본 포스팅은 카이스트 산업및시스템공학과 문일철 교수님의 Introduction to Artificial Intelligence/Machine Learning(https://aai.kaist.ac.kr/xe2/courses) 강의에 대한 학습 정리입니다.
Finding θ with Gradient Discent
-
θ^=argmaxθ∑1≤i≤Nlog(P(Yi∣Xi;θ))
-
f(θ)=∑1≤i≤Nlog(P(Yi∣Xi;θ))
-
∂θj∂f(θ)=∂θj∂{∑1≤i≤Nlog(P(Yi∣Xi;θ))}=∑1≤i≤NXi,j(Yi−P(y=1∣x;θ))
-
Gradient method를 사용하려면
- f′(x)를 위와 같이 알아야한다.
- case of ascent: xt+1←xt+hu′=xt+hf′(xt)f′(xt)
- 그리고, θ를 계속적으로 update
- θjt+1←θjt+h{∑1≤i≤Nlog(P(Yi∣Xi;θ))}
=θjt+ch{∑1≤i≤NXi,j(Yi−1+eXiθteXiθt)},
- θj0은 임의적으로 골라져야한다.
-
따라서, Gradient Discent는 Linear Regression의 "feature가 많고 matrix multiplication으로부터의 문제를 해결한다."
Naive Bayes 와 Logistic Regression
Gaussian Naive Bayes
- 나이브 베이즈에 categorical이 아닌 continuous하다는 조건을 가질 수 있도록 Gaussian distribution의 특징을 더해준다.
- P(Y)∏1≤i≤dP(Xi∣Y)=πk∏1≤i≤dσkiC1exp(−21(σkiXi−μki)2)
- Naive Bayes assumption에서,
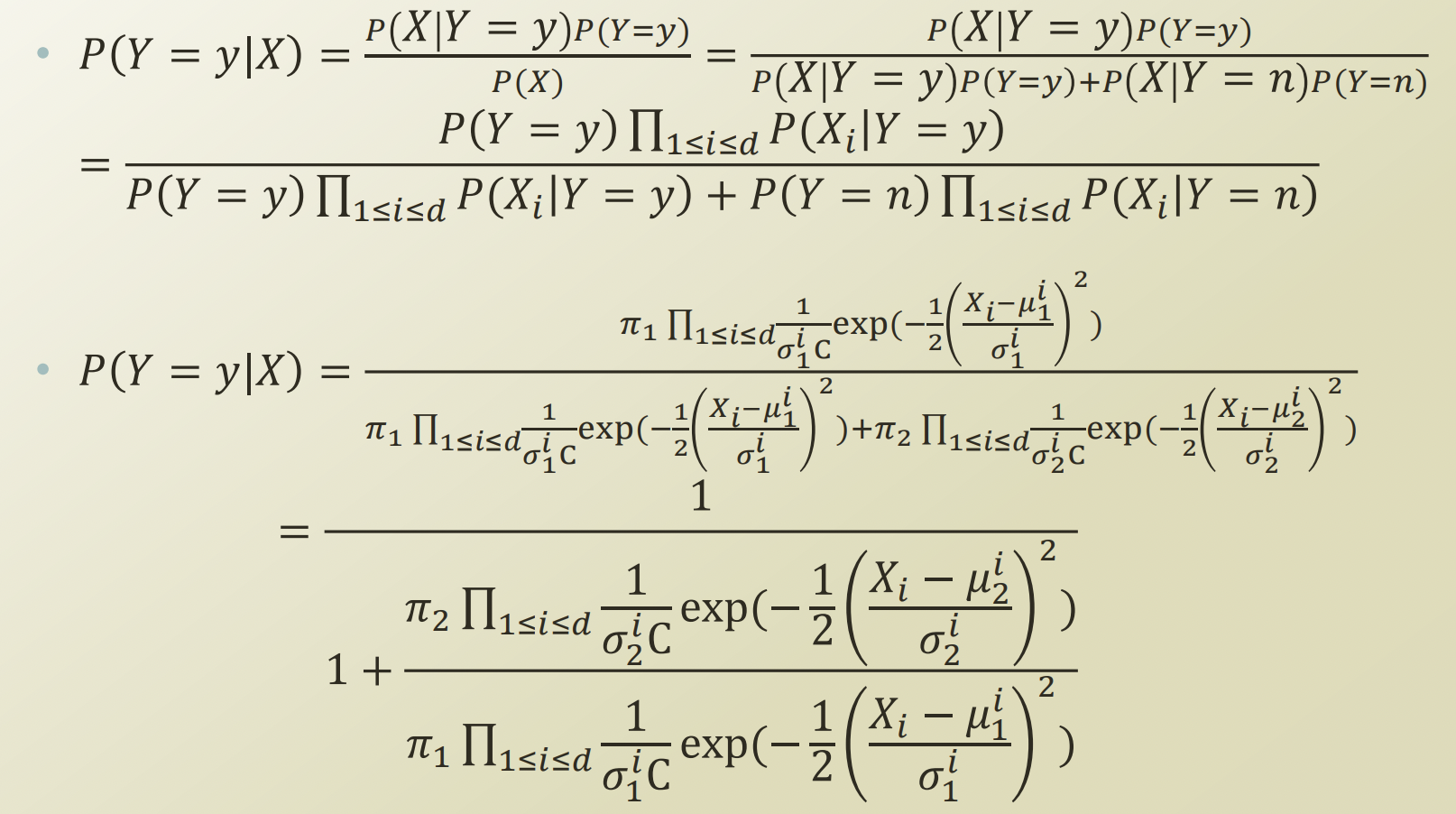
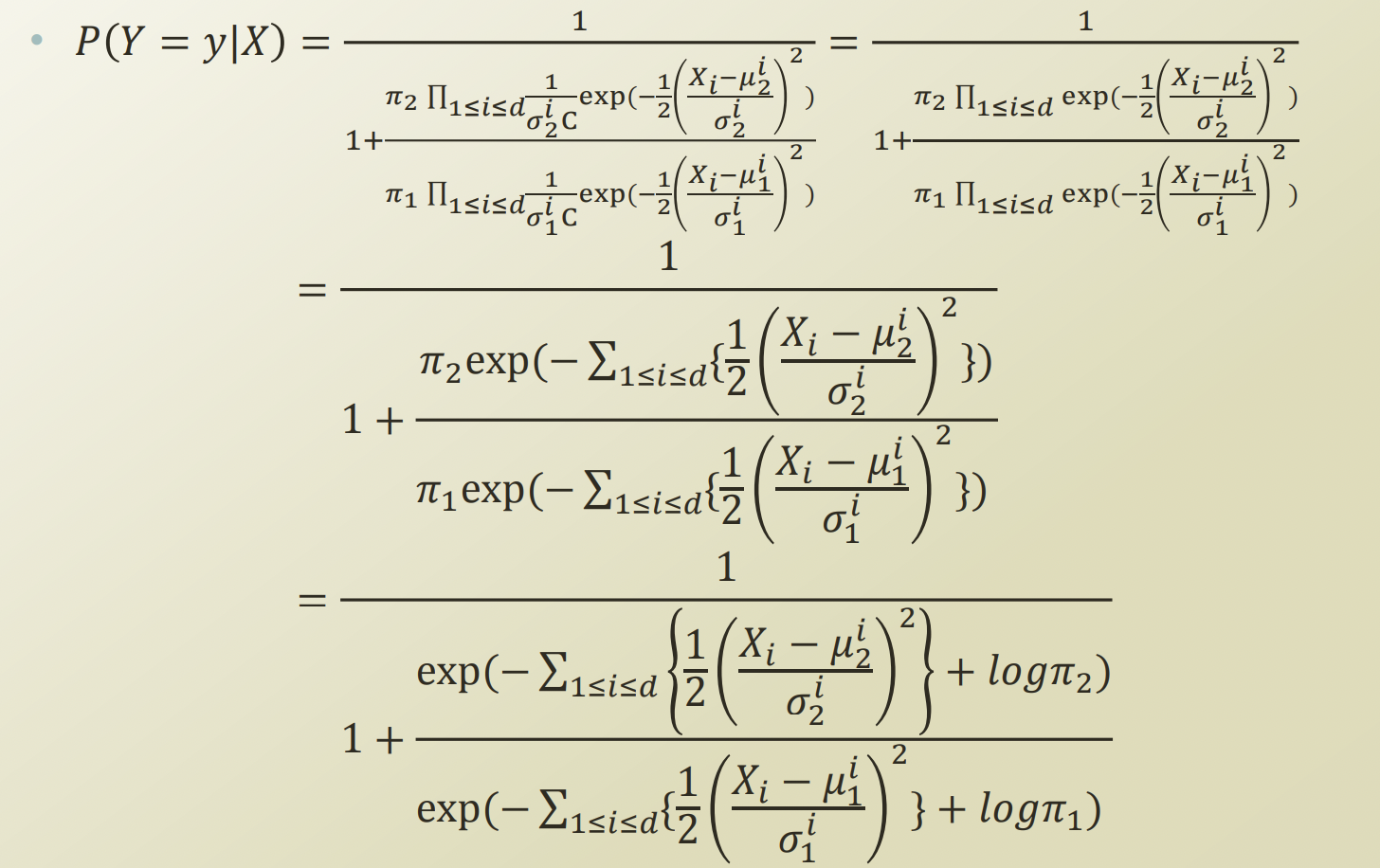
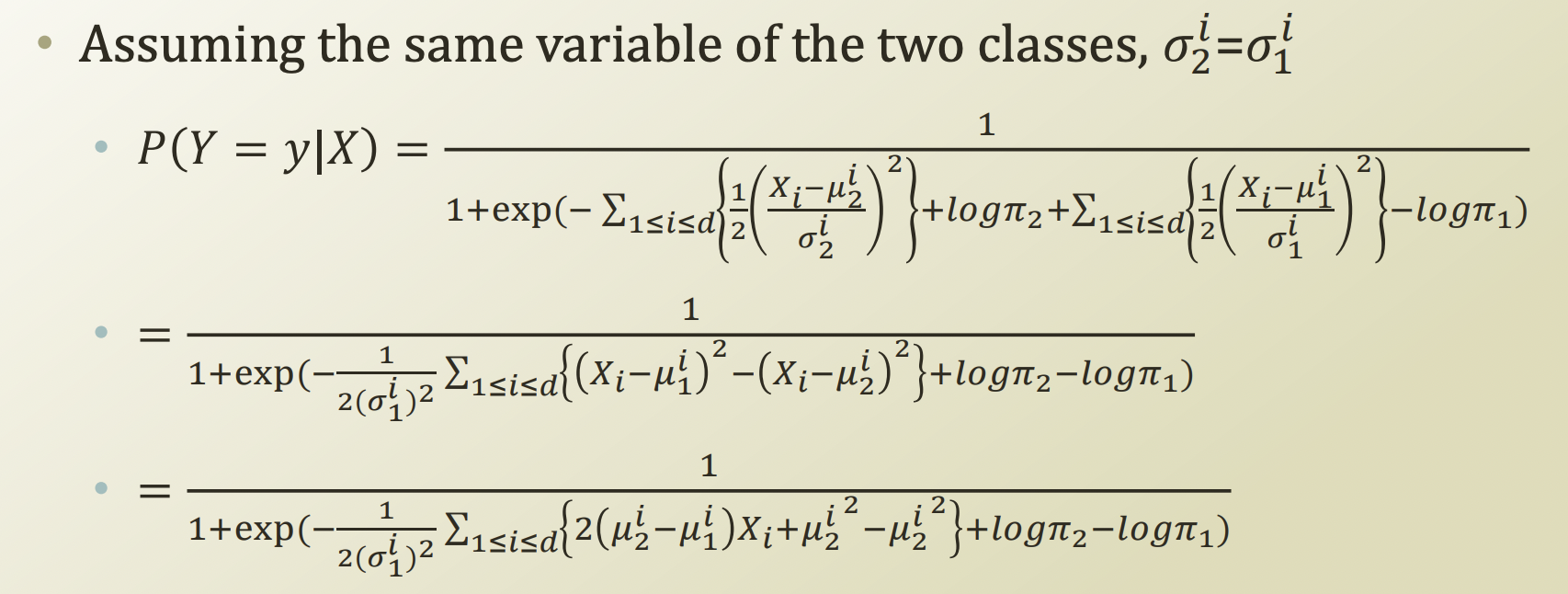
- 마지막 부분을 관찰해본다면, logistic regression에서 쓰이는 logstic function 형태와 같아졌고, 분모의 summation부분이 Xθ 와 같아졌음을 볼 수 있다.
- 위의 식을 얻으려면 필요한 조건:
- Naive assumption, same variance assumption
- gaussian distribution for P(X∣Y)
- Bernoulli distribution for P(Y)
Logistic Regression
- 필요한 조건(가정): logistic function에 피팅하겠다.
- Naive bayes보다는 더 간단함을 볼 수 있다.
- 또한, 일반적으로 더 좋은 성능을 보인다는 주장이 많다.
- 다만, prior 정보를 담을 수 있는 naive bayes가 장점이 있을 수 있기 때문에, 무엇이 더 좋다고 결론 지을 수 없다.
