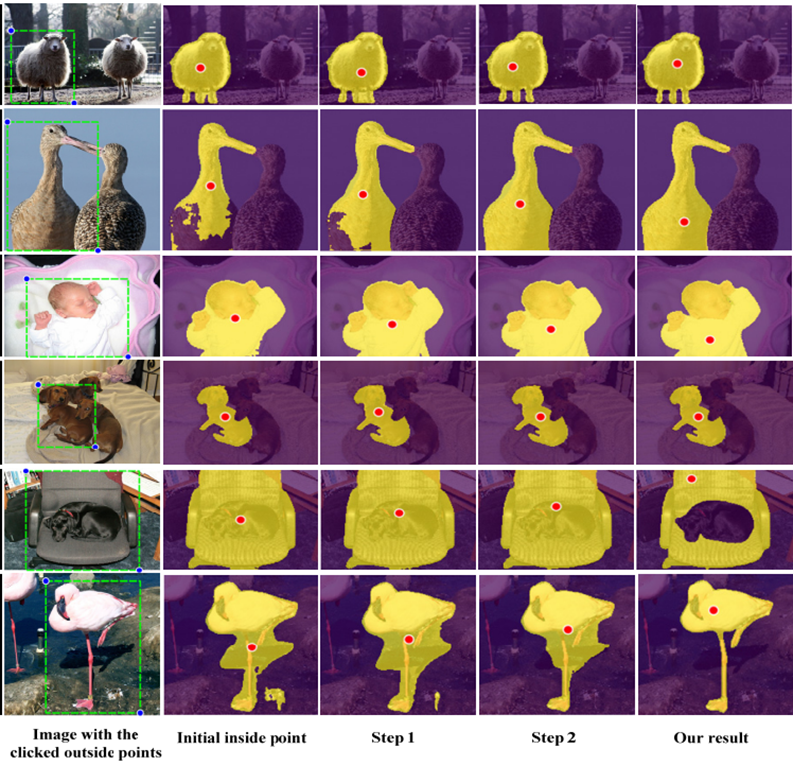
IOG에서는 인간이 Object에 대한 BBOX와 Segmentation 하고 싶은 Object 내부에 Inside Point를 지정하면 IOG Network가 자동으로 Segmentation Mask를 만들어준다. 이 모델은 사용자에게 엄청난 시간 절약과 함께 뛰어난 성능을 보여줘 2020년 CVPR에 기재 되었다.
오늘 소개할 이 연구에서는 점을 어디에 찍을 것인를 강화학습의 Agent가 학습하게 함으로써 딥러닝 모델이 자동으로 학습 데이터를 생산할 수 있는 방법을 소개한다.
Idea
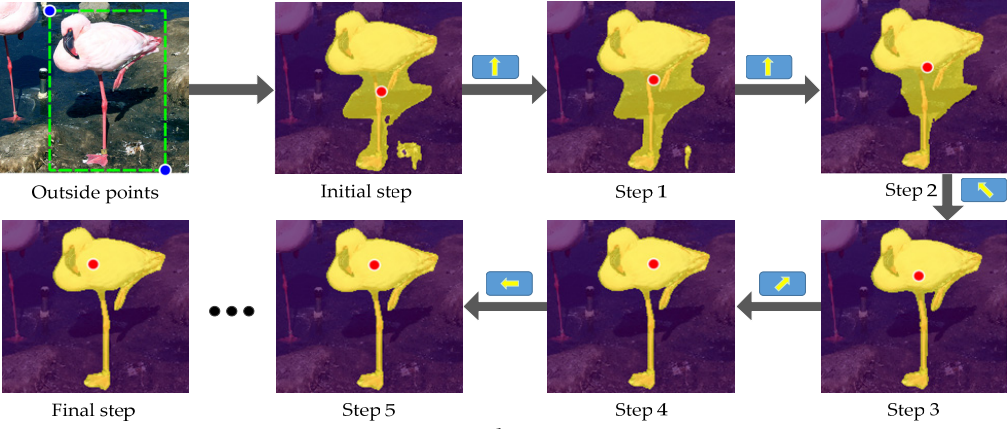
Inside Point를 결정하는 문제는 Sequential한 상황에 대한 Decision Making이라고 볼 수 있다. 지금 점의 위치로 생성된 Segmentation mask라는 단서를 기반으로 Agent는 그 순간 Expected Reward가 가장 높은 방향으로 Point를 이동 시켜 Segmentation Mask가 최대한 Object를 모두 담을 수 있도록 학습한다.
그러므로 이 문제는 강화학습의 MDP 문제로 Formulation 할 수 있다.
IPL-Net(Inside Point Location Network)
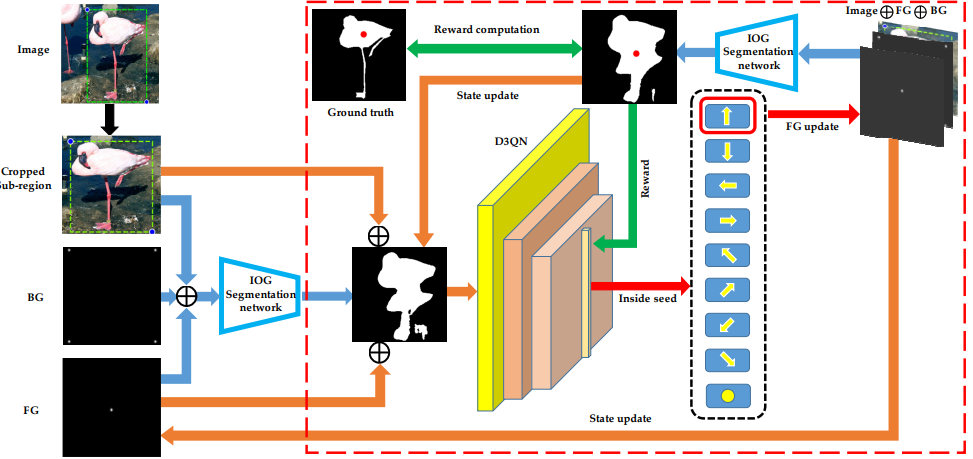
State
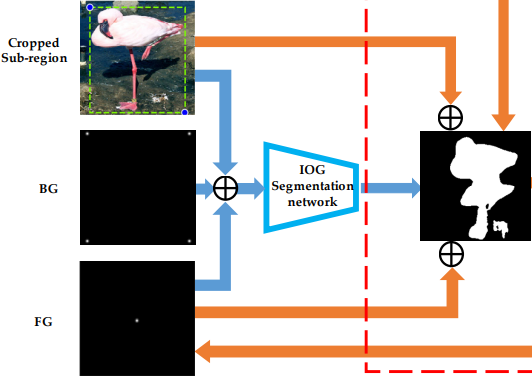
State는 BBOX가 쳐진 부분만 Cropped Sub-region 그리고 BBOX의 좌표, 찍혀진 Inside Point를 Concation한 다음 IOG Network를 통과한 Segmentation mask+ Cropped Sub-region + Inside Point를 Concation한 것을 사용한다.
Action
Action은 Inside Point의 이동이다.
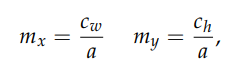
이동 크기는 Cropped Image의 크기에 상수 a를 나눈 것인데 이 연구에서는 a=15로 고정하였다.
Reward
Reward 함수는 두 가지가 있다. 하나는 non-termination일 때 그리고 termination일 때이다.
-
Non Terminate
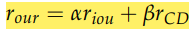
Terminated 하지 않은 상태일 때 보상은 iou와 Inside Point와 이미지 중앙의 거리의 가중치 합이다. IOU를 보상으로 주는 것은 직관적으로 받아들일 수 있지만 후자는 필요 없어 보인다고 생각할 수도 있다. 하지만 실험을 진행하며 대부분 Suitable Inside Point 지점은 이미지 중앙이 아니었기 때문에 Centered Point와의 Distance를 보상으로 줘 중앙으로 가지 않게 Agent를 유도한다. 하지만 Centered Point에 너무 집중하면 정작 중요한 IOU에 집중할 수 없기 때문에 가중치를 줬는데 이 연구는 으로 설정하였다. -
Terminate
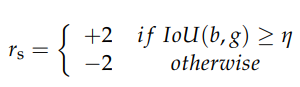
Exploration
이 연구에서는 Exploration 전략으로 방식을 사용하였다.

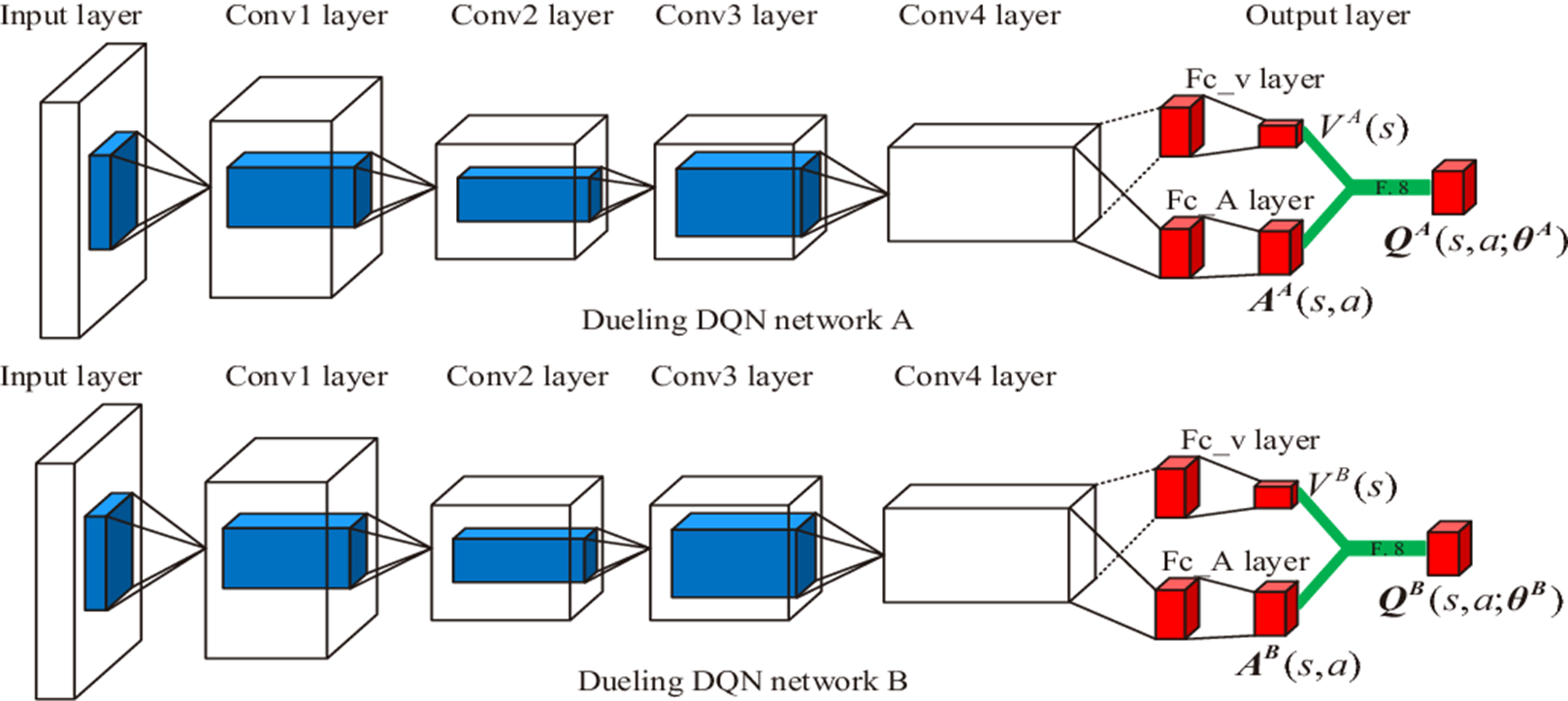
D3QN
D3QN은 Dueling DQN와Double DQN이 합쳐진 방식이다.
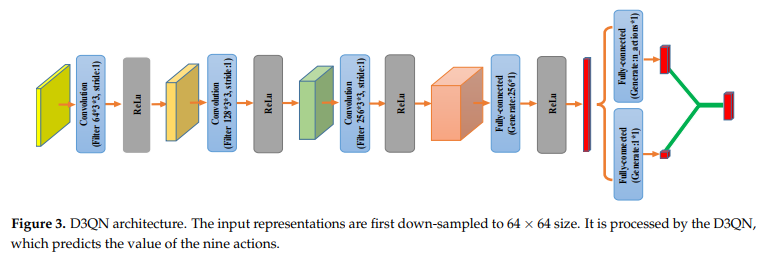
위 그림은 이 연구에서 사용된 D3QN 아키텍처이다.
Dueling DQN
Dueling DQN은 A2C 알고리즘 아이디어에서 차용해 구글 딥마인드에서 만든 알고리즘이다.
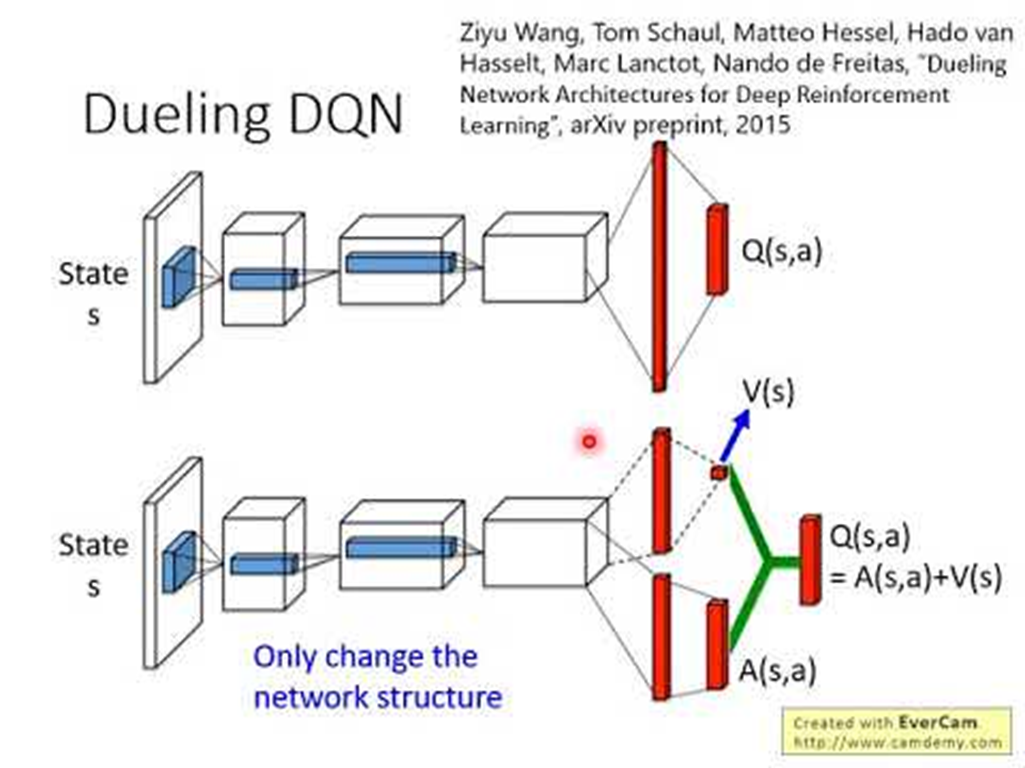
Actor Critic은 데이터의 분산을 줄이기 위해 식을 변형해 라는 식을 유도해 냈다. 이것을 Q에 대해서 정리하면 라는 식이 만들어진다.
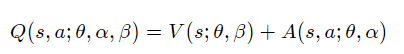
기존 DQN은 단일 Stream으로 Q값을 output으로 내놓았지만 Deuling DQN은 마지막에 V와 A를 출력하는 다른 신경망을 구성하고 나중에 V와 A를 Concation하여 Q를 구성한다.
여기에는 두 가지 Issue가 남아있다.
- V와A가 과연 정확하게 추정된 값이라고 확신할 수 있는가?
- 우리는 계산된 Q를 보고 이 값이 어느 V와 A에서 유도되었는지 알 수가 없다. 이는 성능하락을 야기하며, unidentifiable이라고 표현한다.
이 문제를 해결하기 위해 기준점을 정해야 한다. 아래와 같이 식을 변경하면 optimal action 을 택했을 때 Q=V이 되도록 할 수 있다.
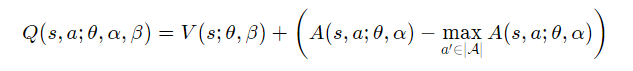
이기 때문에 가 되는데 이는 Bellman Optimal Equation을 만족한다.
이 식이 무슨 의미를 가지는지 Deepmind에서 Atari를 이용해 실험한 결과
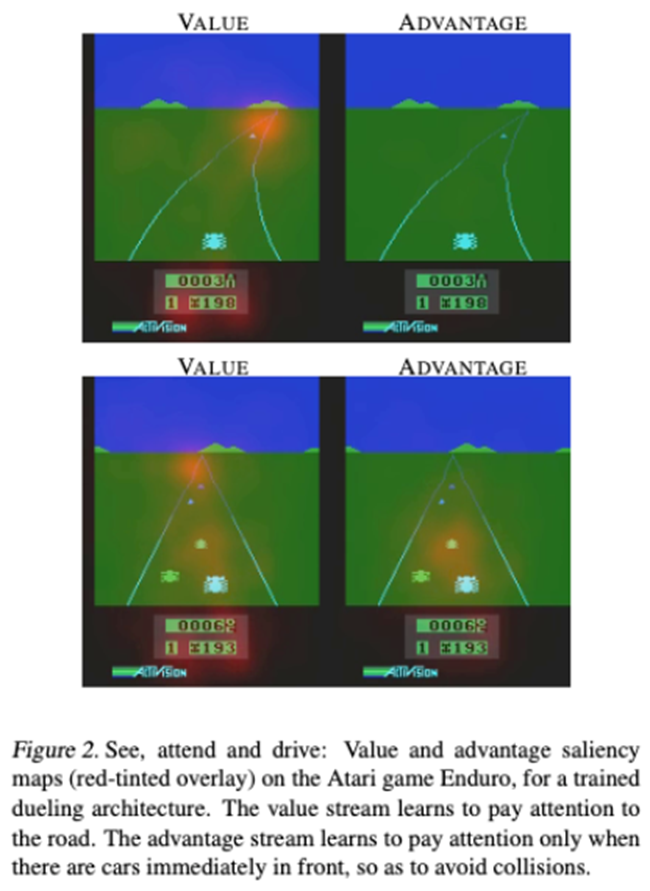
V는 먼 미래를 고려하기 위해 지평선에 반응하는 반면 A는 지금 바로 앞에 장애물에 반응하는 것을 확인할 수 있다.
굳이 왜 나눴냐고 할 수 있겠지만 기존 Vanilla DQN보다 성능이 좋다고 하니 그냥 믿고 쓰자.
Double DQN
Double DQN은 Target이 급격하게 흔들리는 것을 막기 위해 사용하는 기법으로 2개의 신경망을 구성하고 Target 값을 Target Netwrok가 계산함으로써 학습의 안정성을 보장한다.

먼저 이런 방식으로 Original Network를 학습한 후 일정 step을 지나 그 순간의 Original Netwrk의 parameter 를 전부 복사해 Target에 붙여넣는 Hard Updating과 Origianl Network의 parameter를 낮은 가중치를 적용해 점진적으로 Target Network를 Updating 하는 Soft Updating으로 나뉜다.
Prioritized Replay Buffer
DQN 계열의 알고리즘은 Agent가 바로 생산한 데이터를 학습 데이터로 사용하지 않고 우선 Replay Buffer에 보관한 후 Ramdomly 로 뽑아 학습한다. 하지만 이것은 매우 낮은 Sample-Efficient를 야기시키는데 특히 대부분의 데이터가 학습에 도움을 주지 못하는 초기의 경우 자칫하면 학습이 아예 안 이루어질 수 있다. 그러므로
학습 데이터에 우선순위를 설정한 후 우선순위가 높은 데이터 부터 학습에 이용하는데 이런 방식은 *Prioritized Replay Buffer8라고 하며 이 연구에서도 이런 Replay Buffer를 사용하였다.

Experiment

이 연구에서는 PASCAL를 훈련 데이터로 사용하였고 GrabCut와 COCO 데이터를 테스트 데이터로 사용하였다.
- PASCAL and GrabCut

이 표는 일정 IOU 이상을 만족하는 Segmentatoin mask 를 만들기 위해 Agent가 몇 번 Inside Point를 이동시켰는지 보여주는 표이다. 잘 보면 기존 RL 이 없는 IOG보다 높은 성능을 보여주고 있음을 알 수 있다. 이를 통해 RL를 사용하는 것이 더 효율적임을 보여준다.
- COCO
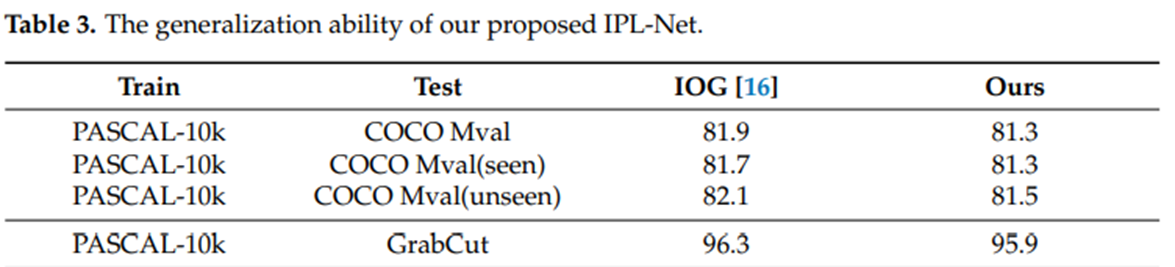
하지만 COCO에서는 IOG에 비해 높은 성능을 보여주지 못한 한계가 있다.
Conclusion
이 연구는 Segmentation Annotation 작업을 강화학습을 통해 컴퓨터가 스스로 데이터를 생성할 수 있는 방법을 소개하였다.
