논문 출처: https://ieeexplore.ieee.org/document/8954189
Introduction
이번에는 강화학습 알고리즘 중에 하나인 Actor-Critic의 DDPG 알고리즘을 이용해 Segmentation의 끝판왕인 Instance Segmentation 을 수행한 연구를 소개하겠다.
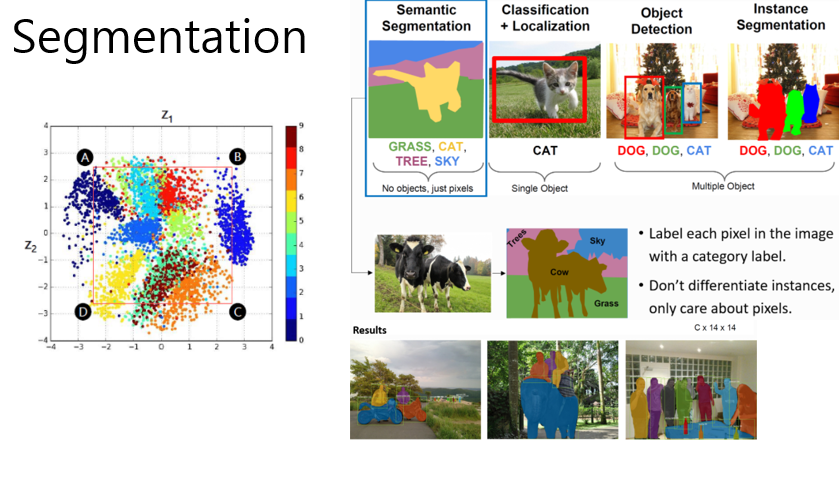
Segmentation은 크게 Semantic Segmentation과 Instance Segmentation으로 나뉜다.
Semantic Segmentation
- Defintion: Objects shown in an image are grouped based on defined categories. For instance, a street scene would be segmented by 'Pedestrians','bikes','Vehicles','sidewalks',and so on.

Instance Segmentation
- Definition: Consider instance segmentation a refined version of semantic segmentation. Categories like “vehicles” are split into “cars,” “motorcycles,” “buses,” and so on — instance segmentation detects the instances of each category.

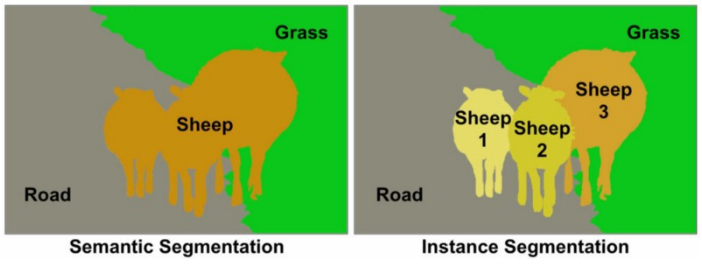
Semantic vs Instance
이 연구에서는 우선 너무나 방대한 Action Space를 줄이는 방법을 고민하는 것에서 시작한다. Binary Segmentation을 한다고 가정했을 때, Pixel 마다 가능한 행동은 2개다. 만약 높이가 H 너비가 W라고 가정한다면 Action Space의 Dimension은
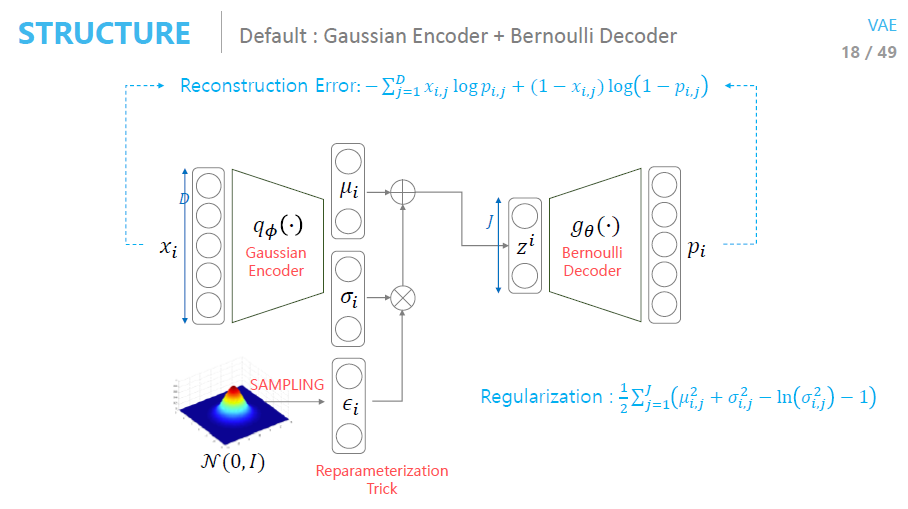
가 된다. 보통 강화학습을 이용한 연구에서 Action의 최대 20개 정도인 걸 고려할 때 는 너무나 큰 수치이며 학습이 거의 되지 않을 확률이 매우 높다. 그래서 이 연구에서는 Input-Image를 VAE 를 통해 Action Space를 Latent Space로 축소 시켰다. 그것에 대해서 이제 차근차근 알아가보자.
Action Dimensionality


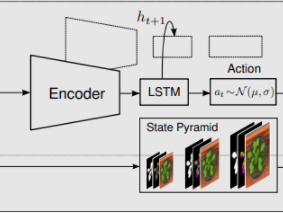
Model
Architectrure
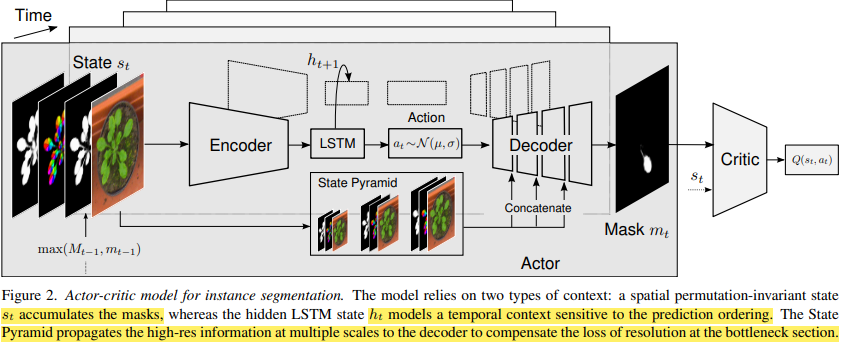
State


Action

State Transition

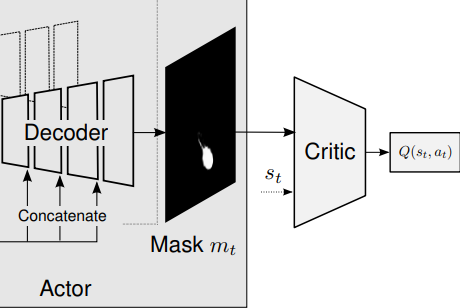
Latent Space에서 Action을 취해 Latent Vectors를 구성한 후 Decoder를 거쳐 Mask가 하나 만들어진다. 이후 이전 State와 Intergrating 하는 식으로 상태가 전이 된다.
이 아키텍처에서 또 눈여겨 볼 점은 State Pyramid를 Decoder에 Concatenate 했는데

Encoder를 거치며 잃어버린 high-resolution 정보들을 보충해주기 위함이라고 설명한다.
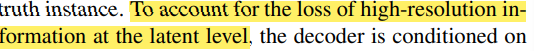
Reward
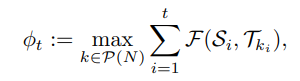
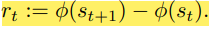
Reward를 주는 방식으로 IOU를 사용하였다. Instance Segmentation이기 때문에 Ground Truth mask가 여러개일 것이다. 그러므로 행렬로 각각 비교하여 가장 높은 값을 주는 k mask에 대한 Prediction masks들과의 IOU의 합을 Reward로 부여한다.
ETC

Actor-Critic
DDPG (Deep Deterministic Policy Gradient)
DDPG 는 DQN과 Actor-Critic의 알고리즘이 섞여서 태어난 알고리즘으로 Continuous한 Action Space에 이용되기 위해 만들어졌다.
DDPG의 재밌는 점은 Actor-Network가 Output으로 내놓는 행동은 딱 1개다. (이런 Policy를 Deterministic Policy라고 부른다.) DQN은 여러 Output을 출력하고 그 중에 가장 값이 큰 값에 해당하는 Action을 취하는 반면 DDPG는 애초에 출력이 하나 밖에 없다. 강화학습을 공부해본 사람이라면 Exploration이 얼마나 중요한지 알 것이다. DDPG는 Noise를 첨가함으로써 이 문제를 해결하였다.
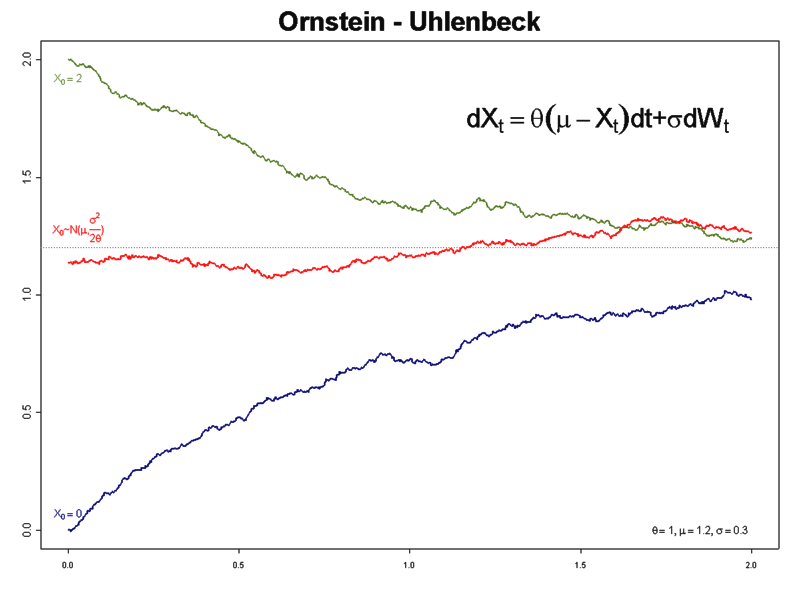
보통 Noisy로 Ornstein-Uhlenbeck을 사용한다. 하지만 이 연구에서는 전혀 다른 Noisy를 정의하였다.
심층 강화학습의 또다른 문제점은 학습은 안정성이다. 심층 강화학습은 큰 맥락은 Target 값과의 Error를 0으로 만드는 것을 목적으로 Gradient-Descent방식을 취하는데 Target 값을 직접 정의할 수는 없으므로(Target 값을 찾아야 하는데 정의하는 건 모순이기 때문이다.) Bellman 방정식을 이용해 Target값을 기존 신경망으로 근사 정의한다.
하지만 이렇게 정의하면 Network가 Updating 될 때마다 Target 역시 심하게 흔들리기 때문에 학습이 안정적이지 못한다. 그래서 DDPG는 Target Network라고 기존 신경망을 복사해서 기존 신경망이 학습되면 그 학습된 Parameter를 조금씩 반영해 점진적으로 Parameter를 Updating한다. 이것을 Soft Updating이라고 부른다.
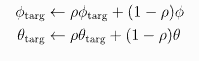
아래는 Pseudocode이다.

Critic
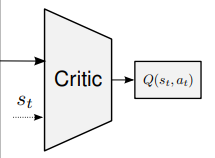
Critic 신경망은 이상 가치함수를 근사하는 신경망이다. 만약 Critic의 학습 Gradient가 0에 가까워 진다면 최적 가치함수를 찾은 것이고 그 상태의 Actor Network는 최적 정책이 되며 MDP 문제는 해결 된다.
(강화학습의 목표는 최적 가치 함수를 만드는 최적 정책을 찾는 것인데 이때 우리는 MDP가 풀렸다고 말한다.)
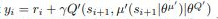
Target를 벨만방정식으로 근사하는데 이것을 Temporal Difference (시간차) 방식이라고 부르고 보통 이 방법을 많이 사용한다. 하지만 이 연구에서는 Monte-Carlo 방식을 이용하였다.
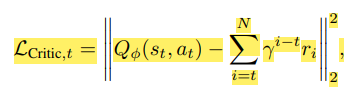
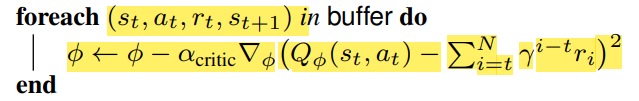
Actor
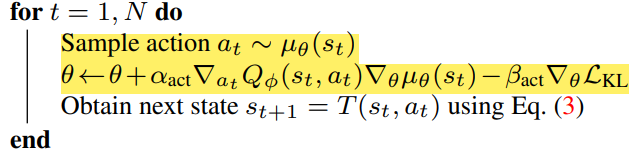
Critic 신경망이 우선 학습되고 Actor는 Gradient-Ascent 방식으로 Parameter들을 updating한다.
Exploration

Exploration은 Expected Reward가 높아지도록 짜여져야 한다. 이 연구에서는

KL-Divergence를 Noisy로 정의하였다. (본인도 왜 이렇게 했는지 모름 )
추측해보자면 아마 VAE의 Loss에서 그 아이디어를 가져온 것 같다.

Experiment
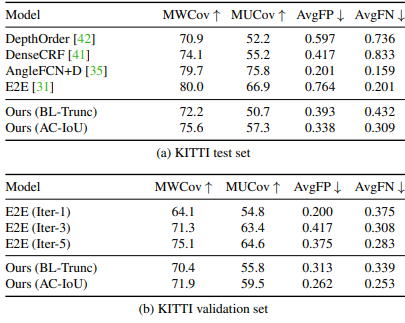
실험 결과 아쉽게도 다른 Instance Segmentation (강화학습을 이용하지 않은) 더 낫다고 할 수 없는 결과가 나왔다 다만 Ours(BL-Trunc)과의 비교를 눈여겨 봐야 하는데 Ours(AC-IOU)는 우리가 지금까지 살펴본 RL 기반이고 Ours(BL-Trunc)는 위 아키텍쳐에서 RL 기능을 뺀 순수한 VAE로 구성한 Segmentation 신경망이다. 결과를 볼 때 RL를 사용하는 게 사용하지 않은 것보다 같은 모델일 때 Segmentation 성능이 더 좋다는 것을 보여준다. 이 논문이 그리 뛰어난 성과가 없음에도 CVPR에 등재된 이유는 아마 같은 모델일 때 RL 을 사용하는 게 더 좋은 성과를 냈다는 걸 보여줬기 때문이라 생각한다.
Conclusion

이 연구는
- VAE 를 통해 Action Space의 차원을 매우 낮췄고 low-dimensional representation을 이용해 Agent를 학습 시켰다.
- DDGP의 Exploration Noisy를 기존 Noisy가 아닌 normally- distributed latent space와의 KL-Divergence Loss로 정의하였다.
정도의 성과를 달성하였고 결과적으로 RL을 사용하지 않았을 때보다 동일 모델 대비 높은 Segmentation 성능을 보인다는 사실을 실험적으로 입증하였다.
오늘은 Actor-Critic을 이용한 Segmentation을 알아보았다. 작가가 Segmentation에 대해서 잘 몰라 자세히 풀어 나가지 못한 게 아쉽다. 하나만 파는 게 아니라 여러 분야를 골고루 파면서 공부해야 겠다는 교훈을 얻고 이 글을 마무리 하겠다.
Reference
- N. Araslanov, C. A. Rothkopf and S. Roth, "Actor-Critic Instance Segmentation," 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 8229-8238, doi: 10.1109/CVPR.2019.00843.
