
최근 OpenAI는 텍스트 기반의 에이전트에서 더 나아가, 음성 기반의 자연스럽고 직관적인 소통을 가능하게 하는 음성 AI 모델을 새롭게 선보였습니다. 이번 출시는 음성-텍스트 변환(STT, Speech-to-Text) 모델과 텍스트-음성 변환(TTS, Text-to-Speech) 모델을 포함하며, 개발자들이 더욱 강력하고 맞춤화된 음성 에이전트를 손쉽게 구축할 수 있도록 지원합니다.
📋 이로써 개발자들은 고객 서비스, 교육, 콘텐츠 제작, 헬스케어 등 다양한 산업 분야에 음성 인터페이스를 접목시킨 혁신적인 애플리케이션을 손쉽게 설계할 수 있게 되었습니다.

🔗 Reference Links
OpenAI는 음성으로 말하면, AI가 음성으로 답하는 'Voice Agent' 시대를 본격적으로 열고자 합니다.
-
Voice Agent란 쉽게 말해, 음성으로 사용자와 대화할 수 있는 음성 기반의 AI 시스템입니다. 사용자의 말을 듣고, 그 의미를 이해한 뒤, 다시 말로 응답하는 구조를 가지고 있죠.
- 단순한
음성 인식 기술(STT)이나음성 합성 기술(TTS)을 넘어서, 실제로 대화를 나누는 에이전트를 의미합니다.
- 단순한
OpenAI는 이 Voice Agent를 누구나 손쉽게 만들 수 있도록 하기 위해, 이번 발표를 통해 새로운 음성 모델들을 공개하는 한편, 기존의 텍스트 기반 에이전트를 음성 기반 에이전트로 손쉽게 확장할 수 있는 개발자 도구인 Agents SDK도 함께 제공했습니다.
-
이번 발표에서 OpenAI는 먼저
Voice Agent를 만드는 두 가지 주요 방식을 소개합니다.-
Speech-to-Speech 방식: 사용자의 음성을 바로 인식해, 실시간으로 음성으로 응답하는 구조입니다. 한번에 빠르고 자연스러운 대화를 지원하지만, 모델 간 커스터마이징이 어렵습니다.
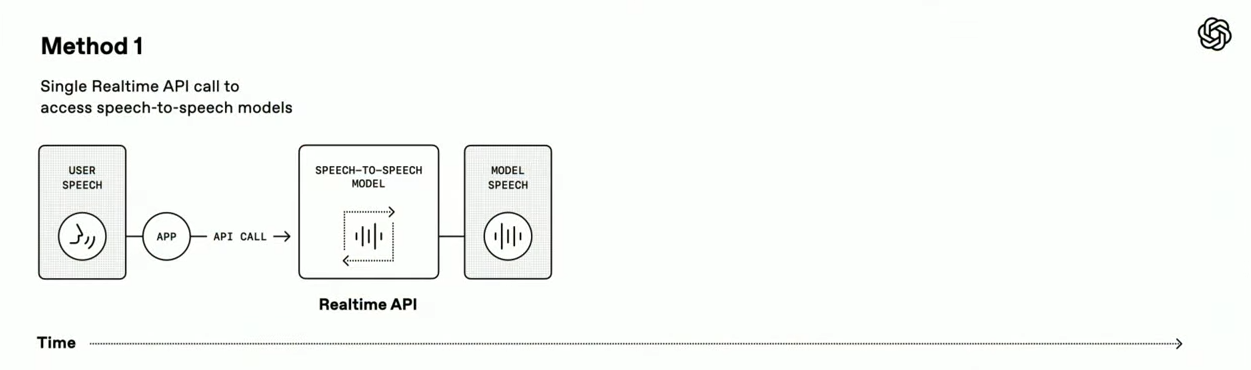
-
Chained 방식: 사용자의 음성을 텍스트로 바꾸고(STT), 텍스트 기반 LLM이 답을 생성한 뒤, 다시 음성으로 바꾸는(TTS) 모듈형 구조입니다. 각 구성 요소를 자유롭게 조합할 수 있어 많은 개발자들이 선호하는 방식입니다.
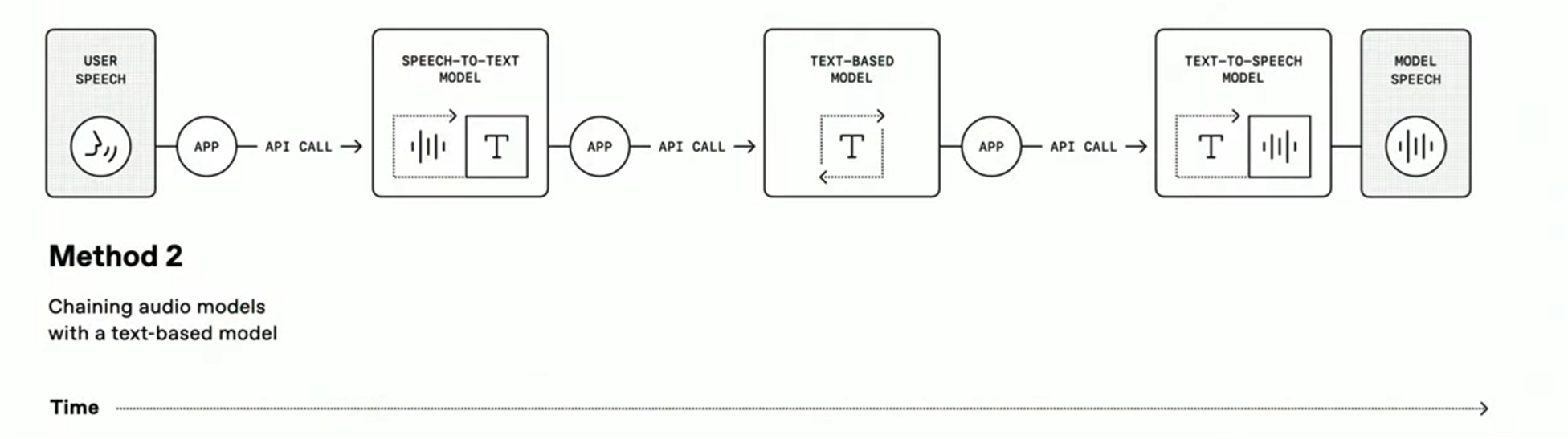
-
OpenAI는 많은 개발자들이 이 Chained 방식을 중심으로 Voice Agent를 구현할 것으로 보고, 여기에 최적화된 새로운 Speech-to-Text(STT) 모델과 Text-to-Speech(TTS) 모델을 발표했습니다.
이 글에서는 이러한 음성 모델들이 어떤 점에서 발전했는지, 실제로 어떻게 사용할 수 있는지 자세히 살펴보겠습니다.
1. 새로운 음성-텍스트(STT) 모델
OpenAI는 GPT-4o 기반의 새로운 음성-텍스트 모델 두 가지를 출시했습니다.
- GPT-4o-transcribe
- GPT-4o-mini-transcribe
이 모델들은 Whisper 시리즈의 후속작으로, 더 많은 데이터와 개선된 학습 기법을 통해 다양한 언어와 환경에서 더 낮은 오류율과 더 빠른 응답 속도를 보여줍니다.
(참고) Whisper는 OpenAI에서 개발한 모델로, 대규모 데이터셋을 활용해 훈련되었습니다. 약 68만 시간 이상의 음성 데이터를 기반으로 학습되었으며, 이 중 약 2/3가 영어이고 나머지는 한국어, 일본어, 중국어 등 다양한 언어로 구성되어 있습니다.
- 초기 버전 (2022년 9월 출시)
- Whisper large-v2 (2022년 12월)
- Whisper large-v3 (2023년 11월)
GPT-4o-transcribe & GPT-4o-mini-transcribe
GPT-4o-transcribe 모델은 정확도 중심의 고성능 모델이며, GPT-4o-mini-transcribe는 경량화된 모델로서 비용과 속도 측면에서 유리합니다. 두 모델 모두 수조 단위의 오디오 토큰으로 학습되었으며, 고품질 다국어 데이터셋을 활용하여 억양, 속도, 잡음 등 다양한 변수에 강인한 특성을 보입니다.
특히 mini-transcribe 모델은 소형임에도 불구하고 높은 정확도를 유지하며, 저사양 환경이나 모바일 기기 등에서도 활용이 용이하도록 설계되었습니다.
성능 비교 및 우수성
OpenAI가 진행한 FLEURS(Few-shot Learning Evaluation of Universal Representations of Speech) 벤치마크 테스트 결과, GPT-4o 계열 모델은 Whisper v-2와 v-3는 물론, Google의 Gemini, Meta의 Scribe, Anthropic의 Nova 모델들과 비교해도 전반적으로 더 낮은 Word Error Rate(WER)를 기록했습니다.
- GPT-4o-transcribe와 mini-transcribe는 영어, 스페인어, 중국어, 일본어, 한국어, 힌디어 등 주요 언어 전반에서 낮은 WER을 기록하며 다국어 지원 능력에서 독보적인 경쟁력을 보였습니다.
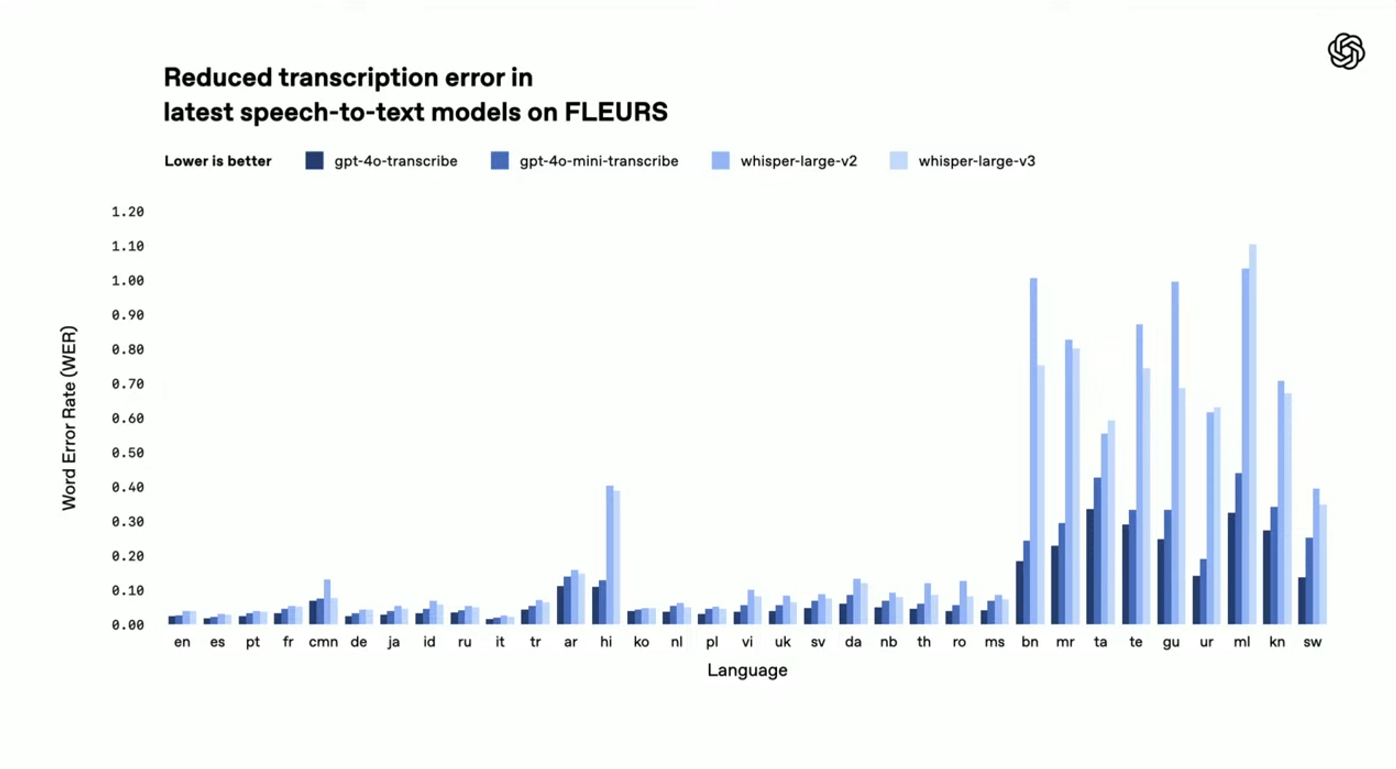
Whisper 시리즈와 비교
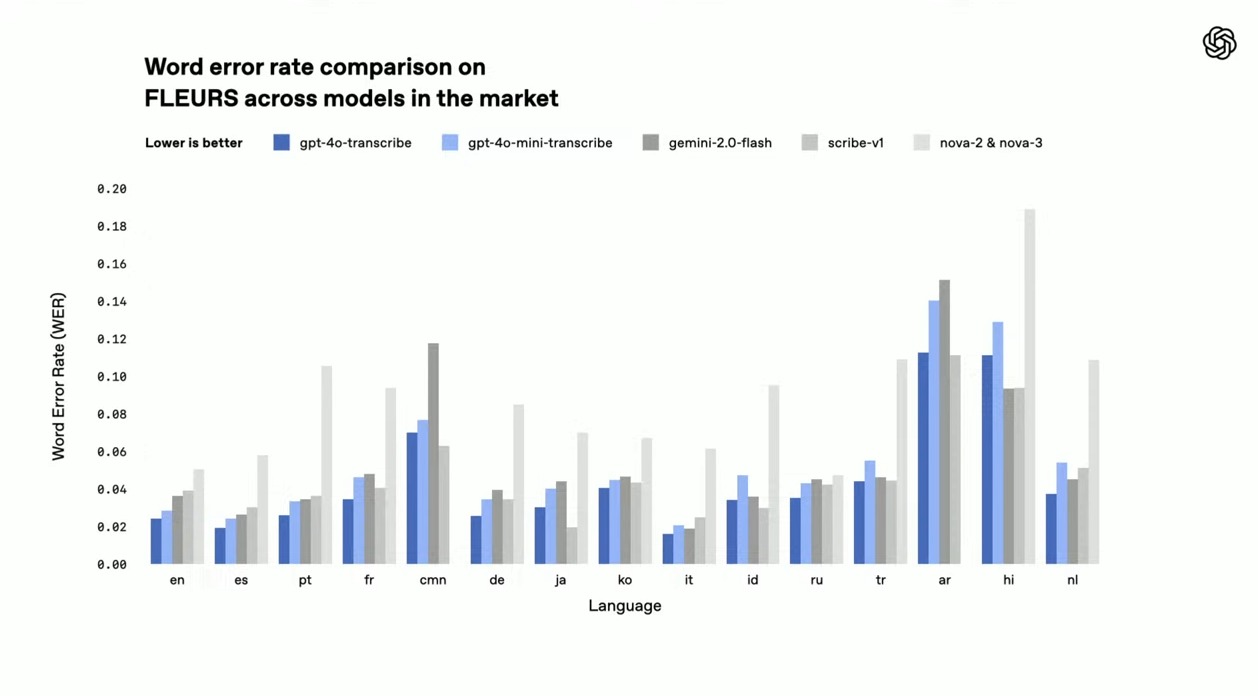
타사 제품과 비교
-
WER (Word Error Rate):
- 낮을수록 성능이 좋은 것을 의미합니다 (즉, 오류가 적음)
-
파란색 계열:
gpt-4o-transcribe(진한 파랑)gpt-4o-mini-transcribe(중간 파랑)
-
회색 계열 (경쟁사 모델):
gemini-2.0-flash(회색)scribe-v1(짙은 회색)nova-2 & nova-3(밝은 회색)
-
특히 Whisper-large-v3 모델과 비교할 때 일부 언어에서는 절반 이하의 오류율을 기록하였으며, 이는 다양한 억양과 빠른 발화를 인식하는 데 큰 강점을 나타냅니다.
실시간 스트리밍 API 지원
이번 API는 실시간 오디오 스트리밍을 지원합니다. 개발자는 사용자의 발화가 끝나는 시점을 자동으로 감지하고 즉시 텍스트 변환 결과를 받을 수 있으며, 이 과정에서 지연(latency)을 최소화할 수 있습니다.
여기에 OpenAI는 두 가지 고급 기능을 기본 제공하여 개발자의 부담을 줄였습니다:
- 잡음 제거 (Noise Cancellation):
- 복잡한 배경 환경에서도 안정적인 인식 성능 유지
- 의미 기반 음성 활동 감지 (Semantic Voice Activity Detection):
- 사용자의 발화 종료 시점을 모델이 스스로 파악하여 처리
2. 새로운 텍스트-음성(TTS) 모델: GPT-4o-mini-TTS
이번에 함께 공개된 텍스트-음성 모델 GPT-4o-mini-TTS는 단순한 텍스트 낭독 기능을 넘어, 감정과 스타일을 지정하여 음성을 생성할 수 있는 지시 기반 음성 합성(Instructable Speech Synthesis) 기능을 지원합니다.
예를 들어, "기운찬 라디오 DJ처럼 말하기" 또는 "침착한 상담원처럼 말하기"와 같은 프롬프트(prompt)를 입력하면, 모델은 해당 지시어에 맞춰 톤과 억양, 감정을 반영한 자연스러운 음성을 생성합니다.
OpenAI는 이를 “어떻게 말할 것인가(How to say)”까지 제어할 수 있는 TTS 모델로 소개하고 있으며, 실제로 발표 데모에서는 "격정적인 메드 사이언티스트", "다정한 응원" 등의 스타일을 적용한 음성을 실시간으로 재생하며 모델의 표현력과 다양성을 보여주었습니다.
- 뿐만 아니라, 이 TTS 모델은 기존처럼 고정된 목소리 스타일이 아니라, 기본 음색에 다양한 성격을 부여하는 방식으로 작동합니다.
- 그 말인 즉, 목소리 자체를 바꾸기보다는, “같은 목소리를 다양한 성격이나 감정으로 조절”할 수 있도록 설계된 것이 특징입니다.
- 이 방식은 하나의 음성 캐릭터를 다양한 맥락에서 일관성 있게 활용할 수 있도록 해줍니다.
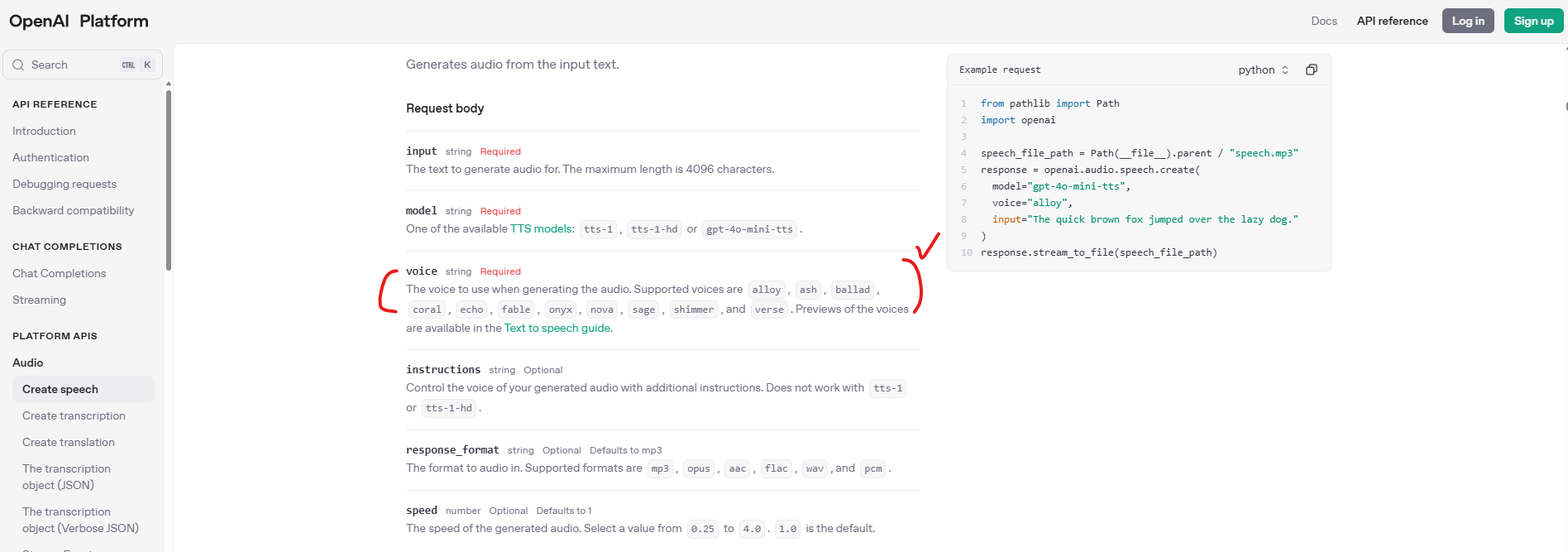
현재 제공되고 있는 Voice 종류 (링크)
활용 사례:
고객 서비스: 상황에 따라 공감, 위로, 안내 등의 정서 표현 가능교육 콘텐츠: 친절하고 흥미로운 설명 스타일 구현창작/스토리텔링: 캐릭터별 말투 구현으로 몰입감 강화음성 챗봇 UX: 사용자 감정에 맞는 응답 스타일 제공
OpenAI는 이를 체험해볼 수 있도록 openai.fm이라는 웹 데모 사이트를 공개했습니다.
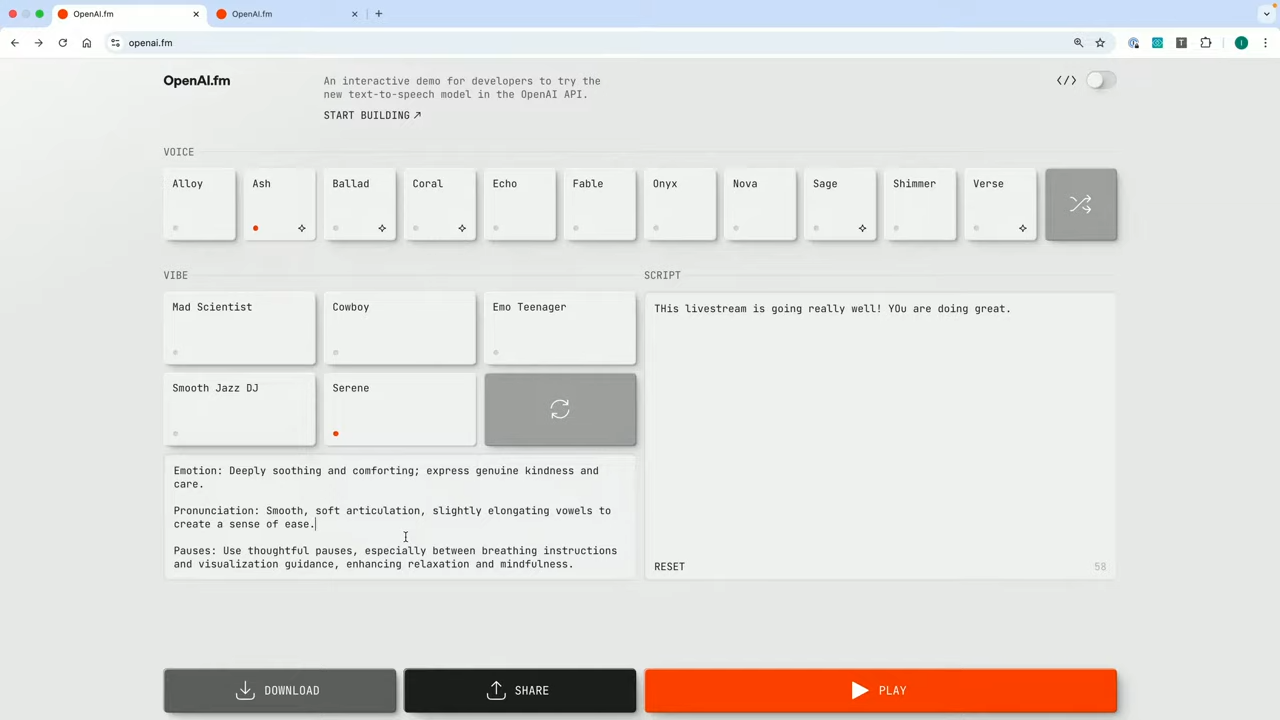
해당 사이트에서는 다양한 목소리 스타일을 선택하고, 직접 텍스트와 말투를 입력해보며 실시간으로 음성을 생성할 수 있습니다.

실제 openai.fm 들어가서 캡쳐한 화면 (다음과 같이 API 코드를 제공함)
또한, Python, JavaScript, curl 등으로 바로 호출 가능한 API 코드 예제도 제공되어, 개발자가 손쉽게 자신의 앱이나 서비스에 바로 적용할 수 있도록 지원하고 있습니다.
3. 모델의 기술적 혁신
OpenAI는 이번 오디오 모델을 개발하며 음성 AI의 근본적인 한계를 극복하기 위해 다음과 3가지에 집중했다고 합니다.
- Pretraining with authentic audio datasets
- Advanced distillation methodologies
- Reinforcement learning paradigm

https://openai.com/index/introducing-our-next-generation-audio-models/
1) 오디오 중심 데이터셋 기반 대규모 사전 학습
- 다양한 억양, 언어, 환경의 오디오 데이터를 기반으로 모델을 훈련함으로써, 보다 일반화된 음성 인식 능력을 확보했습니다.
2) 첨단 Distillation 기법
- 대형 모델의 지식을 작은 모델에 효과적으로 이전하는 distillation 기술을 통해 mini 모델의 성능을 크게 향상시켰습니다. 이는 연산 리소스가 제한적인 환경에서도 실용적인 성능을 보장합니다.
3) 강화 학습 적용
- RL(Reinforcement Learning) 기법을 통해 모델이 오류를 줄이고 실제 사용자 발화에 더 민감하게 반응할 수 있도록 튜닝되었습니다.
4. Agents SDK를 통한 음성 에이전트 구현
OpenAI는 기존 텍스트 기반 에이전트를 음성 입력과 음성 응답이 가능한 Voice Agent로 빠르게 전환할 수 있도록 Agents SDK에 강력한 기능을 추가했습니다. 실제 데모에서는 지난주 공개된 텍스트 기반 고객지원 에이전트를 불과 9줄의 코드 수정만으로 음성 기반 에이전트로 확장하는 과정을 보여주었습니다.
🎬 데모 시나리오: 텍스트 기반 → 음성 에이전트로 확장
데모에서 사용된 예시는 사용자의 주문 내역을 확인해주는 고객지원 에이전트였습니다. 원래는 텍스트 입력을 받고, 주문 정보를 출력하는 기본적인 구조였지만, 여기에 음성 기능을 추가하기 위해 아래와 같은 단계가 진행되었습니다.
🧩 핵심 변경 1: WebSocket 기반 오디오 처리 로직 추가
UI에서 음성 입력을 받기 위해, 백엔드에서는 WebSocket을 통해 오디오 청크(audio chunks)를 수신하도록 처리합니다:
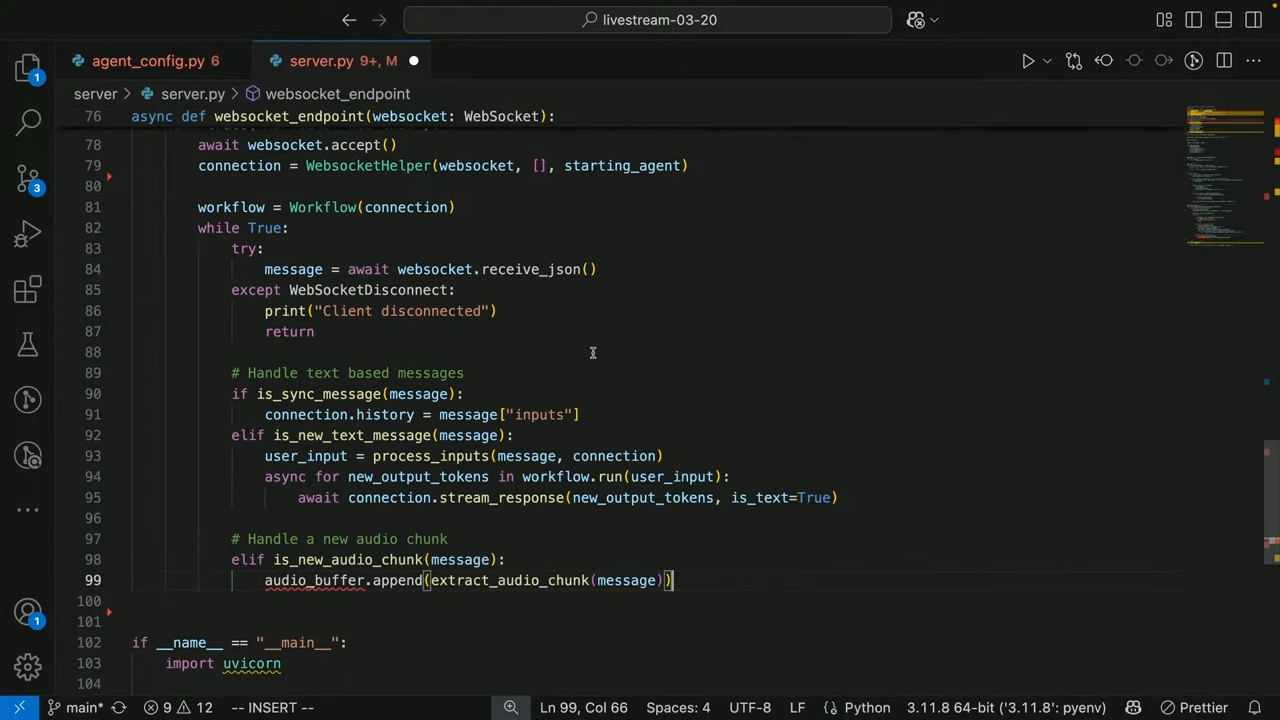
server.py의websocket_endpoint()함수 안에서 음성 메시지 처리를 위한 로직이 다음과 같이 추가되었습니다:
# 1. 오디오 청크 수신
elif is_new_audio_chunk(message):
audio_buffer.append(extract_audio_chunk(message)) # 청크를 버퍼에 저장
# 2. 오디오 입력이 완료되었을 때 처리
elif is_audio_comp(message):
audio_input = concat_audio_chunks(audio_buffer) # 청크 합치기
# 3. voice_pipeline에 오디오 전달 → 텍스트 처리 → 음성 응답 생성
output = await voice_pipeline.run(audio_input)
# 4. 응답 오디오 이벤트를 UI로 스트리밍
async for event in output.stream():
await connection.send_audio_chunk(event)
# 5. 버퍼 초기화
audio_buffer = []- 이 구조 덕분에, 클라이언트는 음성을 녹음해서 전송하고, 서버는 이를 분석 후 음성으로 다시 응답할 수 있게 됩니다.
🧩 핵심 변경 2: Voice Pipeline 적용
- Voice Pipeline이라는 모듈을 통해 기존 텍스트 워크플로우의 앞뒤에 STT/TTS를 자동으로 연결
음성 처리를 위해 새롭게 도입된 voice_pipeline 이 바로 핵심입니다.
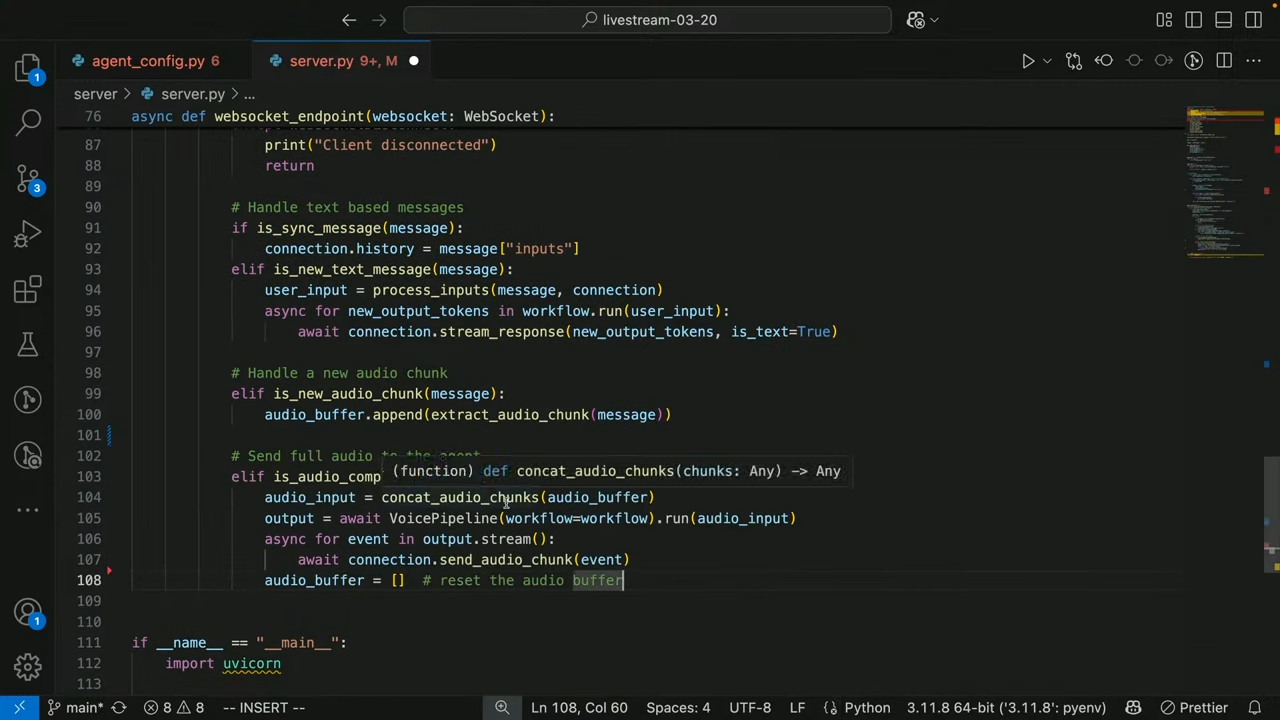
- 텍스트 기반 워크플로우를 음성 입력 및 출력까지 확장하려면, 다음과 같이
VoicePipeline을 통해 기존 워크플로우를 감싸줍니다.
# 기존 텍스트 워크플로우
workflow = build_workflow(...)
# voice_pipeline으로 감싸서 음성 지원 추가
voice_pipeline = VoicePipeline(workflow=workflow)이렇게 감싸준 voice_pipeline 객체는 자동으로 다음 기능을 처리합니다:
- 사용자의 오디오 입력 → STT 변환 (gpt-4o-transcribe)
- 텍스트 워크플로우 실행 → GPT-4o 기반 응답 생성
- 생성된 텍스트 응답 → 음성 변환 (gpt-4o-mini-tts)
🔧 전체 흐름 요약
[사용자 음성] → [청크 수신 및 버퍼링] → [완료된 오디오 → 텍스트 변환] → [LLM 워크플로우 실행] → [응답 텍스트 → 음성 변환] → [클라이언트로 음성 스트리밍]
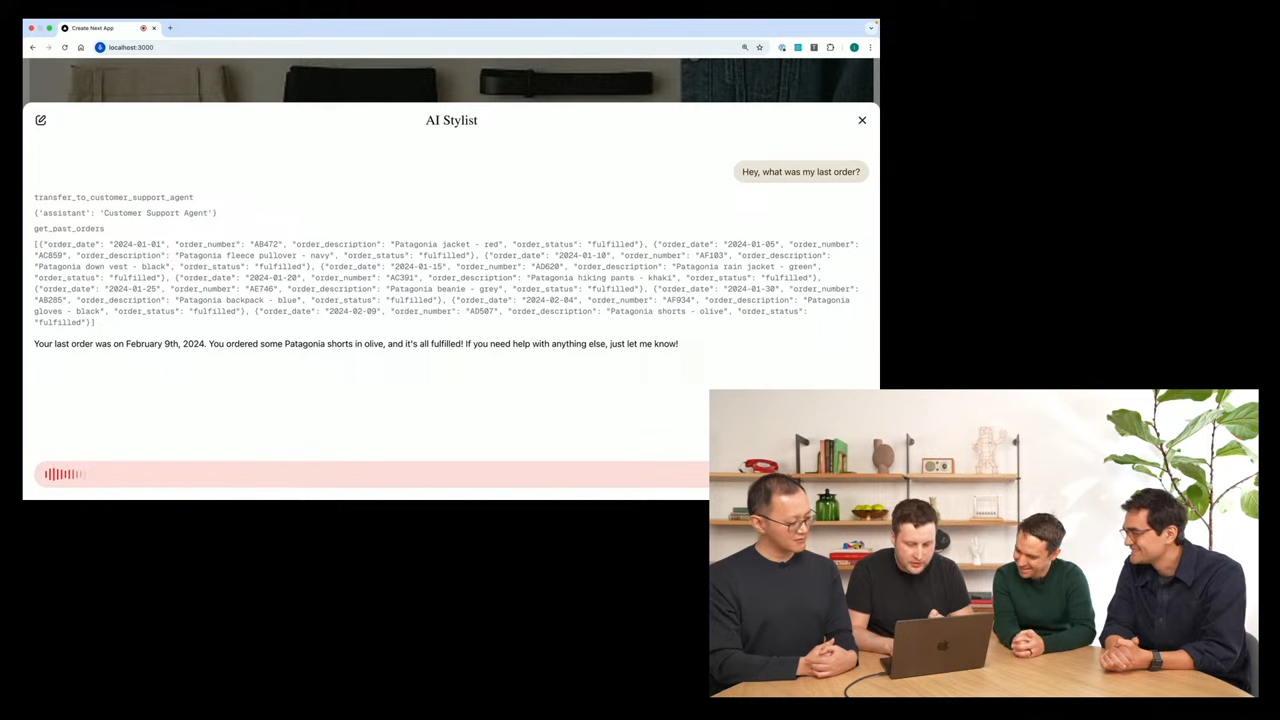
음성으로 챗봇과 대화중 ㄷㄷ
👁️ 디버깅 & 확인: Tracing UI
Voice Agent를 구축하면서 “정확히 어떤 음성을 인식했고, 어떤 응답을 생성했는지”를 확인하기 어려운 경우가 많습니다.
이를 위해 OpenAI는 Tracing UI를 함께 제공합니다.
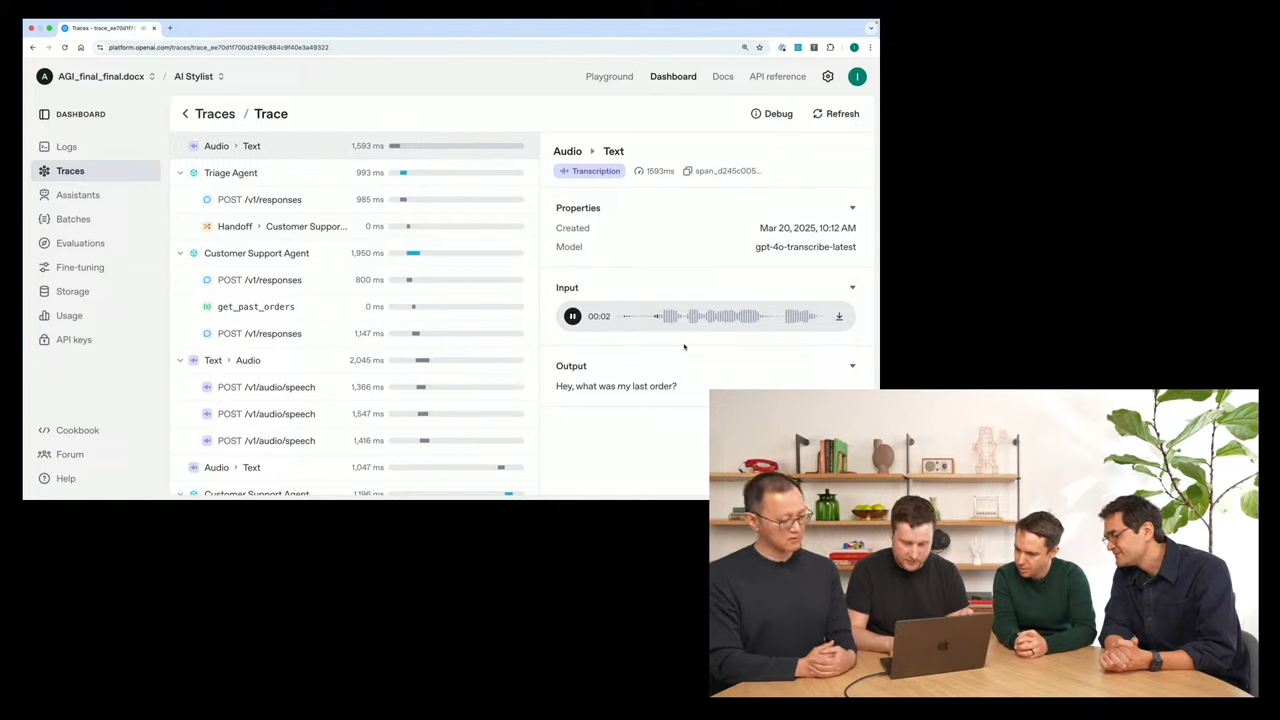
-
Tracing UI를 통해 에이전트의 동작 흐름, 음성 입력, 처리 단계, 오류 발생 등을 시각적으로 분석 가능
- 음성 입력 내용 (재생 가능)
- STT 결과 텍스트
- LLM 호출 내역 및 사용된 툴
- 생성된 텍스트 응답
- TTS 음성 출력
- 전체 처리 시간 및 오류 로그
-
위와 같은 기능들을 시각적으로 확인할 수 있어, 음성 기반 UX의 디버깅과 테스트가 매우 쉬워집니다.
✅ 정리
- 이처럼 Agents SDK의 새로운 음성 기능을 활용하면,
- 기존 텍스트 기반 LLM 서비스에 불과 몇 줄의 코드로 음성 입출력을 추가할 수 있고,
- 복잡한 음성 처리 로직을 직접 구현하지 않고도,
- 실시간 음성 에이전트 수준의 사용자 경험을 손쉽게 만들 수 있습니다.

발표 소개 신규 기능
5. 향후 계획 및 전망
OpenAI는 음성 모델의 정확도 및 맞춤형 기능 확대에 지속적인 투자를 진행할 예정입니다.
특히, 다음과 같은 방향으로 기술 확장을 계획하고 있습니다:
- 사용자 지정 음성(Voice Cloning) 기능의 안전한 도입 방안 검토
- 다국어 TTS 모델의 정교화 및 억양 제어 향상
- 비디오 등 멀티모달 입력/출력 기능과의 통합으로 더욱 풍부한 인터페이스 제공
이번 오디오 모델의 출시는 단순한 성능 향상을 넘어, 음성이라는 인간의 자연스러운 인터페이스를 AI 에이전트와 연결하는 중요한 전환점이 될 것입니다.
OpenAI의 최신 음성 모델은 API를 통해 누구나 사용할 수 있으며, 이를 활용해 더욱 인간 친화적이고 감성적인 AI 시스템을 구축하는 데 큰 도움이 될 것입니다.
또한 OpenAI는 이 모델을 더 많은 사람들에게 알리고, 창의적인 사용 사례를 유도하기 위해 공식 데모 사이트인 openai.fm에서 TTS 콘테스트 이벤트를 진행할 예정입니다. (마감일: 현지시간 기준 2025년 3월 21일, 금요일)
사용자들은 다양한 음성 스타일을 실험해보고, 가장 재미있고 창의적인 음성 응답을 제출하여 OpenAI 로고가 새겨진 특별 제작 한정판 오디오 기기를 받을 수 있는 기회를 얻게 됩니다.

와... 저건 좀 탐난다 ㅋㅋㅋ
이와 같은 활동은 AI 음성 기술이 단순한 기능을 넘어, 일상과 창작의 영역으로 확장되고 있음을 보여주는 대표적인 사례가 될 것입니다.
이번 업데이트도 재밌게 잘 봤는데요! 과연 단순히 whisper보다 좋은 stt 모듈에서 끝날지 아님 재밌는 시나리오가 더 나올지 궁금하군요!!🤔
읽어주셔서 감사합니다 :)
