
안녕하세요! 오늘 나온 기능은 제가 정말정말 기다렸던 기능인데요!! 🙌
참고 링크
2025년 3월 25일, OpenAI는 GPT‑4o 모델을 통해 네이티브 이미지 생성(Native Image Generation) 기능을 정식 출시했습니다. 이번 발표는 단순한 기능 개선을 넘어, AI 이미지 생성이 텍스트와 이미지가 완전히 통합된 옴니모달(Omnimodal) 경험으로 진화했다는 점에서 주목할 만합니다.
바로바로 오늘의 썸네일처럼 "내가 직접 넣어주거나, 사진의 스타일을 바꿔보거나, 그림에 텍스트를 정확하게 넣는 거"가 드디어 가능할 것으로 보입니다!!
😄 사실 이거, 예전에는 너무 하고 싶었지만 늘 한계가 있었죠.
- 특히 텍스트의 소문자/대문자 구분도 정확히 안 되고, 이미지에서 생성된 글씨가 깨지는 것이 아쉬웠는데요…

이제는 아래 뉴스 기사들처럼 너무 편집이 잘되어서 저작권 이슈 얘기가 될 정도로 문제가 되고 있습니다.
바로 이미지 생성해보는 1인 ㅋㅋ 🖼️
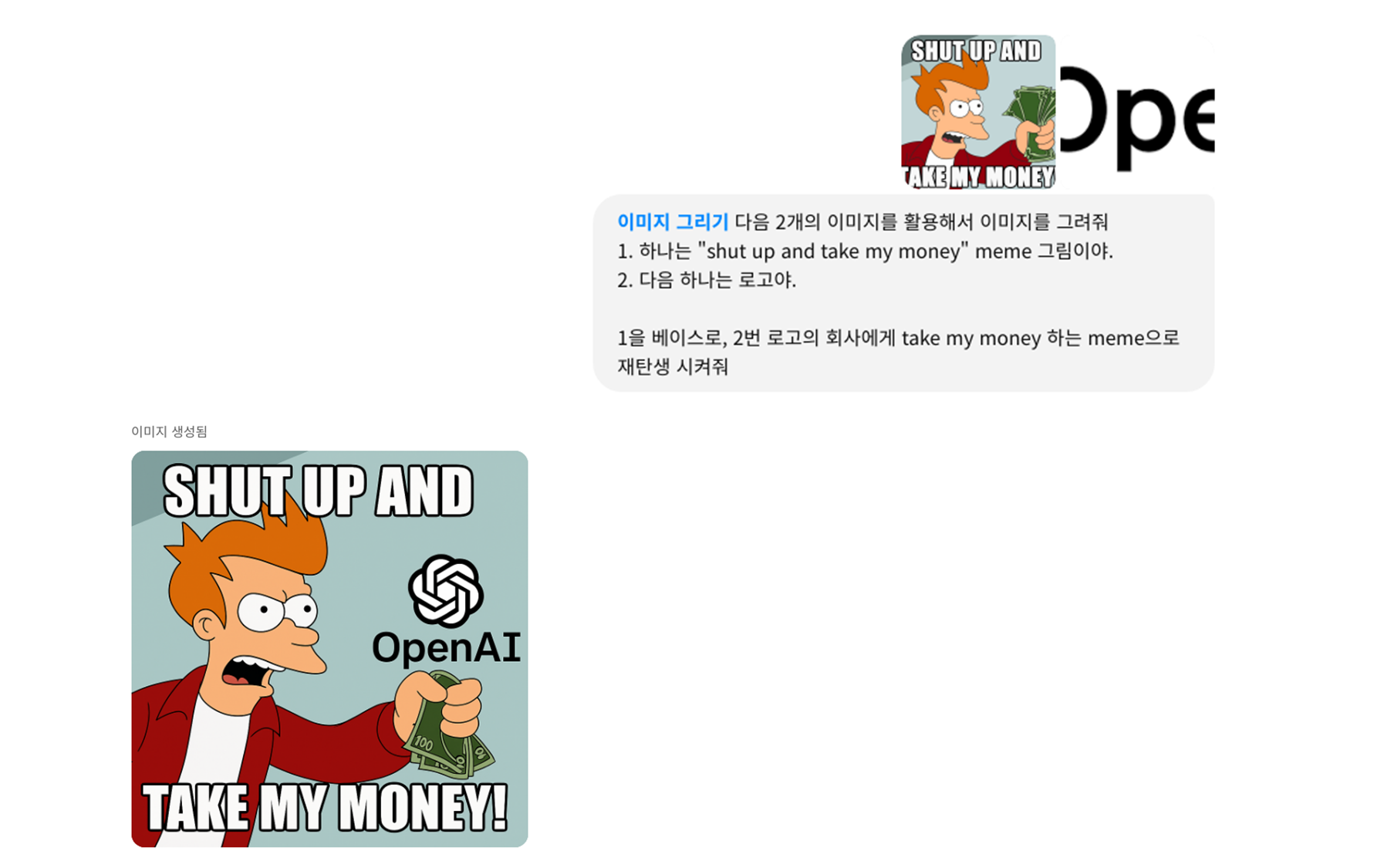
예시1. 유명한 Meme 편집하기 - SH** UP AND TAKE MY MONEY!!
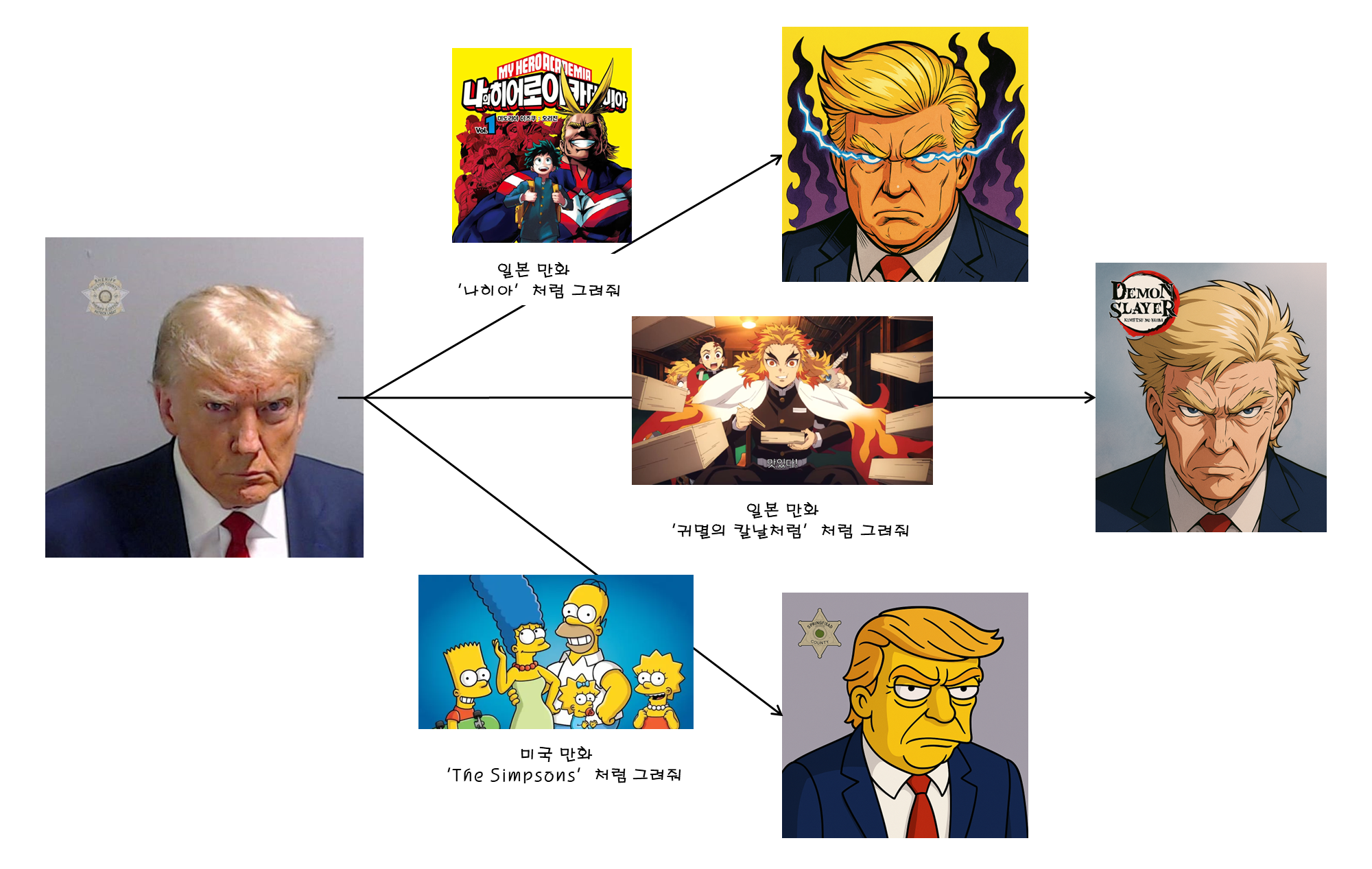
예시2. 트럼프 이미지 편집하기 - 위 조선일보 기사 참고
이번에 업데이트 한 GPT-4o 이미지 생성 기능에서는 그 모든 부분이 정말 기대 이상으로 개선된 것 같아 너무 설레요! 😍 (속도는 좀 느려졌지만)
📌 그럼 어떤 부분이 좋아졌는지 본격적으로 한번 살펴볼까요?
OpenAI는 GPT‑4o에 가장 진보된 이미지 생성기를 통합하며 이미지 생성의 방향을 ‘예쁜 그림’에서 ‘쓸모 있는 도구’로 완전히 전환했다고 설명했습니다.
“We’ve built our most advanced image generator yet into GPT‑4o. The result—image generation that is not only beautiful, but useful.” - OpenAI, March 25, 2025
이전에는 단순히 비주얼이 멋진 이미지를 생성하는 것이 목표였다면, 이제는 실제 작업에 활용할 수 있는 유스케이스 중심으로 발전하였습니다.
ℹ️ 신규 기능 요약
-
🎨 멀티턴 이미지 생성 (Multi-turn Generation)
채팅을 이어가며 이미지 수정/개선 가능. 캐릭터 디자인, 장면 구성에 유리. -
📐 정밀한 인스트럭션 반영
텍스트 기반 복잡한 지시사항 (10~20개 객체 배치 등)도 충실히 반영. -
🧠 인컨텍스트 학습 (In-context Learning)
업로드된 이미지에서 스타일/구성 학습 후 새로운 이미지 생성. -
🌍 월드 지식 연결 (World Knowledge)
텍스트 모델의 지식을 활용해 이미지를 더 똑똑하게 생성. -
✍️ 정확한 텍스트 렌더링 (Text Rendering)
표지판, 메뉴판, 인포그래픽 등 텍스트 포함 이미지도 정확하고 깔끔하게 생성. -
🎭 다양한 스타일 & 포토리얼리즘
만화, 수채화, 디지털 페인팅, 실사 스타일 등 폭넓은 스타일 지원.
본 블로그 포스트는 OpenAI Youtube Demo(Part1)와 OpenAI Blog 내용(Part2)로 나뉩니다.
PART 1. OpenAI Youtube Demo 소개
발표는 실제 데모 시연 중심으로 이루어졌으며, 각 세션이 정교한 텍스트 렌더링, 속성 결합의 정밀도, 밈(meme) 이미지 생성의 유연성, 다중 모달 입력 활용 등을 단계별로 보여주었습니다.
🎬 이미지 생성 품질의 진화
발표 초반에 "GPT‑4o의 이미지 생성 품질은 과거의 모델과는 차원이 다르다"고 강조했습니다.

실제로 아래와 같은 이미지 생성 데모를 통해 다음을 보여주었습니다.
📷 DEMO 1. POV(1인칭 시점)의 이미지 요청:
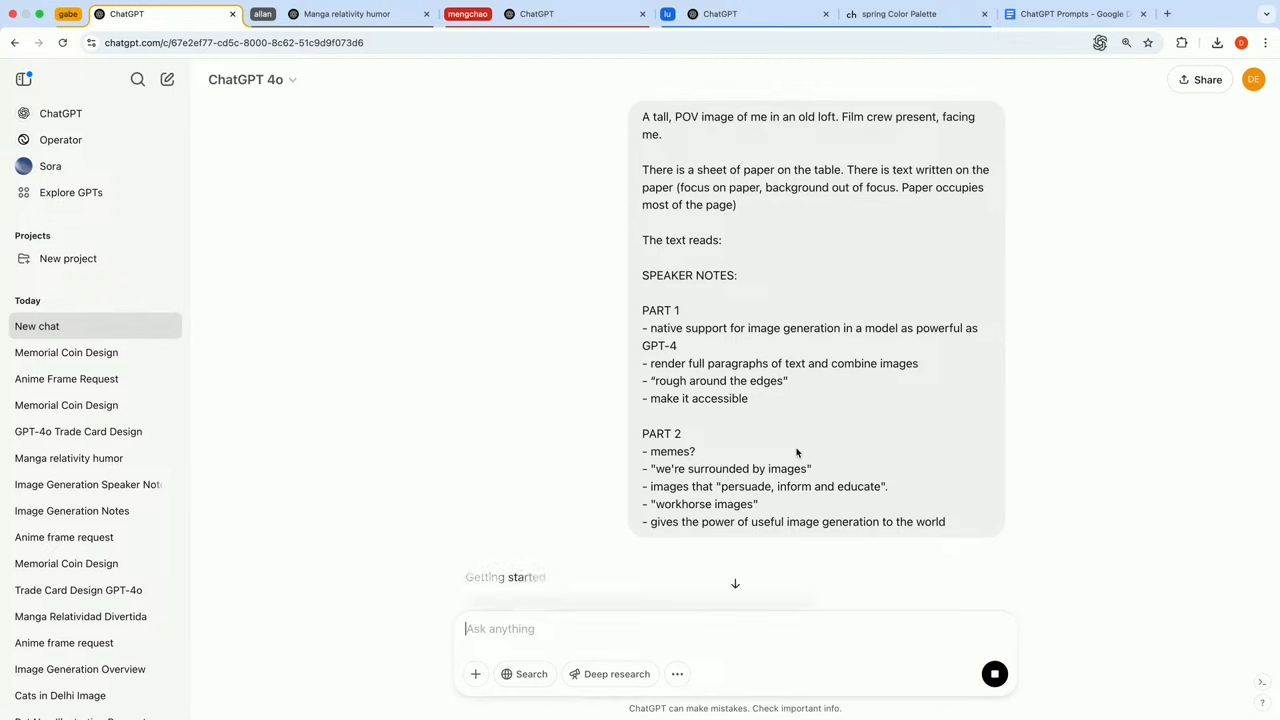
사용자의 시점에서 종이 위 발표 노트가 있고, 배경에는 촬영 팀이 있는 장면. 이 이미지에서 GPT‑4o는 다음과 같은 세부 사항을 정확하게 반영했습니다:
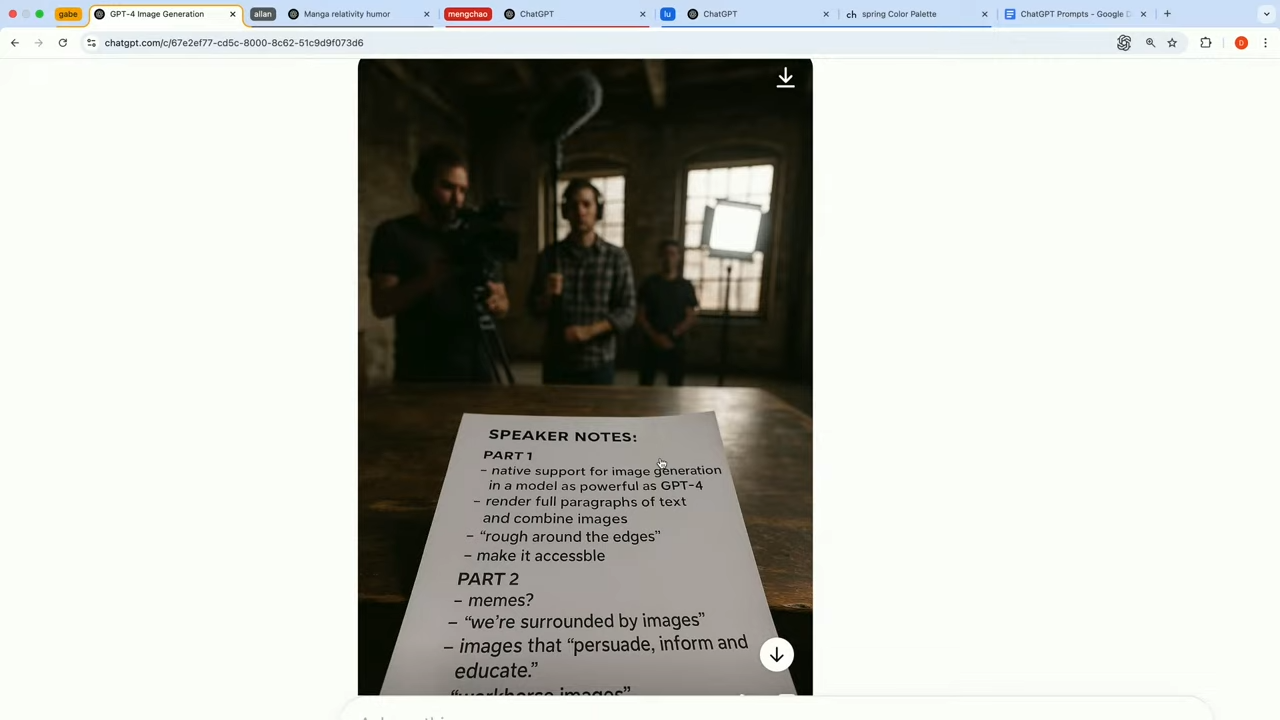
- 배경은 흐릿하게 처리되고 (depth-of-field 표현)
- 종이 위 텍스트는 정확히 렌더링됨
- "SPEAKER NOTES", "PART 1", "PART 2" 등 문구가 오탈자 없이 표현됨
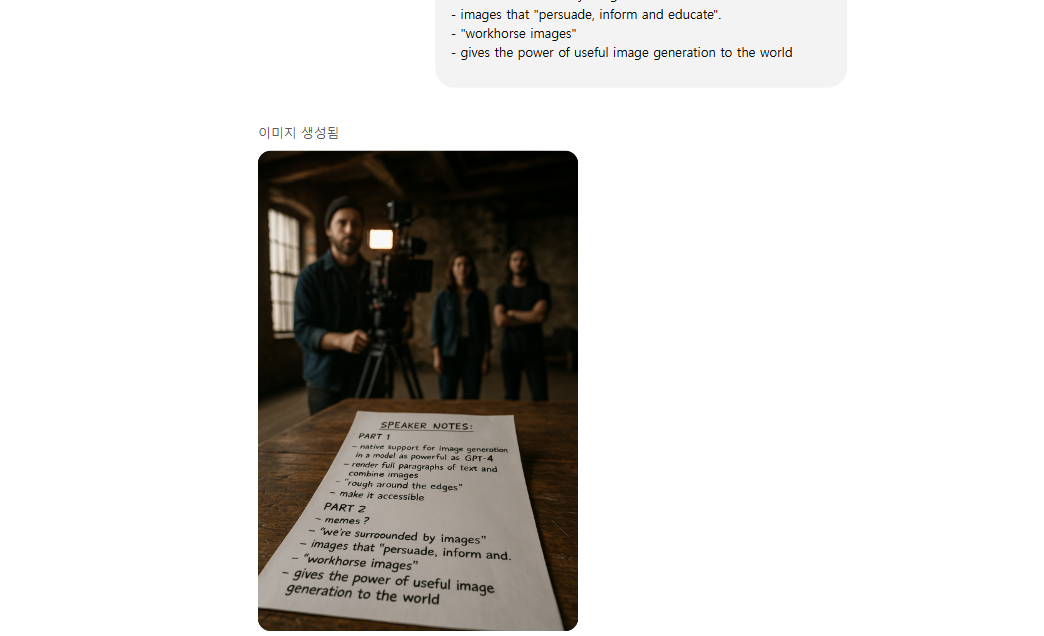
직접 만들어도 제대로 나오는 것을 볼 수 있음
📝 사용 프롬프트(ENG):
A tall, POV image of me in an old loft. Film crew present, facing me.
There is a sheet of paper on the table. There is text written on the paper (focus on paper, background out of focus. Paper occupies most of the page)
The text reads:
**SPEAKER NOTES:**
**PART 1**
- native support for image generation in a model as powerful as GPT-4
- render full paragraphs of text and combine images
- "rough around the edges"
- make it accessible
**PART 2**
- memes?
- "we're surrounded by images"
- images that "persuade, inform and educate".
- "workhorse images"
- gives the power of useful image generation to the world👓 프롬프트 특징 정리
이미지 생성 요청 프롬프트는 다음과 같은 3단 구성을 따릅니다:
-
장면 설정 (Scene Setting)
- 공간(낡은 로프트)과 시점(POV, 나의 시선)을 명확히 설정
- 인물 구성(촬영팀, 나를 바라보는 상태)
-
초점 대상 설정 (Focal Object)
- 이미지의 중심: 책상 위 종이
- "focus on paper", "background out of focus"는 Depth-of-Field(심도 표현)을 명시함
-
텍스트 삽입 지시 (Embedded Text Instruction)
- 종이에 적힌 내용을 그대로 명시 ("The text reads:" 이후의 문장들)
위 프롬프트를 직역해서 한글로 요청하면, 아직까지 한글은 완벽(?)하진 않은 것을 볼 수 있습니다.
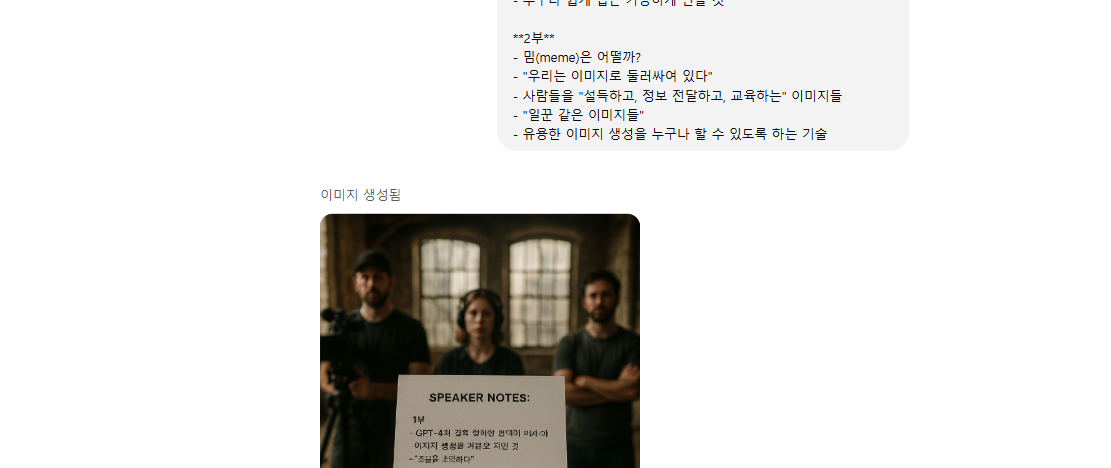
아래는 위 이미지를 만들기 위해 사용한 영문 프롬프트를 직역한 한글 프롬프트 내용입니다.
📝 사용 프롬프트(KOR):
낡은 로프트 안. 카메라 시점은 인물의 시점에서 바라보는 듯한 Tall, POV 이미지.
내 앞에 영화 촬영 팀이 있으며, 나를 바라보고 있다.
책상 위에 종이 한 장이 놓여 있고, 그 종이에 글이 적혀 있다.
**이미지의 초점은 종이에 맞춰져 있으며**, 배경은 흐릿하게 처리되어 있다.
종이가 이미지의 대부분을 차지한다.
종이에는 다음과 같은 내용이 적혀 있다:
**발표자 노트:**
**1부**
- GPT-4처럼 강력한 모델이 이미지 생성을 기본으로 지원
- 긴 문단의 텍스트를 렌더링하고 이미지를 결합
- "조금은 조악하다"
- 누구나 쉽게 접근 가능하게 만들 것
**2부**
- 밈(meme)은 어떨까?
- "우리는 이미지로 둘러싸여 있다"
- 사람들을 "설득하고, 정보 전달하고, 교육하는" 이미지들
- "일꾼 같은 이미지들"
- 유용한 이미지 생성을 누구나 할 수 있도록 하는 기술이 데모는 텍스트 포함 이미지의 정확도, 시점 표현, 배경 흐림 처리 등 복합적 조건을 자연스럽게 만족시킨 대표 사례였습니다.
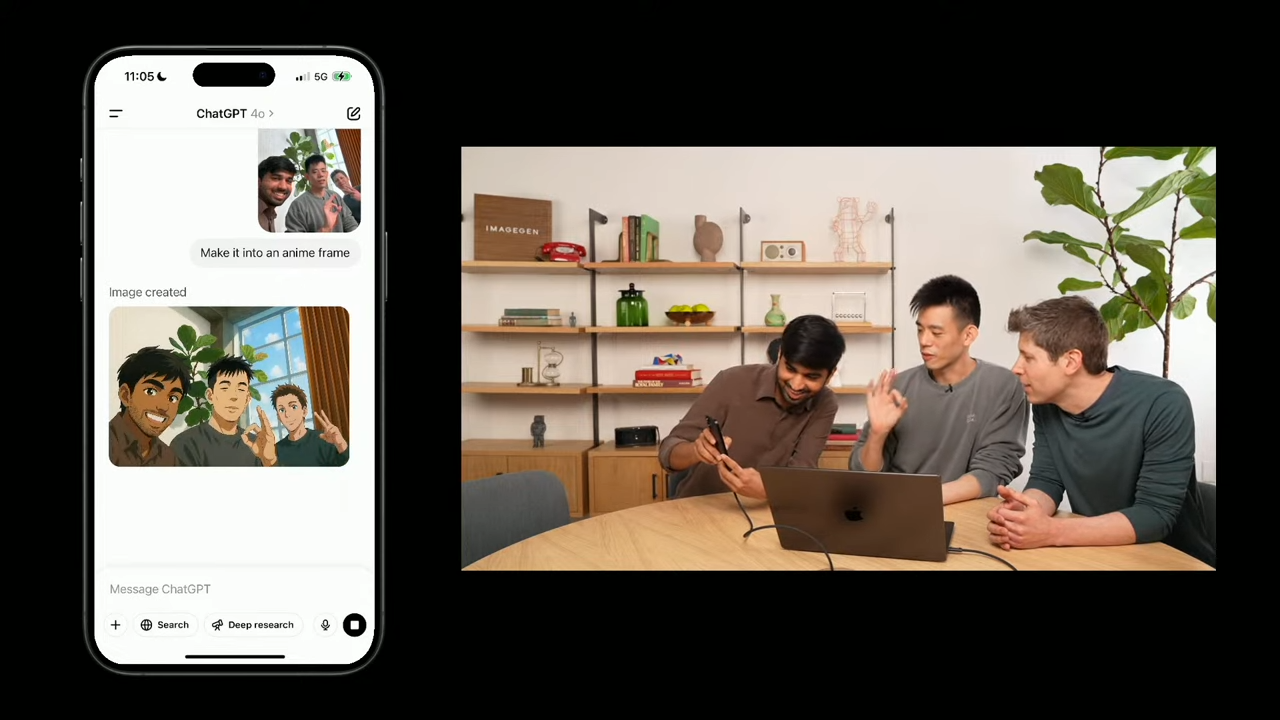
🎨 DEMO 2.1. 이미지 상호작용 - 직접 찍은 사진과 상호작용
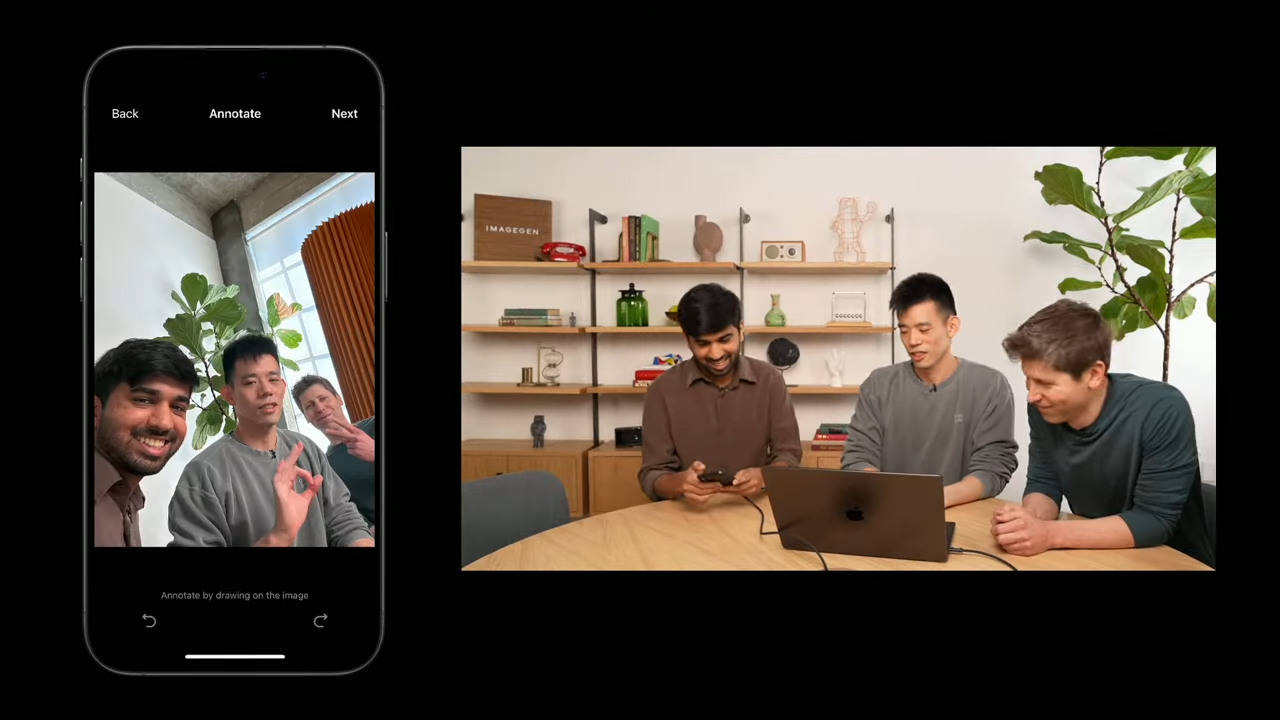
- 셀카를 찍어 업로드
- “anime frame으로 바꿔줘”라고 요청
- GPT‑4o는 얼굴, 손 모양, 표정, 배경 등을 그대로 유지한 채 anime 스타일로 변환한 이미지를 생성
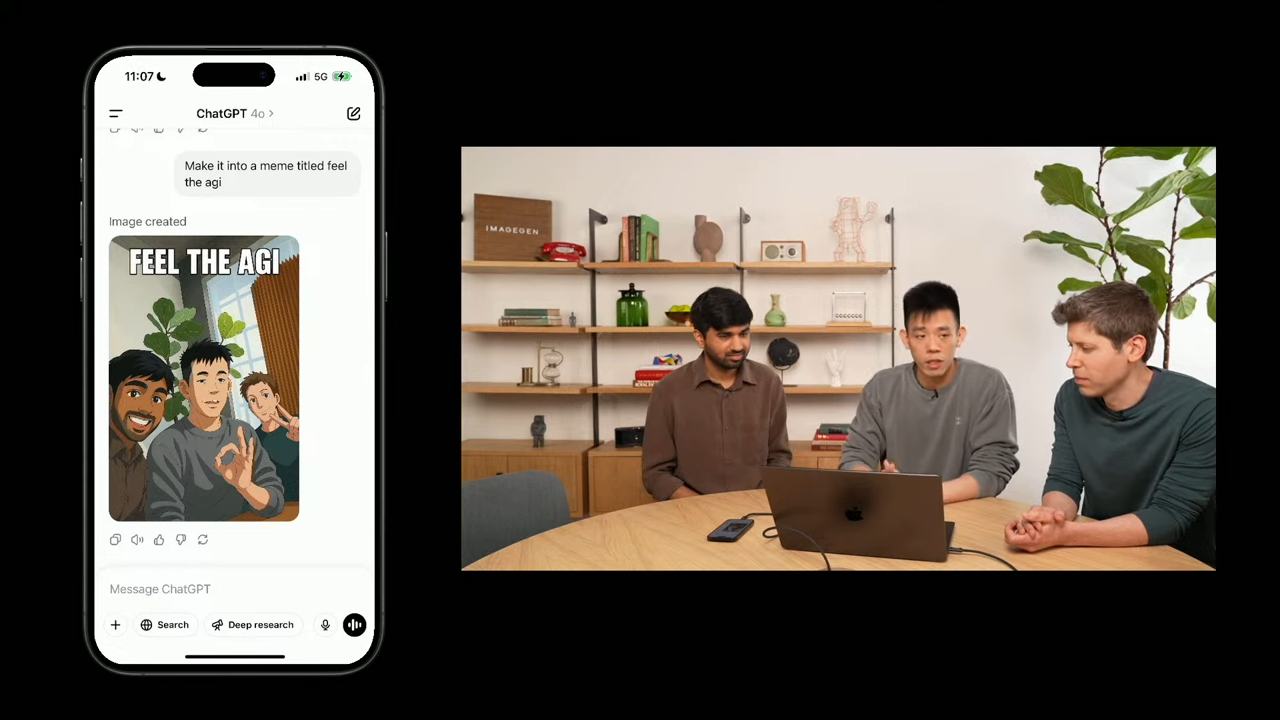
🖼️ DEMO 2.2. 밈(meme) 생성 – 좀 더 응용하기
이어지는 시연에서는, 셀카 → anime 변환 → meme 생성의 흐름으로 이어집니다.
💬 프롬프트 예시:
"이걸 밈으로 만들어줘. 문구는 ‘Feel the AGI’."
GPT‑4o는 이전 프롬프트와 이미지 컨텍스트를 유지한 채, 적절한 유머와 구성을 갖춘 밈 이미지를 생성했습니다.
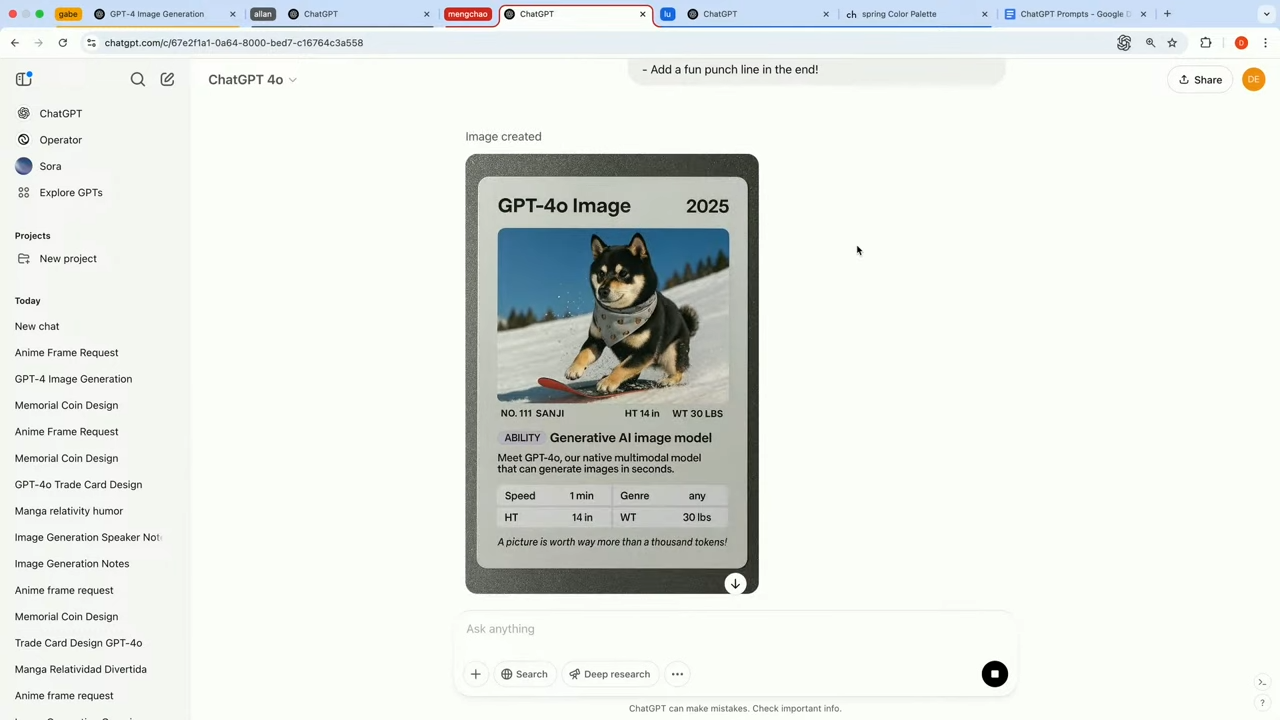
🃏 DEMO 3. 나만의 트레이딩 카드 만들기 & 개인 창작 도구로의 확장

이번 데모에서는 개발자가 “전문적인 디자이너가 만든 것 같은 트레이딩 카드”를 만들어 보는 시연을 수행합니다.
- 실제 카드 사진
- 자신의 강아지 Sanji 사진
- 카드에 들어갈 텍스트 정보 (이름, 능력치, 연도, 배경 설정 등)
📝 사용 프롬프트(ENG):
I want to make a trade card for our launch.
I've uploaded an example from the Sora launch, please design a trade card in the same style. The picture on the trade card should be a Shiba Inu snowboarding – please use my dog Sanji from the photo.
A couple details to note:
- Mention "GPT-4o Image" and "2025" in the headline as that's what we are launching today
- Use "Generative AI image model" as its ability. Be sure to mention "GPT-4o" and "native multimodal" in the description
- Sanji weighs "30 lbs", and is "14 inches" tall
- Include these stats on the card, and make them render in a 2x2 grid view
• "speed": "1 min"
• "genre": "any"
- Add a fun punch line in the end!📝 사용 프롬프트(KOR):
우리 런칭을 위한 **트레이딩 카드(trade card)**를 만들고 싶어.
Sora 런칭 때 사용된 예시 이미지를 업로드했으니, 동일한 스타일로 트레이딩 카드를 디자인해줘.
카드에 들어갈 이미지는 **스노보드를 타는 시바견(Shiba Inu)**이면 좋겠고,
내 강아지 **Sanji**의 사진을 활용해줘.
다음 세부 사항들을 꼭 반영해줘:
- 제목에는 **"GPT-4o Image"**와 **"2025"**라는 문구가 꼭 들어가야 해. 오늘 런칭되는 내용을 반영한 거니까.
- 능력(ability)으로는 **"Generative AI image model"**을 사용해줘.
설명에는 **"GPT-4o"**와 **"native multimodal"**이라는 표현을 꼭 넣어줘.
- Sanji는 **몸무게 30파운드(30 lbs)**, **키는 14인치(14 inches)**야.
- 다음 스탯(stat)들은 카드에 포함하고, **2x2 그리드 형태**로 보여줘:
• 속도(speed): "1분"
• 장르(genre): "any"
- 마지막엔 **재미있는 한 줄 문장(punch line)**도 추가해줘!
직접 만들어본 이쁜 Mint 카드 💌 (사진 그대로는 구현이 아직 부족한 느낌)
GPT‑4o는 사진 스타일을 모사하면서도, 지정된 텍스트와 숫자 데이터를 정확히 반영한 트레이딩 카드를 생성했습니다.
그래도 놀라운 점은 카드의 레이아웃, 정렬, 폰트 스타일, 작은 글씨까지 매우 정밀하게 표현되었다는 것입니다.
🪙 DEMO 4. 이미지 편집, 합성, 기념 코인 제작
마지막 세션에서는 GPT‑4o를 활용해 기념 코인(Memorial Coin)을 만드는 과정을 시연했습니다.
- 앞서 생성한 이미지 4장을 배경 요소로 활용
- Hex 색상 코드로 "봄 컬러 팔레트"를 적용
- 기념 문구와 날짜 삽입
- 이후 “투명 배경으로 만들어줘” 요청 → PNG로 생성
이 시연은 GPT‑4o가 단일 이미지 생성에 머무르지 않고, 멀티턴(Multi-turn) 상호작용을 통해 이미지 편집 및 반복적 커스터마이징까지 가능하다는 것을 보여주었습니다.
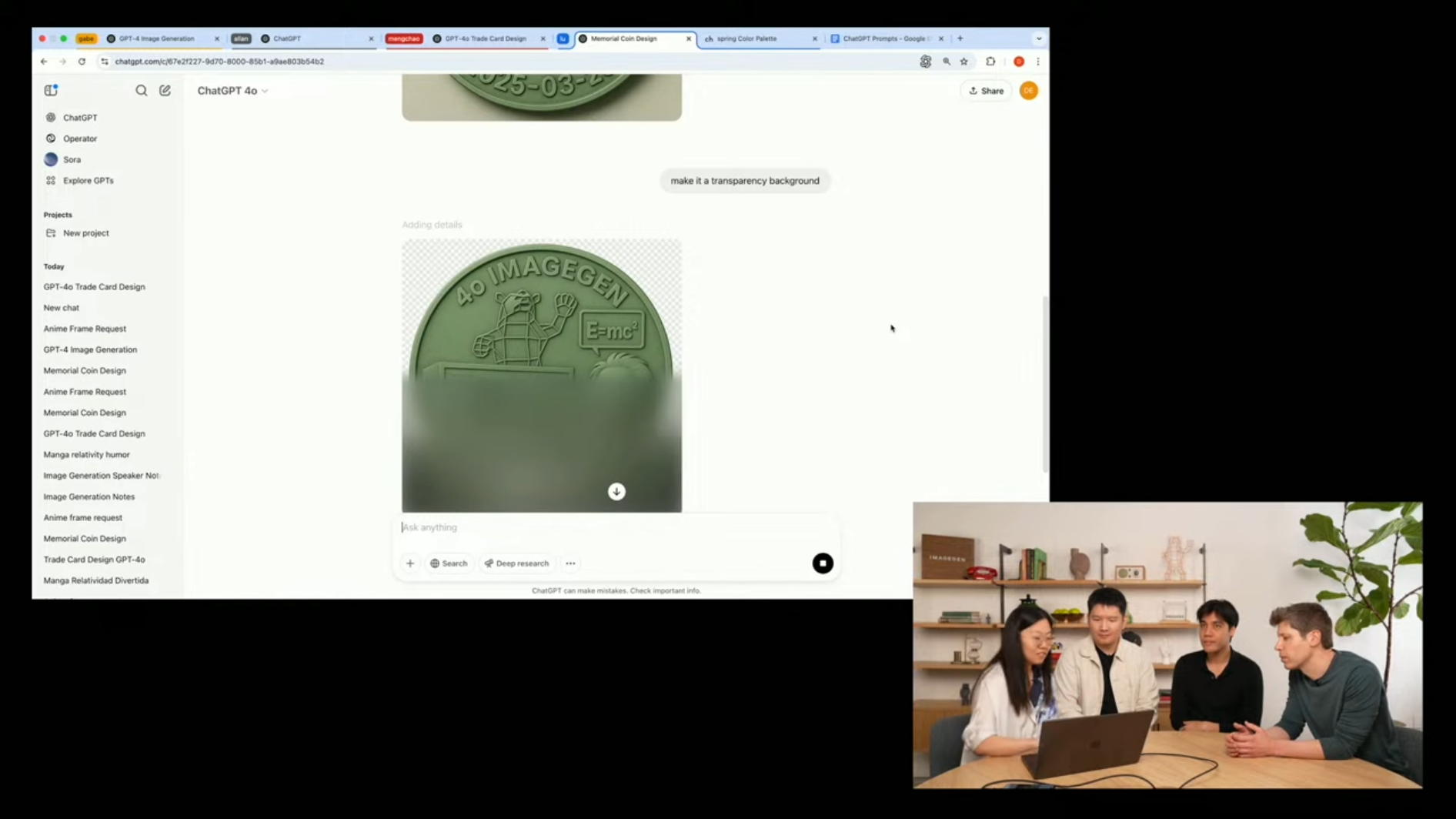
아래 질문들도 추가적으로 질의해서 이미지를 원하는 방향으로 업데이트해 볼 수도 있겠군요!!
- "뒷면 디자인도 만들어줘"
- "이름마다 색상 다르게 적용해줘"
- "이 부분만 수정해줘"
PART 2. OpenAI Blog 내용 소개
글의 맨 앞에서 얘기한 것처럼 이번 GPT-4o ImageGeneration 업데이트는 아래와 같습니다.
ℹ️ 신규 기능 요약
-
🧭 멀티턴 이미지 생성 (Multi-turn Generation)
-
📐 정밀한 인스트럭션 반영
-
🧠 인컨텍스트 학습 (In-context Learning)
-
🌍 월드 지식 연결 (World Knowledge)
-
✍️ 정확한 텍스트 렌더링 (Text Rendering)
-
🎭 다양한 스타일 & 포토리얼리즘
🔍 이번 챕터에서는 각각의 기능에 대해서 좀 더 살펴보도록 하겠습니다.
아래는 GPT-4o의 이미지 생성 기능을 6가지 핵심 기능별로 정리하고, 각 기능에 맞는 예시 Prompt를 자세하게 추가한 내용입니다. 실무 활용을 위한 프롬프트 작성에 유용하도록 구성하였습니다.
아래 예시들의 프롬프트와 이미지는 OpenAI Blog에 나온 공식 사례들입니다.
(조금씩 추가/변경한 내용도 존재합니다)
🧭 1. Multi-turn Generation (멀티턴 이미지 생성)
GPT-4o는 채팅 기반으로 이미지 생성 과정을 단계적으로 이어가며 점진적으로 정교화할 수 있습니다.
🔍 주요 기능
- 대화형 방식으로 이미지 수정 가능
- 일관성 유지 (캐릭터 스타일, 배경 요소, UI 등)
- 복잡한 장면 구성을 단계적으로 발전
🎨 예시 Prompt
CAT (Image)

→ Give this cat a detective hat and a monocle→ 기본 이미지에 탐정 모자와 단안경 추가

→ turn this into a triple A video games made with a 4k game engine and add some User interface as overlay from a mystery RPG where we can see a health bar and a minimap at the top as well as spells at the bottom with consistent and iconography→ AAA급 게임 스타일로 변환, UI 오버레이 추가
→ 게임 HUD, 일관된 아이콘, 해상도/스타일 업그레이드

→ update to a landscape image 16:9 ratio, add more spells in the UI, and unzoom the visual so that we see the cat in a third person view walking through a steampunk manhattan creating beautiful contrast and lighting like in the best triple A game, with cool-toned colors→ 화면 비율 변경(16:9), 시점 변경(3인칭), 배경 설정 추가
→ 스팀펑크 맨해튼 배경, 컬러톤 조절, 조명 효과 등 고급 조정
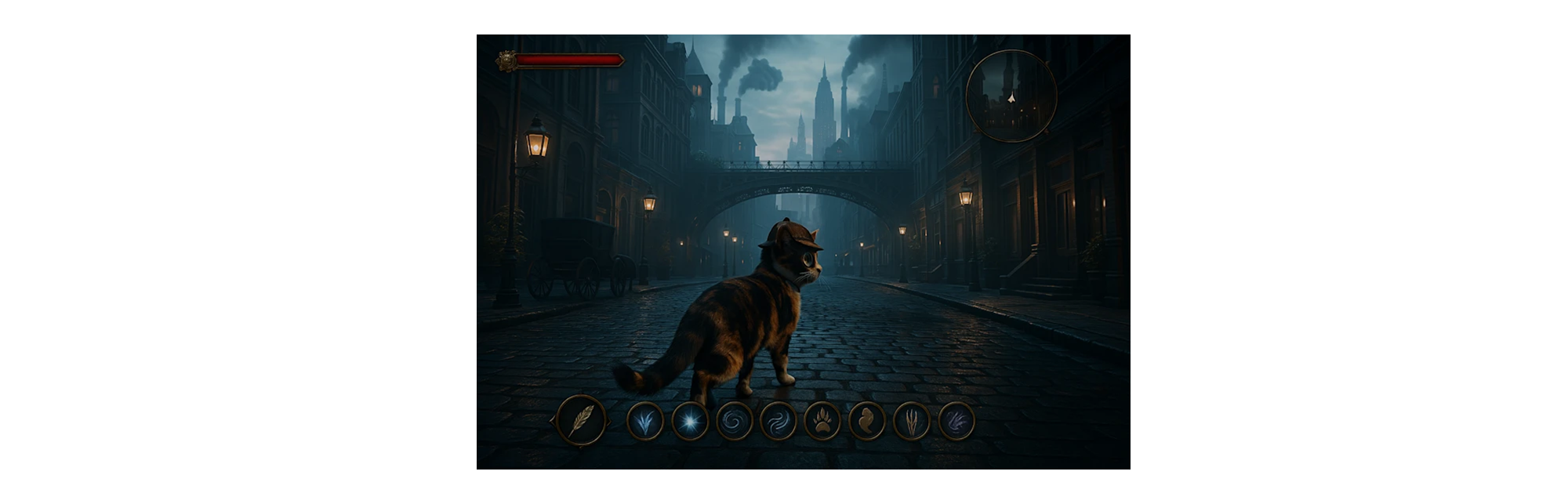
🧩 추가 예시
추가적으로 아래 프롬프트를 적용하여 고양이에게 베트맨 마스크를 씌워보았습니다.
→ turn this cat's detective hat and a monocle to batman mask.→ 의상 변경으로 새로운 캐릭터 스타일 생성

📋 2. Instruction Following (지시사항 기반 생성)
GPT-4o는 긴 prompt와 복잡한 객체 지시사항을 정확히 따릅니다.
(최대 10~20개의 객체도 처리 가능.)
📐 예시 Prompt
A square image containing a 4 row by 4 column grid containing 16 objects on a white background.
Go from left to right, top to bottom. Here's the list:
1. a blue star
2. red triangle
3. green square
4. pink circle
5. orange hourglass
6. purple infinity sign
7. black and white polka dot bowtie
8. tiedye "42"
9. an orange cat wearing a black baseball cap
10. a map with a treasure chest
11. a pair of googly eyes
12. a thumbs up emoji
13. a pair of scissors
14. a blue and white giraffe
15. the word "OpenAI" written in cursive
16. a rainbow-colored lightning bolt→ 4x4 정사각 격자, 좌→우, 상→하 순서, 각각의 속성이 정확히 반영됨

🧩 추가 예시
섬세한 요청 사항까지 수행해주는 GPT‑4o’s image generation.
show me a wine glass with only the tiniest drop of red wine in it.→ 매우 정밀한 디테일도 구현 가능.
→ "tiniest drop"이라는 수량적 표현도 시각화됨.

🧠 3. In-context Learning (컨텍스트 학습)
참조 이미지 기반으로 스타일, 구성, 아이디어를 학습해 새로운 이미지에 반영합니다.
🖼 예시 Prompt

Draw a design for a vehicle with triangular wheels using these images as references.
Label the front and back wheels, and at the bottom write:
“TRIANGLE WHEELED VEHICLE. English Patent. 2025. OPENAI.” (in small caps)→ 전송된 참조 이미지를 바탕으로 차량 형태 구성
→ “TRIANGLE WHEELED VEHICLE. English Patent. 2025. OPENAI.” 텍스트 포함
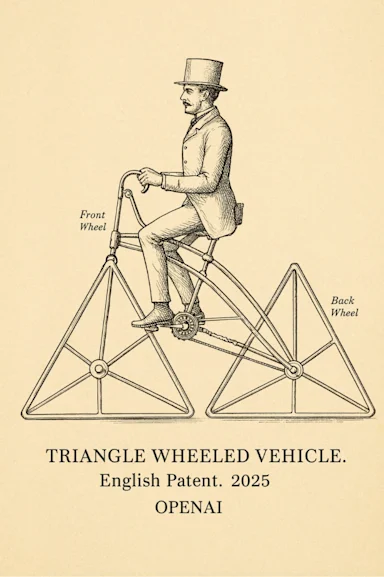
🧩 추가 예시
an photorealistic image of a blue chainsaw→ 단순 요청에도 포토리얼리즘을 기반으로 매우 세부적이고 사실적인 디테일 구현

🌐 4. World Knowledge Integration (세계 지식 연계)
GPT-4o는 텍스트 모델의 지식을 기반으로 이미지를 논리적으로 생성합니다.
🍹 예시 Prompt
Make me a professionally shot photorealistic diagram of the top selling cocktails in my bar with recipes labeled on each drink.
put the recipes on handwritten cards in front of each drink.
the cards are brown, and the text is black.
background is white
Title is "4 most popular cocktails"→ 칵테일 구성, 레시피, 사진 촬영 스타일 등을 통합한 이미지 생성
→ 손글씨 카드, 음료 위주 배열, 배경 등 복합 조건 만족

🧩 추가 예시
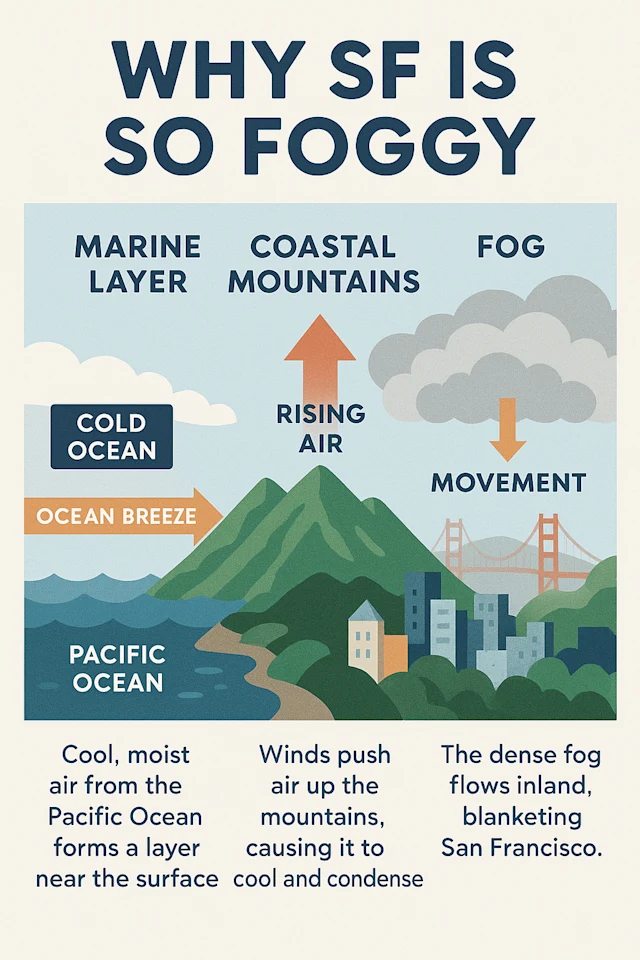
make a visual infographic describing why SF is so foggy→ 지역 기반 기후 지식과 시각 자료화까지 진행 (Fog = 해양성 기후, 지형 영향 등 시각화)
🖼 5. Photorealism & Style Transfer (포토리얼리즘 및 스타일 변환)
다양한 스타일에 대한 학습을 통해 사실적이거나 예술적인 이미지 생성이 가능
👨🏫 예시 Prompt
A wide image taken with a phone of a glass whiteboard, in a room overlooking the Bay Bridge. The field of view shows a woman writing, sporting a tshirt wiith a large OpenAI logo. The handwriting looks natural and a bit messy, and we see the photographer's reflection.
The text reads:
(left)
"Transfer between Modalities:
Suppose we directly model
p(text, pixels, sound) [equation]
with one big autoregressive transformer.
Pros:
* image generation augmented with vast world knowledge
* next-level text rendering
* native in-context learning
* unified post-training stack
Cons:
* varying bit-rate across modalities
* compute not adaptive"
(Right)
"Fixes:
* model compressed representations
* compose autoregressive prior with a powerful decoder"
On the bottom right of the board, she draws a diagram:
"tokens -> [transformer] -> [diffusion] -> pixels"→ 특정 촬영 각도, 손글씨의 자연스러움, 배경 창문/반사 효과까지 정밀 재현

🧩 추가 예시
A cat looking into a puddle of water on a street.
The reflection is that of a tiger, realistically distorted by ripples in the water.→ 메타포적 표현까지 정교하게 구현
→ 물결 반사 효과까지 포토리얼하게 묘사

📐 6. Text Rendering (텍스트 렌더링 정확도)
이미지 내 텍스트 렌더링 품질이 탁월하며, 표지판, 메뉴판, 초대장 등 실사용 가능
🧾 예시 Prompt
Create a photorealistic image of two witches in their 20s (one ash balayage, one with long wavy auburn hair) reading a street sign.
Context:
a city street in a random street in Williamsburg, NY with a pole covered entirely by numerous detailed street signs (e.g., street sweeping hours, parking permits required, vehicle classifications, towing rules), including few ridiculous signs at the middle: (paraphrase it to make these legitimate street signs)"Broom Parking for Witches Not Permitted in Zone C" and "Magic Carpet Loading and Unloading Only (15-Minute Limit)" and "Reindeer Parking by Permit Only (Dec 24–25)\n Violators will be placed on Naughty List." The signpost is on the right of a street. Do not repeat signs. Signs must be realistic.
Characters:
one witch is holding a broom and the other has a rolled-up magic carpet. They are in the foreground, back slightly turned towards the camera and head slightly tilted as they scrutinize the signs.
Composition from background to foreground:
streets + parked cars + buildings -> street sign -> witches. Characters must be closest to the camera taking the shot→ 복잡한 간판 구성 및 실제 텍스트 렌더링 완벽 반영
→ "Broom Parking for Witches..." 같은 유머 요소까지 현실적 표지판 형식으로 표현

🧩 추가 예시
I'm opening a traditional concept restaurant in Marin called Haein. It focuses on Korean food cooked with organic, farm-fresh ingredients, with a rotating menu based on what's seasonal. I want you to design an image - a menu incorporating the following menu items - lean into the traditional/rustic style while keeping it feeling upscale and sleek. Please also include illustrations of each dish in an elegant, peter rabbit style. Make sure all the text is rendered correctly, with a white background.
(Top)
Doenjang Jjigae (Fermented Soybean Stew) – $18 House-made doenjang with local mushrooms, tofu, and seasonal vegetables served with rice.
Galbi Jjim (Braised Short Ribs) – $34 Slow-braised local grass-fed beef ribs with pear and black garlic glaze, seasonal root vegetables, and jujube.
Grilled Seasonal Fish – Market Price ($22-$30) Whole or fillet of local, sustainable fish grilled over charcoal, served with perilla leaf ssam and house-made sauces.
Bibimbap – $19 Heirloom rice with a rotating selection of farm-fresh vegetables, house-fermented gochujang, and pasture-raised egg.
Bossam (Heritage Pork Wraps) – $28 Slow-cooked pork belly with napa cabbage wraps, oyster kimchi, perilla, and seasonal condiments.
(Bottom) Dessert & Drinks Seasonal Makgeolli (Rice Wine) – $12/glass
Rotating flavors based on seasonal fruits and flowers (persimmon, citrus, elderflower, etc.).
Hoddeok (Korean Sweet Pancake) – $9 Pan-fried cinnamon-stuffed pancake with black sesame ice cream.→ 고급 전통 스타일의 한식 메뉴판 시각화
→ Peter Rabbit 스타일 일러스트 포함, 텍스트 오타 없음

마무리
이번 GPT-4o 업데이트를 통해 우리는 이미지 생성에서도 단순한 생성을 넘어, 프롬프트를 통한 세밀한 컨트롤과 다단계 정교화, 그리고 지식 기반 생성까지 폭넓은 가능성을 확인할 수 있었습니다.
프롬프트 하나에도 세심하게 의도를 담는다면, 훨씬 더 고급스럽고 창의적인 이미지를 만들어낼 수 있음을 보여주는 인상적인 사례들이었습니다.
OpenAI의 CEO 샘 알트만은 이번 업데이트가 속도는 다소 느려졌지만, 그만큼 정밀도와 표현력 면에서는 큰 진보가 있었다고 강조했습니다. 성능 최적화는 점차 개선될 예정이니 앞으로의 업데이트도 기대해볼 만합니다.
한편, 지브리 스타일 등 저작권과 이미지 스타일 사용에 대한 이슈도 점차 대두되고 있는데요, OpenAI와 창작자 간의 윤리적이고 법적인 조율 방향도 중요한 관전 포인트가 될 것입니다.
💬 여러분은 어떤 이미지를 만들어보고 싶으신가요?
🎨 프롬프트에 어떤 상상을 담아보셨나요?
직접 실험해보고, 나만의 작품을 만들어보는 것도 큰 재미입니다.
재미있는 시도나 결과물이 있다면 댓글이나 링크로 함께 공유해주세요! 🎨
오늘도 읽어주셔서 감사합니다!😊
