
학습 목표
딥러닝 & AutoML 학습 조건 및 결과 DB 적재 및 관리를 위한 지식 함양
실행 환경
운영체제 : 윈도우 10
개인 노트북에 로컬 서버 구축
설치 프로그램
MSSQL , SSMS 설치
설치는 다음 블로그를 참고해주세요~
계정 생성 및 권한 부여 (필수)
MSSQL 서버에 접속하기 위한 계정 생성 및 접속 권한을 부여합니다.
https://kinanadel.blogspot.com/2019/07/mssql-microsoft-sql-server_12.html
ODBC Driver 버전 확인
윈도우 '찾기'에서 ODBC를 검색하면 ODBC 데이터 원본이 나옵니다.
만약 없다면 아래 링크를 통해 설치하면 됩니다.

드라이버 - ODBC Driver 17 for SQL Server 확인
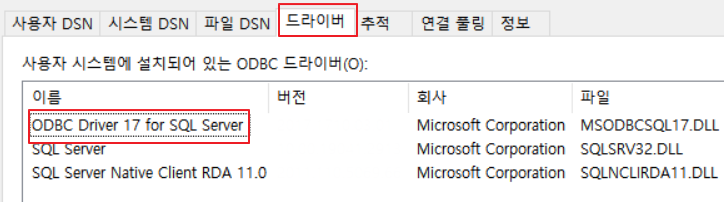
현재 제가 사용하는 PC는 17 버전을 사용하고 있었습니다. 이는 파이썬 코드에서 서버 접속 시 반드시 필요하므로 꼭 알아야합니다.
pyodbc 라이브러리
pyodbc는 Python에서 MS SQL Server 데이터베이스와 연결하여 데이터를 다루기 위한 라이브러리. pyodbc 라이브러리를 이용하면 Python에서 SQL Server 데이터베이스에 연결하여 쿼리를 실행하고, 데이터를 저장하고, 수정하고, 삭제하는 등의 작업을 수행할 수 있다.
이 라이브러리를 이용하면 다양한 연산을 수행할 수 있습니다.
pip install pyodbcMSSQL Server 연결
import pyodbc
server = '' #접속할 서버명
database = '' #접속할 데이터베이스
username = '' # 접속 계정
password = '' # 계정 비밀번호
driver = '{ODBC Driver 17 for SQL Server}' # 드라이버는 사용자의 환경에 맞게 설정
# Connection string 생성
connection_string = f"DRIVER={driver};SERVER={server};DATABASE={database};UID={username};PWD={password}"
# Connection 생성
connection = pyodbc.connect(connection_string)
# Cursor 생성
cursor = connection.cursor()
print("연결완료")SQL Server 연결을 위해선 다섯가지 문자열 변수가 필요합니다.
DRIVER : ODBC에 나타난 문자열 그대로 입력,
SERVER : SQL Server 개체탐색기 상단에 위치한 서버 주소 로컬이라면 localhost 사용(외부 서버라면 xx.xx.xx.xx과 같은 ip 형태)
DATABASE : 접속할 데이터베이스 이름
UID : SQL Server ID
PWD : SQL Server PW
테이블 생성
# 테이블 생성 쿼리문
create_table_query = """
CREATE TABLE hello (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
gender VARCHAR(10)
);
"""
# 쿼리문 실행
cursor.execute(create_table_query)
# 커밋
connection.commit()
# 커넥션 닫기
connection.close()연결에서 정의했던 'cursor' 변수를 사용해서 execute 메소드를 사용해 SQL 쿼리문을 실행합니다.

MSSQL Server 실행해서 조회를 해보면 test라는 테이블이 생성되었고, 컬럼이 정상적으로 생성된 것을 확인할 수 있습니다.
데이터 저장
이제 딥러닝 하이퍼 파라미터를 저장해보기 위해
epoch, learning rate, batch size, window size와 같은 옵션들을 저장할 수 있는 테이블을 만든 후 아래 코드를 통해 저장할 수 있습니다.
# 데이터 저장 SQL 쿼리
insert_query = "INSERT INTO test_table \
(epoch, lr,batch_size,window_size) \
VALUES (?, ?, ?, ?)"
# 데이터 저장할 값
data = (100, 0.001,4,12)
# 데이터 저장
cursor.execute(insert_query, data)
# 커밋
connection.commit()
# 커넥션 닫기
connection.close()파이썬 변수로 저장된 값을 DB 테이블에 저장하기 위한 코드입니다.
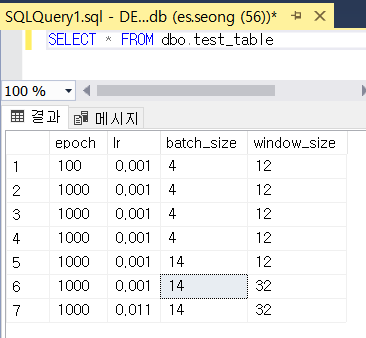
insert_query = "INSERT INTO test_table \
(epoch, lr,batch_size,window_size) \
VALUES (?, ?, ?, ?)"해당 코드가 데이터 저장을 위한 쿼리문입니다. VALUES을 보면 테이블의 컬럼 수 와 ? 개수를 꼭 맞춰줘야 합니다.
데이터 프레임 값 저장
# 데이터프레임 생성
data = pd.DataFrame({'epoch': [50],
'lr': [0.0001],
'batch_size': [32],
'window_size': [10]
})
# 데이터 저장
for row in data.itertuples(index=False):
cursor.execute(insert_query, row)파이썬으로 데이터를 다루게되면 사용하는 것이 pandas 라이브러리입니다. pandas에서 주로 pd.DataFrame 형태로 저장되는데 이를 DB테이블로 저장하기 위해서는 itertuples라는 메소드를 사용해서 각 행에 저장된 데이터를 반복문을 통해 저장합니다.
데이터 조회
SQL Server에 저장했다면, 저장한 값을 다시 작업환경으로 저장할 수도 있어야합니다.
# 쿼리문 작성
select_query = "SELECT * FROM test_table"
# 데이터 조회
data = pd.read_sql(select_query, connection)
# 커넥션 닫기
connection.close()
# 데이터프레임 출력
print(data)test_table 테이블의 모든 값을 조회하는 쿼리문 문자열을 생성 후 pd.read_sql을 통해 쿼리문을 실행시킵니다.
실행결과의 데이터 타입은 pd.DataFrame으로 저장됩니다.
데이터 업데이트
# 데이터 업데이트 SQL 쿼리
update_query = "UPDATE test_table \
SET epoch = ?, lr = ?, batch_size = ?, window_size = ? \
WHERE epoch = ?"
# 첫 번째 행 업데이트
cursor.execute(update_query, (4, 0.0005, 256, 40, 100))
# 커밋
connection.commit()
# 커넥션 닫기
connection.close()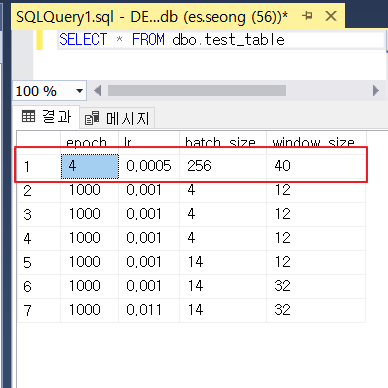
쿼리문을 해석하면 epoch가 100인 행의 데이터를 수정하는 명령입니다.
테이블의 첫번째 행의 epoch열이 100이 저장되어 있었는데 코드의 값으로 수정된 것을 확인할 수 있습니다.
데이터 삭제
# 데이터 삭제 SQL 쿼리
delete_query = "DELETE FROM test_table WHERE epoch = ?"
# 데이터 삭제
cursor.execute(delete_query, (4))
# 커밋
connection.commit()
# 커넥션 닫기
connection.close()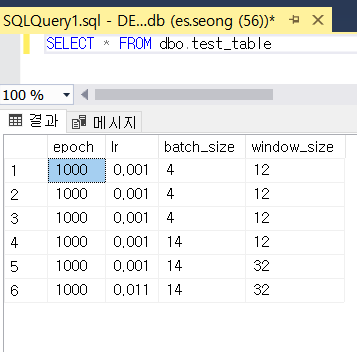
이제 아까 UPDATE를 진행했던 행을 삭제하였습니다.
WHERE 절을 통해 epoch가 4인 행이 삭제된 것을 확인할 수 있습니다.
현재 생성된 테이블 조회
# 현재 연결된 데이터베이스의 모든 테이블명 조회 쿼리
query = "SELECT name FROM sys.tables;"
# 쿼리 실행
cursor.execute(query)
# 결과 출력
tables = cursor.fetchall()
print(tables)현재 접속한 데이터베이스에 어떤 테이블이 존재하는지 조회하기위한 코드입니다.

제가 테스트를 위해 데이터베이스에 생성했던 테이블의 이름을 확인할 수 있습니다.
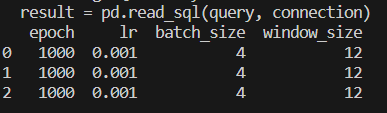
특정 조건 필터링
# 특정 조건에 맞는 데이터만 필터링하는 쿼리
query = "SELECT * FROM test_table WHERE batch_size = 4"
result = pd.read_sql(query, connection)
# 데이터베이스 연결 해제
connection.close()
# 결과 확인
print(result)배치사이즈가 4인 값만 필터링을 하기 위해 WHERE절이 들어간 쿼리문을 사용했습니다.
pd.read_sql을 통해 쿼리문을 실행하면 다음과 같이 배치사이즈가 4인 행만 출력됩니다.
주의사항
DB에 연결 후 사용이 끝난다면 반드시 commit()과 close()를 통해 연결을 종료시켜주어야 합니다.
close를 시켜주지 않으면 다른 py파일에서 DB 연결이 안되는 경우가 있었습니다ㅠㅠ
# 커밋
connection.commit()
# 커넥션 닫기
connection.close()이걸 노션에 적어뒀을 땐 mlflow의 엄청남을 몰랐던 시절이라... 하이퍼파라미터 자동 저장해주는 MLOps 최고...!
