논문 출처: https://arxiv.org/abs/1611.03718
Object Detection 의 R-CNN 계열의 알고리즘은 바로 물체를 찾는 것이 아니라 Region Proposal 과정이 선행된다.
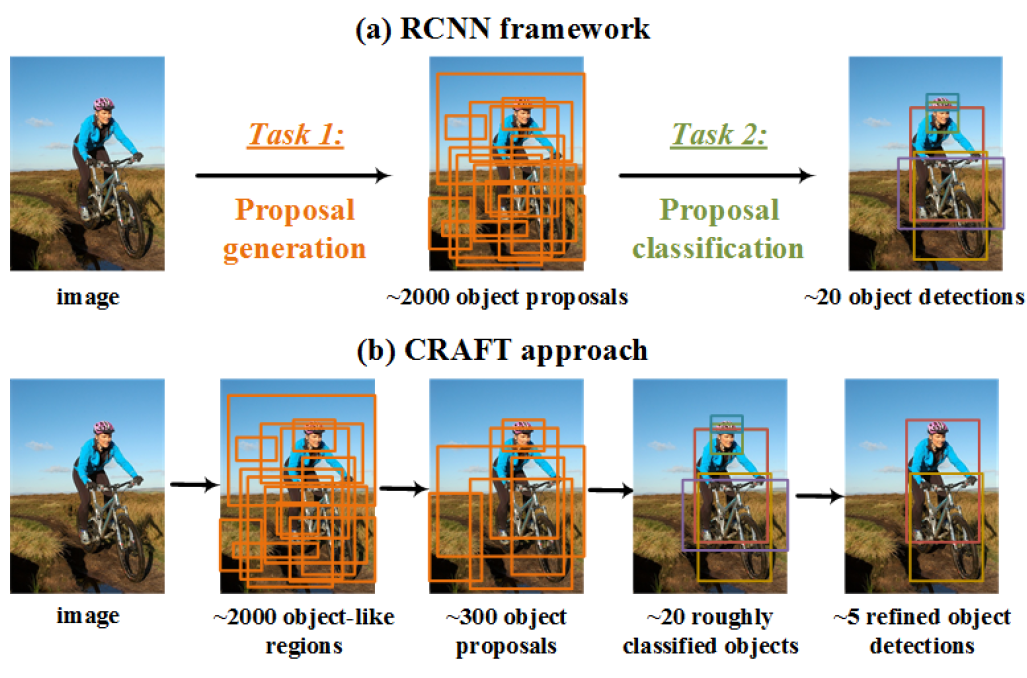
하지만 이 과정에서 Computational Cost가 발생하고 무엇보다 인간이 사물을 보는 방식이 아니기 때문에 Region Proposal 없이 사물을 인식하는 것에 대해 여러 가지 방법으로 연구 되고 있다.
그 중에서 Deep Reinforcement Learning 방식으로 Object Localization 하는 방식을 소개하려 하고 한다.
Introduction
기존 Object Detection 방식은 Convolution Layer을 이용해 pixel 단위에서 사물을 추론해 나간다. 하지만 인간은 이렇게 사물을 인식하지 않는다. 먼저 전체 배경에서 자신이 집중해야 하는 물체를 발견하면 더 자세히 보는 식으로 사물을 인식해 나가는데 이것을 TOP-DOWN Scanning이라고 한다.
Active Object Localization with Deep Reinforcement Learning (Juan C. Caicedo, CVPR)에서 처음으로 DQN을 이용해서 TOP-DOWN 방식의 Object Detection을 시도하였다.


이렇게 전체 사진에서 Agent는 Ground Truth와 최대한 겹치는 Bounding Box를 찾기 위해 자신의 State (feature map)에 적절한 Action을 취한다.
위 논문에서 Agent가 취할 수 있는 Action은 그림과 같이 총 9개이다. Action은 Discrete임에도 불구하고, State Sapce가 크기 때문에 (Scale Change) Local Minima에 빠질 위험이 있고 실험 결과 R-CNN을 넘지 못했다.
이 논문에는 그것을 해길하기 위해 Hierarchical 방식을 사용하여 State space를 규격화 하였고 이전 논문보다 더 효율이 좋다는 것이 실험을 통해 증명 되었다.
MDP formulation
강화학습을 이용하기 위해 가장 중요한 것은 문제들을 MDP 조건에 맞게 정의해야 한다. MDP 는 로 이루어진 Tuple 인데 구체적으로는 와 그리고 를 정의한 후 적절한 DRL 알고리즘을 선택해야 한다.
-
State
이 논문에는 두 가지 타입의 정보를 취합하여 State를 구성하였는데 첫 번재는 Image-Zooms Model에서 추출된 정보이다. 두 번째는 Action History다. Action History를 학습하게 함으로써 같은 실수를 반복하는 것을 막도록 유도하였고 실제로 유의미한 효과가 있음이 밝혀졌다. -
Action
Action은 총 6개로 구역을 선택해 이동하는 Movements 5개 그리고 Terminal이다.
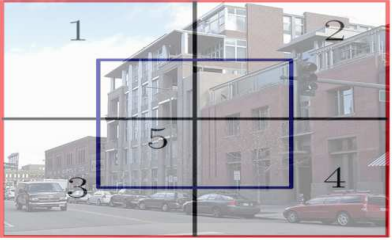
이 논문에서는 Hierarchical 하게 이미지를 보기와 같이 5등분 하고 그 중 하나를 선택하는 방식으로 이루어진다. Region을 선택했다면 이제 선택된 Region이 State가 되고 다시 거기서 5등분 되는 과정을 반복하면서 Agent는 최적의 Bounding Box를 찾는 Policy를 학습해 나간다.
- Reward
MDP formulation에서 제일 중요한 것은 Reward function을 제대로 정의하는 것이다. Reward를 얼마나 정교하게 정의하냐에 따라 Agent의 Performance가 완전히 달라진다. 원래 Hand-Crafted로 Reward function을 정의했지만 최근에는 Agent가 Reward function을 찾는 Inverse Reinforcement Learning이 활발하게 연구중이다. 하지만 이 내용은 이번 글과는 관련이 없고 또 너무 어렵기 때문에 자세하게 언급하지는 않겠다. 이 연구에서는 Active Object Localization with Deep Reinforcement Learning (Juan C. Caicedo, CVPR) 에서 정의한 Reward function을 그대로 사용하였다.
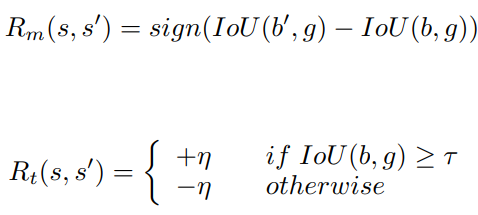
현재 state에서의 Iou 값과 action을 취한후 state에서 IOU를 비교하여 작으면 -1 크면 1을 부여한다. 그리고 terminal action을 취할 때는 다른 보상 체계를 사용하는데 IOU가 보다 크면 1보다 큰 값을 보상으로 낮으면 -1보다 더 작은 값을 보상으로 지급한다. 이 연구에서는 η=3으로 정의하였다.
- DQN
벨만 최적 정리에 의해 각 상태에 가장 Action Value를 선택한다면 최적 가치를 얻을 수 있다. 그러므로 우리가 찾아야 하는 것은 각 상태에 있는 행동들에 대한 Q 값들이다. Q를 찾는 것은 함수를 근사해나가는 과정인데 가장 대표적으로 쓰이는 알고리즘이 DQN 알고리즘이다. 신경망을 통해 Gradient Descent 방식으로 각 상태에 따른 Q 함수를 찾아 나서는데 만약 최적 Q 함수에 수렴한다면 더이상 신경망 parameter에 갱신이 없으므로 학습이 종료된다. 아래는 DQN Pseudocode이다.

Model
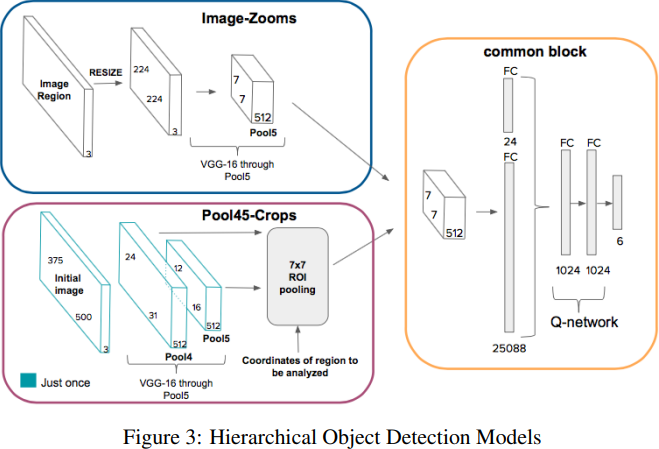
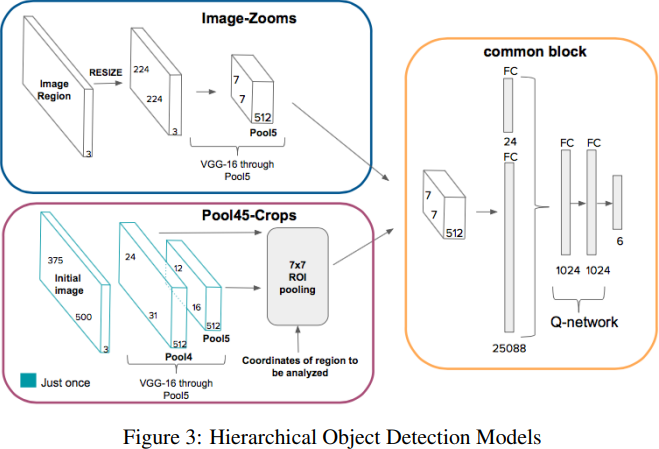
이 연구에서는 Feature Extractor 2개를 구성하고 Zoom 방식과 Computer Vision의 Roi Pooling 방식을 비교하였다.
- Image-Zooms 에서는 현재 Region이 input으로 들어간다. Region 이미지는 224X224로 resized되고 VGG-16을 통과한다.
- Pool45-crops는 Region Proposal을 위해 대표적으로 쓰이는 방식중 하나인 Roi Pooling을 이용하였다.
Image-Zooms 방식으로 만들어진 state와 Pool45-Crops 방식으로 만들어진 state를 각각 DQN에 넣어 모델의 성능을 비교한 결과 후술하겠지만 Image-Zooms 방식이 더 높은 성능을 달성하였다. 인간이 보는 것처럼 중요한 사물을 전체 사진에서 찾았을 때 자세히 Zoom 하는 방식을 Deep Reinforcement Learning을 통해 모델링한 결과이다.
Training
-
Exploration-Exploitation
이 연구에서는 DQN에서 사용하는 대표적인 Exploration 방식인 방식을 사용하였다. 특이한 점은 이전 논문에서는 Trigger Action을 Agent가 잘 학습하도록 유지하기 위한 특별한 장치가 없었지만 이 연구에서는 지금 상태가 IOU가 0.5 보다 크고 exploration을 해야하는 상황에서는 Trigger를 선택하도록 하였다. -
Learning trajectories
이 연구에서는 이미지에서 agent가 어떤 object를 봐야 하는지에 대해서 알려주지 않았다. 이것은 agent가 자연스럽게 exploration 전략을 학습하도록 유도하였다. -
Experience Replay
Reinforcement Learning의 고질적인 문제는 데이터 끼리의 Correlation 이다. 왜냐하면 Reinforcement Learning에서 데이터는 Agent가 환경과 상호작용을 진행하며 생성되는데 지금 데이터는 이전의 데이터에 영향을 받을 수 밖에 없다. 이것은 Agent가 Local Minima에 빠지게 만든다. 그래서 얻은 데이터로 바로 학습을 진행하지 않고 Replay Buffer에 저장하고 random으로 데이터를 뽑아 신경망을 학습 시킨다. 이 연구에서는 1000개의 데이터를 Replay Buffer에 저장한 후 100개씩 랜덤으로 뽑아 학습을 진행하였다. -
Discount factor
Agent의 목표는 잘 정의된 MDP 안에서 누적 보상을 최대화 하는 것이다. 이것을 Return이라고 하며
로 정의한다. 를 Discount factor라고 하며 의 값은 미래 보상의 중요 가중치를 나타낸다. 이 연구에서는 로 정의하였다.
Experiment
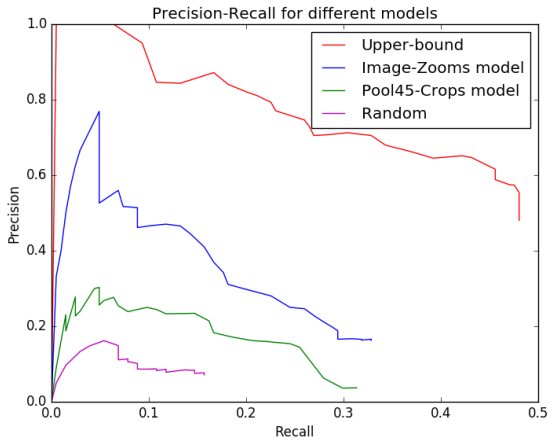
실험결과 기존 Region Proposal (Pool45) 보다 높은 성능을 보인 것을 확인할 수 있다.
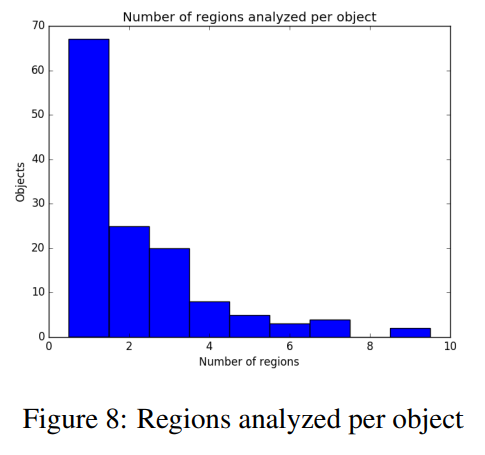
또한 물체를 찾는데 그렇게 긴 시간이 걸리지 않는 것을 확인할 수 있다 Number of regions는 Step이라고 생각하면 된다. 대부분의 test에 3step 만에 Object Localization을 수행해냈다.
Result

Conclusion
이 연구에서는 선행 연구를 계승해 강화학습을 이용해 더 효율적으로 Object Localization을 수행했다. 기존 Object Detection의 Region Proposal 없이 Agent를 이용한 방식은 창의적이라고 생각한다. 앞으로도 비전에 강화학습을 응용한 많은 연구들을 소개할 예정이다.
Refernce
-
Miriam Bellver Bueno et at(2016). Hierarchical Object Detection
with Deep Reinforcement Learning. NueralIPS -
Juan C. Caicedo(2015). Active Object Localization with Deep Reinforcement Learning
.CVPR -
Yongxi Lu(2016).Adaptive Object Detection Using Adjacency and Zoom Prediction
.CVPR -
Volodymyr Mnih(2013).Playing Atari with Deep Reinforcement Learning. NueralIPS
