Active Object Detection Using Double DQN and Prioritized Experience Replay - 논문 리뷰
강화학습 논문 리뷰
논문 출처: https://ieeexplore.ieee.org/document/8489296
Abstract
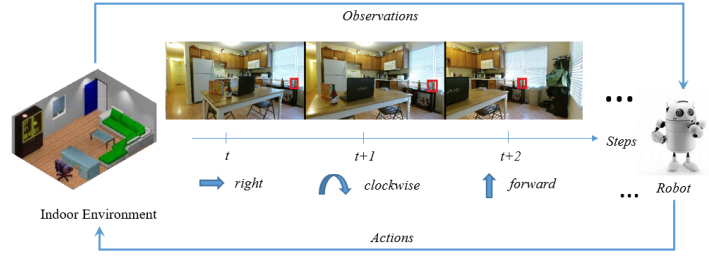
이 논문은 Deep Reinforcement Learning을 이용해 효율적인 Active Object Detection을 할 수 있는 알고리즘을 제시한다.
What is Active Object Detection
- When an object of interest apeears in its view field, and it couldn't detect it surely, it can adjust its pose by translation or rotation to get a better observation
즉 현재 캡쳐한 사진에서 Interest Object의 Classifier Performance를 높이기 위해 로봇이 적절한 Decision Making 을 하는 것이 Active Object Detection의 핵심이다.
이미지를 기반으로 CNN을 통해 Decision Making을 하는 유명한 알고리즘 중에 하나가 DQN 알고리즘인데 이 논문에서는 DQN의 target-stability를 보완환 Double DQN과 데이터의 중요도를 기반으로 우선순위를 정한 PRIORITIZED EXPERIENCE REPLAY 기법을 사용하였다. Prioritized experience replay 논문에 대한 리뷰는 매우 흥미롭고 중요하므로 다음에 따로 리뷰할 게획이다.
Dataset
이 논문에서는 Active Vision DATASET을 이용하여 실험을 진행하였다.
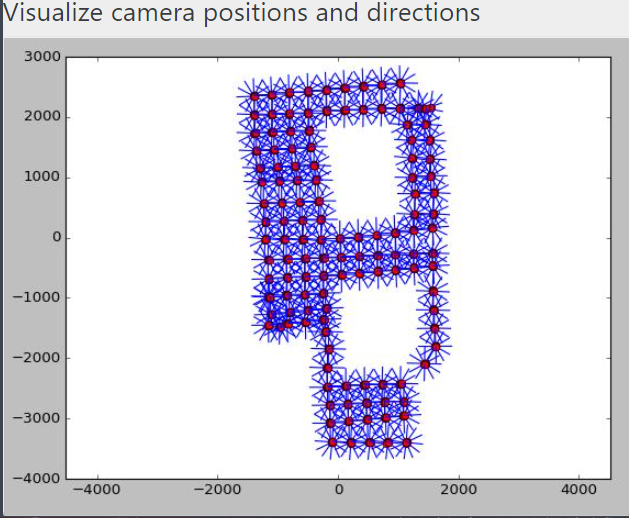

첫 번째 그림처럼 각 지점에 어떤 행동을 취할 수 있는지 알려져 있다고 가정한다.그리고 그 행동을 취했을 때 다음 state로 이동하는데 다음 state는 이전 state와 취한 action에 따라 다른 posing image가 주어진다. Agent의 목표는 Classifier 함수의 Score가 기준점을 넘도록 현재 state에 따른 적절한 행동을 학습하는 것이다.
Dataset 주소:https://www.cs.unc.edu/~ammirato/active_vision_dataset_website/
Model
- Model Overview
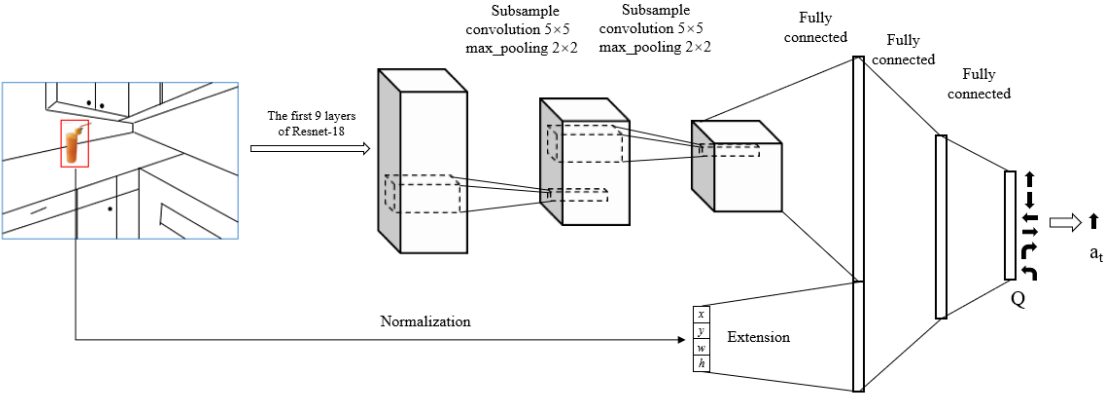
우선 Feature Extractor로 ImageNet으로 pretrained된 the first 9 layers의 Resnet-18을 사용하였다. Resnet-18의 역할은 general feature extractor이기 때문에 학습하지 않고 fixed 한다.
Resnet-18 다음에 추가적으로 2개의 subsampling convolutional modules을 구성하였는데 5X5 stride 1 그리고 max pooling 2X2 stride 2 로 구성하였다.
이렇게 만들어진 Feature Tensor을 FC-layer로 펼친 후 Bounding Box Vector을 Concate을 하여 DQN의 State를 구성한다.
Bounding Box Vector는 Normalizing하는데
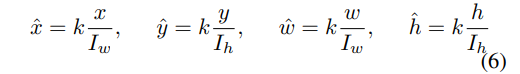
I는 원래 이미지를 뜻한다.
- State
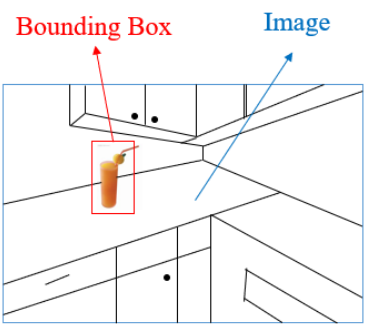
State는 (I,b)의 튜플로 표현되는데, I는 이미지 b는 Bounding Box 위치이다. b=[x,y,w,h]로 정의된다. x,y는 bounding box의 중심위치 w와h는 너비와 높이이다. - Action
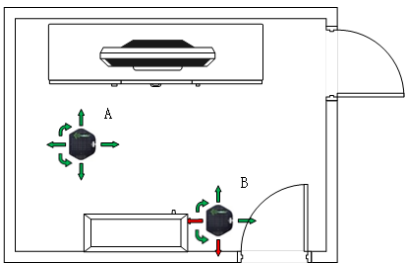
Action은 위 그림에서 확인할 수 있는것처럼 총 6개가 있다. 하지만 상태에 따라 6개의 action이 모두 가능하지 않을 수 있다. 예를 들어 Agent가 오른쪽 모퉁이에 있다면 오른쪽으로 이동할 수 없다. 이 연구에서는 각 State에서 어떤 행동이 불가능한지 알려진 상태에서 진행되었다.
Double DQN

DQN의 목표는 신경망이 최적 Q함수에 근사하는 것이다. 하지만 최적 Q함수 을 표현하는 방법이 없기 때문에 벨만 방정식을 이용해 Target-Q(최적 Q함수)를 표현한다. 하지만 학습을 진행하며 Q를 updating을 하면 Target-Q 역시 흔들려 안정적인 학습이 이루어지지 않는다. 그래서 DQN 을 복사한 Target Q Network를 따로 만들고 점진적으로 parameter를 updating하며 학습이 안정적으로 이루어질 수 있게 한다.
Prioritized Experience Replay
강화학습의 고질적인 문제는 학습 데이터간 Correlation이 심각하다는 것이다 그래서 DQN은 얻은 데이터로 바로 학습하지 않고 우선 Replay Buffer에 보관하고 거기서 Stochastic Sampling을 통해 뽑은 Data들을 Batch화 하고 그것으로 Parameter Updating을 진행한다. 이런 방법으로 Correlation을 상당히 완화하였다.
하지만 Correlation을 완화해도 제대로 학습이 이루어지지 않는 경우가 많은데 그것은 대부분 데이터가 학습에 별 쓸모가 없기 때문이다.
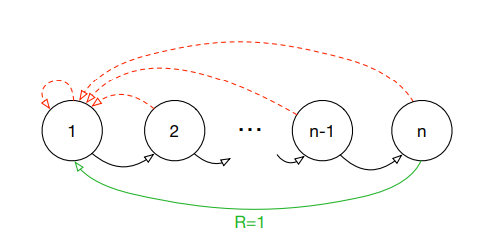
예를 들어 1에서 n으로 가는 MDP문제가 있다고 가정하자 여기서 agent가 n-1에서 n으로 간다면 보상 1을 받을 것이다. 하지만 그 전에는 어떤 행동을 해서 어떤 state로 가든 보상을 받을 수 없는데 만약 Replay Buffer에서 Data를 뽑는다고 가정할 때, 대부분은 TD-error 가 0인 쓸모가 없는 데이터다. 그래서 학습에 도움이 되는 논문의 용어로 Suprising(TD-error가 큰)한 데이터에 우선순위를 매겨 더 중요하게 학습하는 방법이 고안되었고 이것을 Prioritized Experience Replay이라고 한다.
이것에 대해서는 다음에 따로 포스팅을 진행할 예정이다.
Reward Function
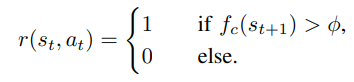
classifier 네트워크를 통과해서 나온 점수가 기준치를 넘기면 1을 부여하고 나머지은 0을 부여하였다. 즉 기준점을 어떤 값으로 정의하냐에 따라 Agent가 학습하는데 결정적인 역할을 한다. 이 실험에서는 0.5로 설정하였을 때 가장 효과적인 성능이 나온다고 설명한다.
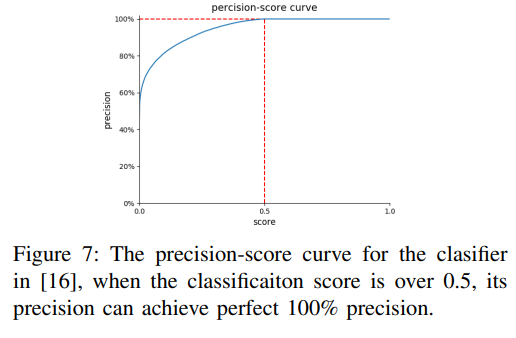
Classifier는 Active Vision DATASET을 소개한 논문에서 만든 Pretrained Classifier를 사용하였다.
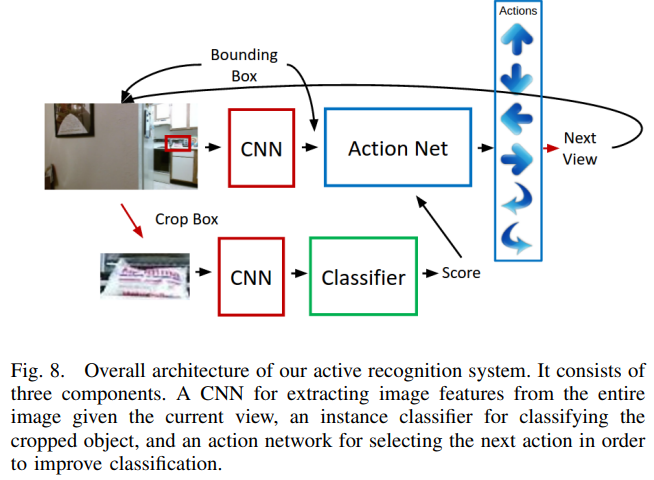
Experiment and Result
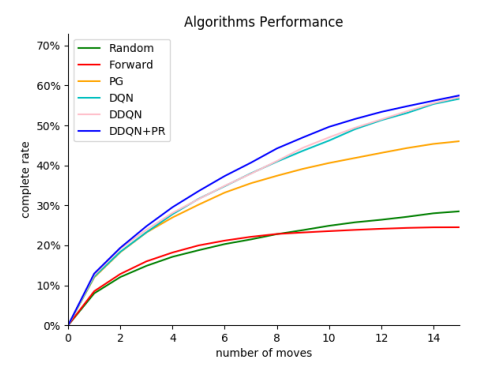


위 보는것과 같이 DDQN과 DDQN+PR을 사용하였을 때 Acitve Object Detection이 잘 수행되는 것을 볼 수 있다. 그런데 이 실험에서는 우선순위를 얼마나 중요하게 따질 건지를 정하는 값을 0으로 설정하였는데 값에 따라 성능이 바뀔 수 있다.
Conclusion
이 논문에서는 Double DQN 그리고 Prioritized Experience Replay 을 이용해서 Active Object Detection을 수행하는 방법을 제시하였다. 내가 주목할 점은 Prioritized Experience Replay를 사용했다는 점이다. DQN은 Replay Buffer에서 Randomly하게 Sample를 선택하고 그것을 기반으로 Network Updating을 함으로써 Correlation을 상당히 극복하였다. 하지만 대부분의 경험들은 학습에 별로 쓸모없는 Garbage Data로 학습에 정말 중요한 데이터는 극소수다.(TD-error가 크다) 이 논문에서는 그것을 해결하기 위해 Prioritized Experience Replay를 사용했는데 내가 지금까지 읽은 논문 중에서 이 방법을 사용한 것은 이게 처음이다. 앞으로 프로젝트에서 나도 이 방법을 사용해 Sampling해보고 성능을 비교해 볼 계획이다.
Reference
- Xiaoning Han et al(2018). Active Object Detection Using Double DQN and Prioritized Experience Replay. IEEE
- Tom Schaul et al(2016). PRIORITIZED EXPERIENCE REPLAY. ICLR
- P. Ammirato, P. Poirson, E. Park, J. Kosecka, and A. C.
Berg, “A dataset for developing and benchmarking
active vision,” CoRR, vol. abs/1702.08272, 2017 - Z. Wang, N. de Freitas, and M. Lanctot, “Dueling
network architectures for deep reinforcement learning,”
CoRR, vol. abs/1511.06581, 2015.
