본 포스팅은 카이스트 산업및시스템공학과 문일철 교수님의 Introduction to Artificial Intelligence/Machine Learning(https://aai.kaist.ac.kr/xe2/courses) 강의에 대한 학습 정리입니다.
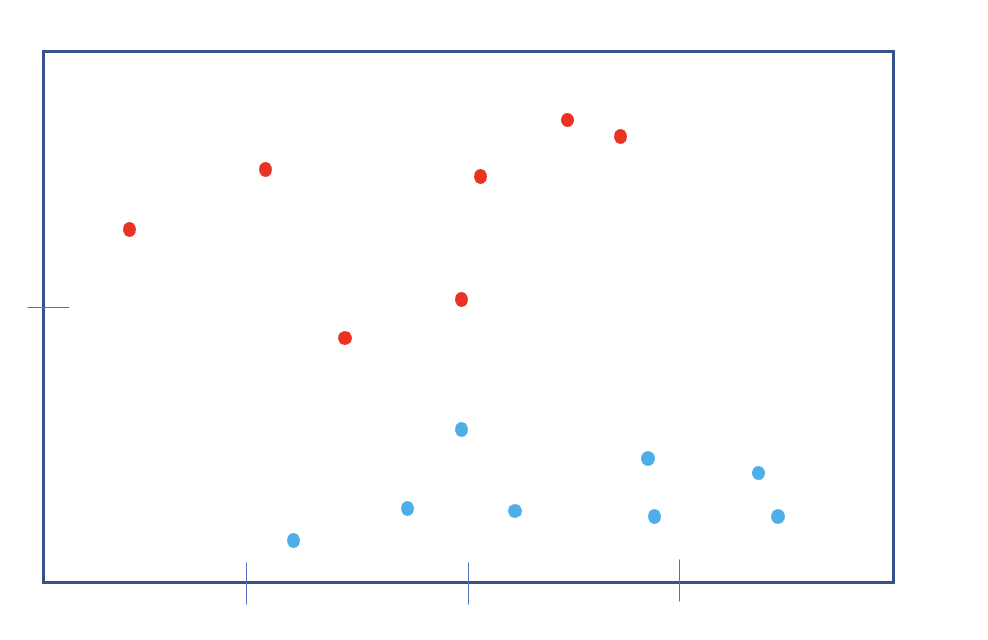
위와 같이 확률 및 통계적인 부분을 제외하고 데이터들을 보았을때, Decision Boundary를 어떻게 잡으면 좋을지 생각하게 된다.
일단 선형만 생각해도 다양한 선이 데이터를 두 집단으로 나눌 수 있을 것인데,
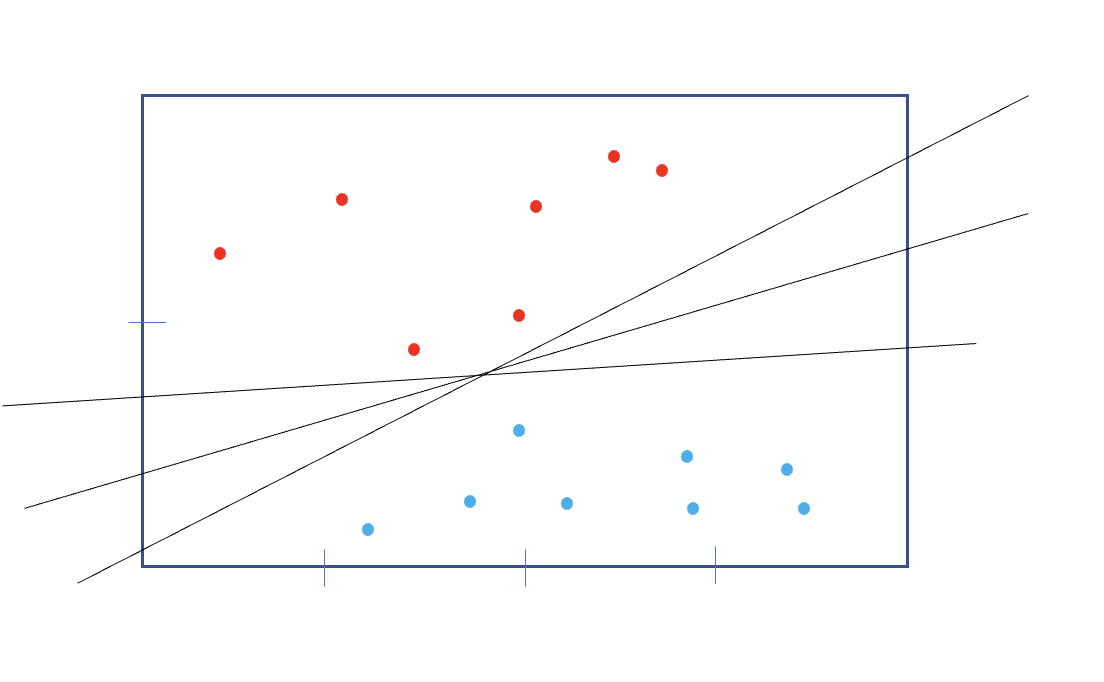
이 세개의 선중에 가장 안전하게 나누는 것은 당연히 가운데라고 할것이다.
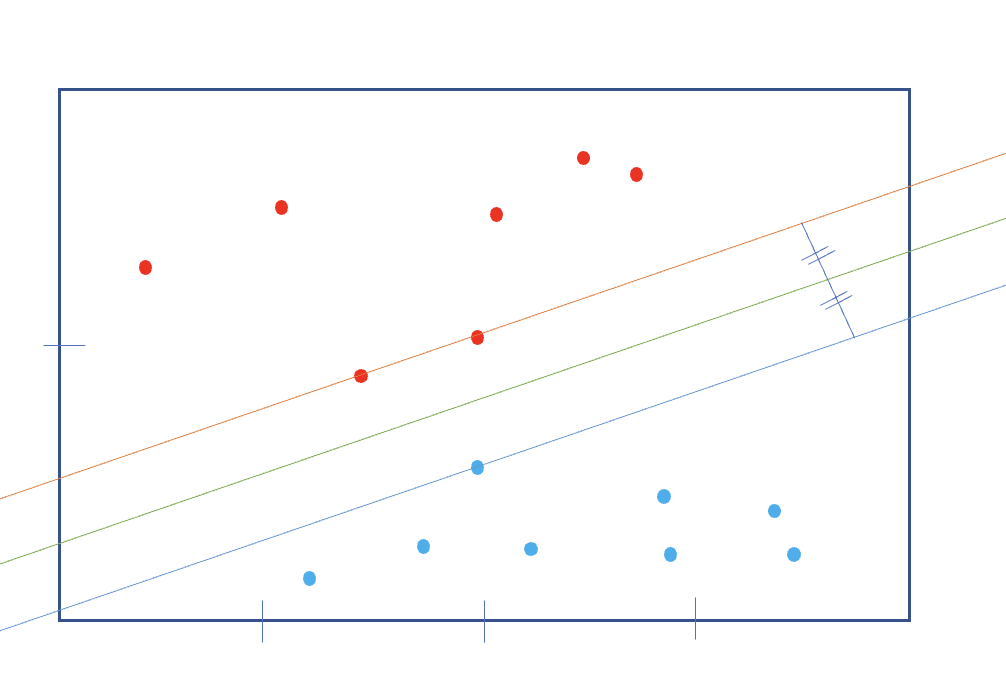
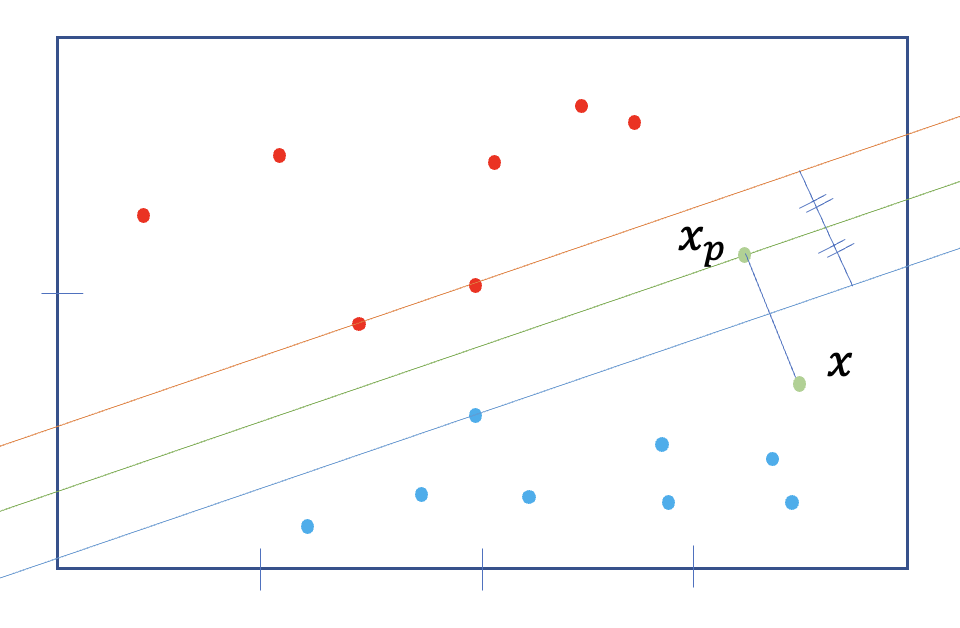
그럼 조금 더 신중하게 가운데 찾으려고, 빨강 점 두개를 지나는 선 하나와, 그 선과 평행하며 가장 가까운 파란 선을 만들어주고, 그 두 선과의 거리같은 평행한 선(decision boundary)을 만들 수 있다.
반대로 생각하면 이 선을 찾으려고 제일 처음의 두점, 즉 벡터들이 존재한다. 따라서 이 방법은 support vector machine 이라고 한다.
Support Vector Machine
- 위 경우에서, Decision Boundary:
- positive case:
- negative case:
- confidence level: - 항상 양수, 최대한 높여주는 것이 목적
- Margin: decision boundary와 그와 가장 근접하게 만들어지는 선(두 점)과의 거리
Margin Distance
- 특정 x가 선위에 있다면,
- positive point x,
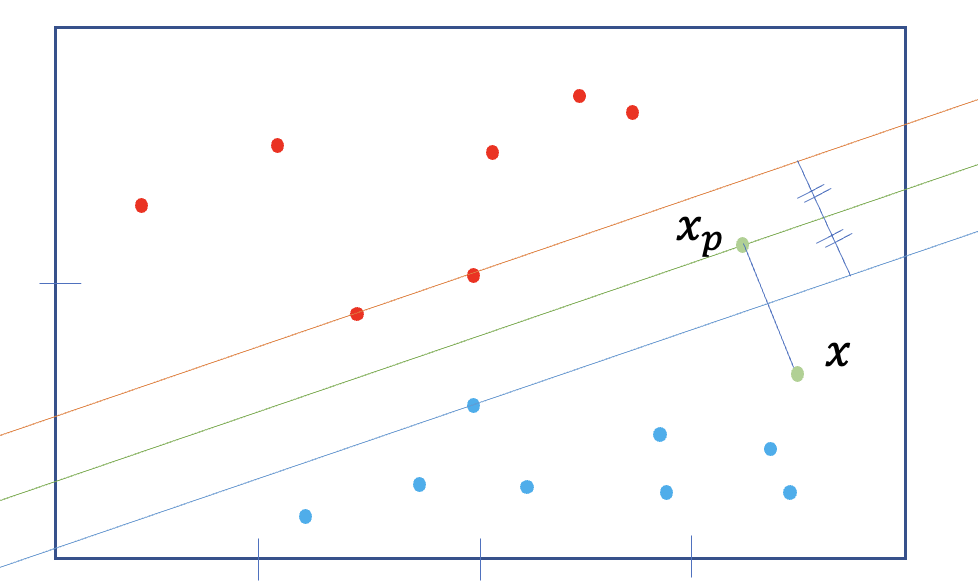
- 임의의 점 와 수선의 발, 두 사이의 거리
- Margin distance:
Maximizing the Margin
- 좋은 decision boundary => maximum margin
- 두 방향 모두 고려해야한다.
- , 조건:
- 역수로 만들어버리고 a=1(두점으로 만들어진 경계상에 있을때)이면. ,조건:
- 따라서 이 문제는 quadratic optimization.
그러나, 위 방법으로 갑자기 빨간점이 파란점들보다 아래에 있다면(error case), 선형적으로 decision boundary를 만들 수 없고 현실에는 그런 경우가 많다 => support vector machine with Hard margin(infeasible) 또는 에러를 어느정도 받아주는 방법.
Error Handling
두 점으로 만들어진 경계를 넘어서 decision boundary와 가까워 지면서 loss가 생겨난다.
- 방법1: 에러 횟수에 따라서 패널티를 주는 방식
- ,조건:
- loss: 0-1
- 단점: 모든 경우를 같은 크기의 loss로 생각하는것은 문제가 될 수 있음
- 방법2: slack variable(mis-classification되었을때의 그 정도)을 도입 => Soft Margin SVM
- ,조건:
- Hinge loss
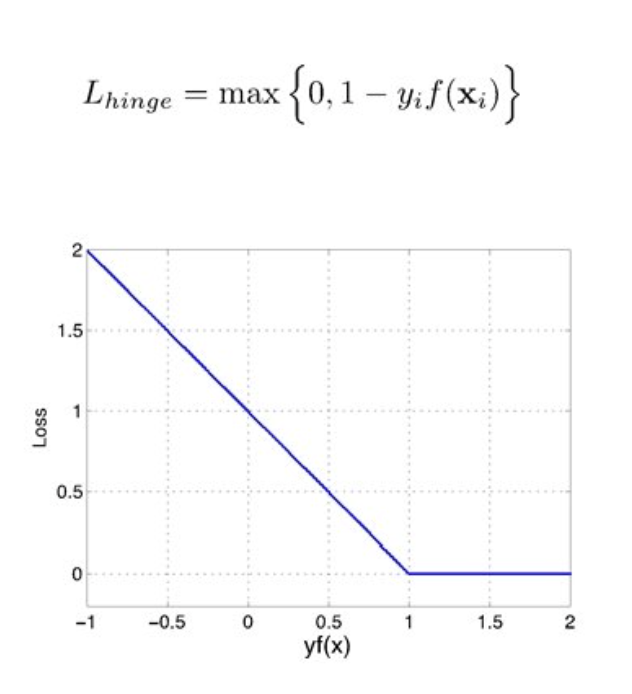
- 단점: trade-off parameter C를 정해줘야한다. C가 너무 작으면 패널티가 너무 작아져 버려 decision boundary가 무의미해지고, 너무 크면 decision boundary가 고정되긴 해도, 데이터를 과신하게 되는 경우가 잇다.
Soft Margin SVM
- ,조건:
- Logistic Regression과의 비교
- logistic regression의 loss: log loss
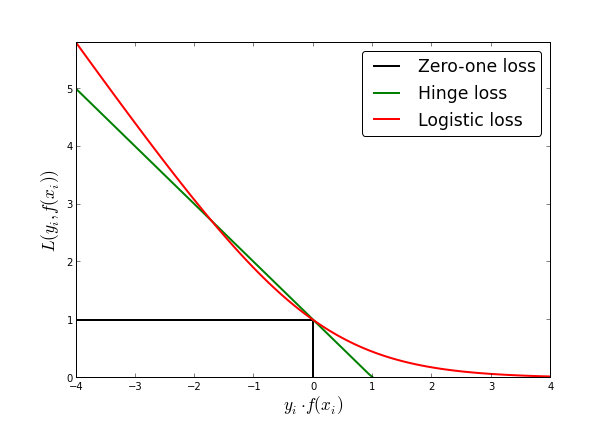
- 안전해도 패널티를 주는 것을 볼 수 있다.(맞아도 틀릴 수 도 있다는 가능성의 여지를 준다)
- logistic regression의 loss: log loss
- 역시, 이 경우에도 어떤 loss가 좋다고 확정할 수 없다. 문제정의에 따라 선택

그러나 먼저 된 자로서 나중되고 나중 된 자로서 먼저될 자가 많으니라(마:19:30)