데이터 전처리에 앞서 test와 train데이터를 합치고, 어느 부분을 손 댈지 확인해보자.
union = pd.concat([train.drop('Survived', axis=1), test], axis=0)
일단 어느 데이터를 사용할 지 정해야한다. Ticket은 티켓의 일련번호이고, Cabin은 자료에 너무 큰 구멍이 있어 사용하지 않는게 더 좋아보인다. Age_Group도 연령대 생존율을 보기 편하려고 만든 항목이니 제외한다. 즉 사용할 데이터는 다음과 같다.
Pclass : 1 = 1등석, 2 = 2등석, 3 = 3등석
Sex : male = 남성, female = 여성
Age : 나이
SibSp : 타이타닉 호에 동승한 자매 / 배우자의 수
Parch : 타이타닉 호에 동승한 부모 / 자식의 수
Ticket : 티켓 번호
Fare : 승객 요금
Embarked : 탑승지, C = 셰르부르, Q = 퀸즈타운, S = 사우샘프턴
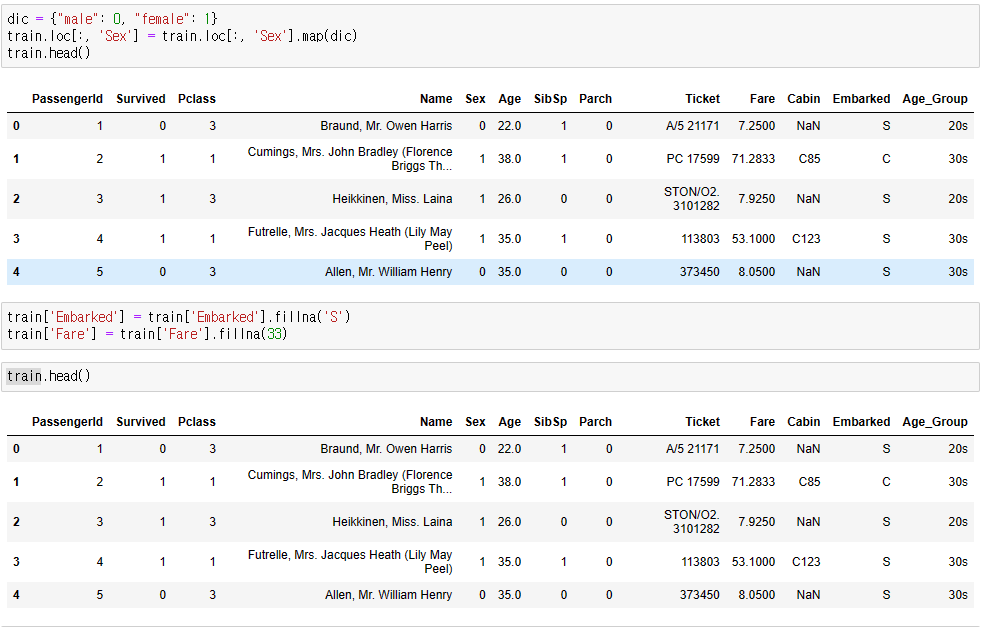
여기서 male, female, CQS 같은 문자열 자료는 0,1,2 같이 바꿔주도록 하자. 컴퓨터에겐 숫자를 학습시키는게 가장 효율적이니까.
먼저 Sex 문자열을 숫자로 변환해보자. male은 0, female은 1로 변환하겠다.
dic = {"male": 0, "female": 1}
union.loc[:, 'Sex'] = train.loc[:, 'Sex'].map(dic)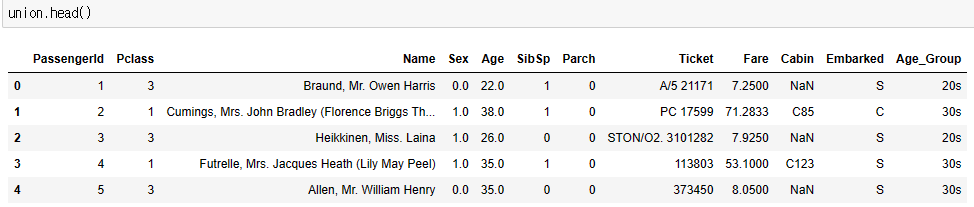
다음은 Embarked 의 문자열을 숫자로 변환할 것인데, Embarked에는 info에서 보았듯 2개의 NaN이 있다. 이 NaN을 어떻게 처리하는지는 사람마다 다르겠지만, 나는 가장 탑승자가 많았던 Southampton으로 채워넣기로 했다. 그리고 이왕 NaN값을 넣는 김에 Fare에 있던 1개의 NaN도 요금의 평균값을 내서 채워주자.
mean_value = union['Fare'].mean()
print(mean_value)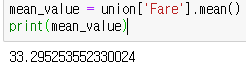
union['Embarked'] = union['Embarked'].fillna('S')
union['Fare'] = union['Fare'].fillna(33)
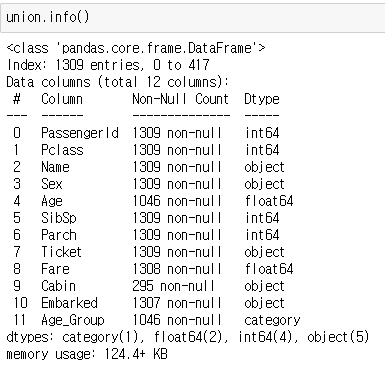
union.info()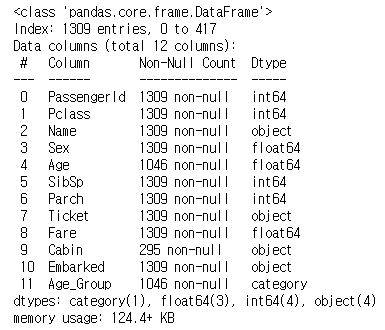
이제 가장 큰 문제인 Age의 NaN값을 처리해야 한다. Cabin처럼 엄청난 구멍도 아니고, 나이는 생존률에 큰 영향을 미치기에 잘 처리해줘야 한다. 다행히 영어 이름에는 Master, Miss, Mr, Mrs 처럼 나이에 영향을 받는 부분이 있어 이를 활용하면 좋을 것 같다.
union['Initial']=0
for i in union:
union['Initial']=union.Name.str.extract('([A-Za-z]+)\.')
pd.crosstab(union.Initial,union.Sex).T.style.background_gradient(cmap='summer_r')
뭔가 잘못된 것이 보인다. Mr에 여성비율이 이렇게 높다는건 Name에서 이니셜을 가져올때 문제가 생긴 것으로 보인다. 일단 train, test도 같은 방식으로 돌려봐 문제를 분석하자.
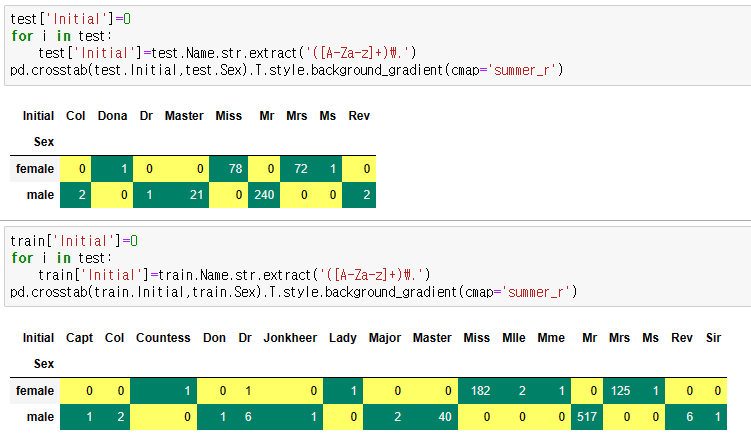
정작 train, test에서는 Mr가 문제없이 남성만 나온다. 즉, union을 만드는 과정에서 train, test가 깔끔하게 합쳐지지 않았다는 것이다. gpt에도 물어보고 방법을 찾았지만 해결방법을 찾지 못했기에 train, test 따로따로 진행하기로 하였다.
일단 union으로 진행했던 과정을 그대로 train에 적용한다.
그리고 이니셜을 Master, Miss, Mr, Mrs, Other로 정리한다. 남성이름은 Mr,여성 이름은 Mrs,Miss로 애매한건 Other로 넣는다.
train['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don','Dona'],['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr','Mrs'],inplace=True)
pd.crosstab(train.Initial,train.Sex).T.style.background_gradient(cmap='summer_r')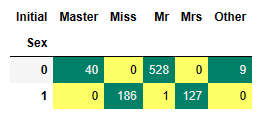
이제 이니셜 별 평균 나이를 구한다.
data.groupby('Initial')['Age'].mean()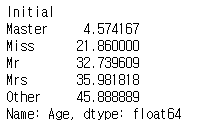
이제 각 이니셜에 나이를 넣고 NaN이 없는지 확인해보자.
train.loc[(train.Age.isnull())&(train.Initial=='Mr'),'Age']=33
train.loc[(train.Age.isnull())&(train.Initial=='Mrs'),'Age']=36
train.loc[(train.Age.isnull())&(train.Initial=='Master'),'Age']=5
train.loc[(train.Age.isnull())&(train.Initial=='Miss'),'Age']=22
train.loc[(train.Age.isnull())&(train.Initial=='Other'),'Age']=46
train.Age.isnull().any()
train.Age.isnull().sum()0이 나왔다면 성공이다. 그리고 데이터를 카테고리화 하는 binning 작업을 해주자. 4분위수를 확인해보고, qcut을 이용해 정해진 비율대로 binning하자.
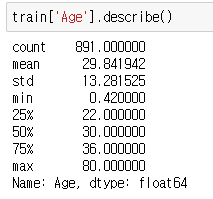
train['AgeCut'] = pd.qcut(train['Age'], 4, labels=[0,1,2,3])
train.drop('Age', axis=1, inplace=True)
train.head()
train['FareCut'] = pd.qcut(train['Fare'], 4, labels=[0,1,2,3])
train.drop('Fare', axis=1, inplace=True)
train.head()그리고 Embarked 열의 문자를 숫자로 바꿔주자.
dic = {"S": 0, "C": 1, "Q": 2}
train.loc[:, 'Embarked'] = train.loc[:, 'Embarked'].map(dic)
test.loc[:, 'Embarked'] = test.loc[:, 'Embarked'].map(dic)
train.head()
마지막으로 Fare행도 binning하자.
train['FareCut'] = pd.qcut(train['Fare'], 4, labels=[0,1,2,3])
train.drop('Fare', axis=1, inplace=True)
train.head()이제 머신러닝에 사용되지 않을 Ticket과 Cabin, PassengerId, Name열등 을 없애주자.
train.drop(['Name','Age','Ticket','Fare','Cabin','Initial','PassengerId','Age_Group'],axis=1,inplace=True)머신러닝에 들어갈 데이터가 준비되었다. 머신러닝에 들어가기 전에 데이터 시각화로 각 항목간 관계성도 한번 봐보자.
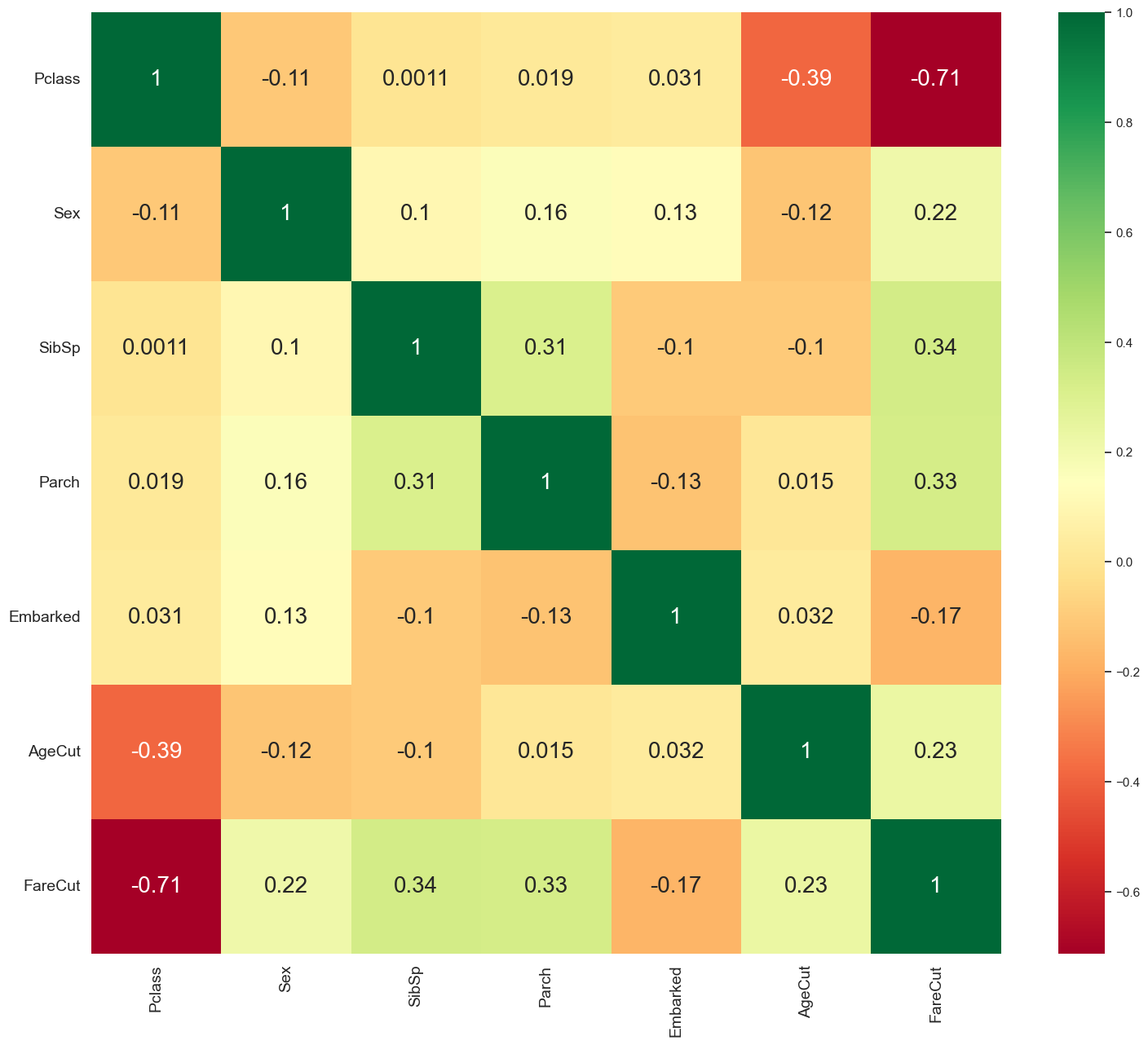
sns.heatmap(train.corr(),annot=True,cmap='RdYlGn',linewidths=0,annot_kws={'size':20})
fig=plt.gcf()
fig.set_size_inches(18,15)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()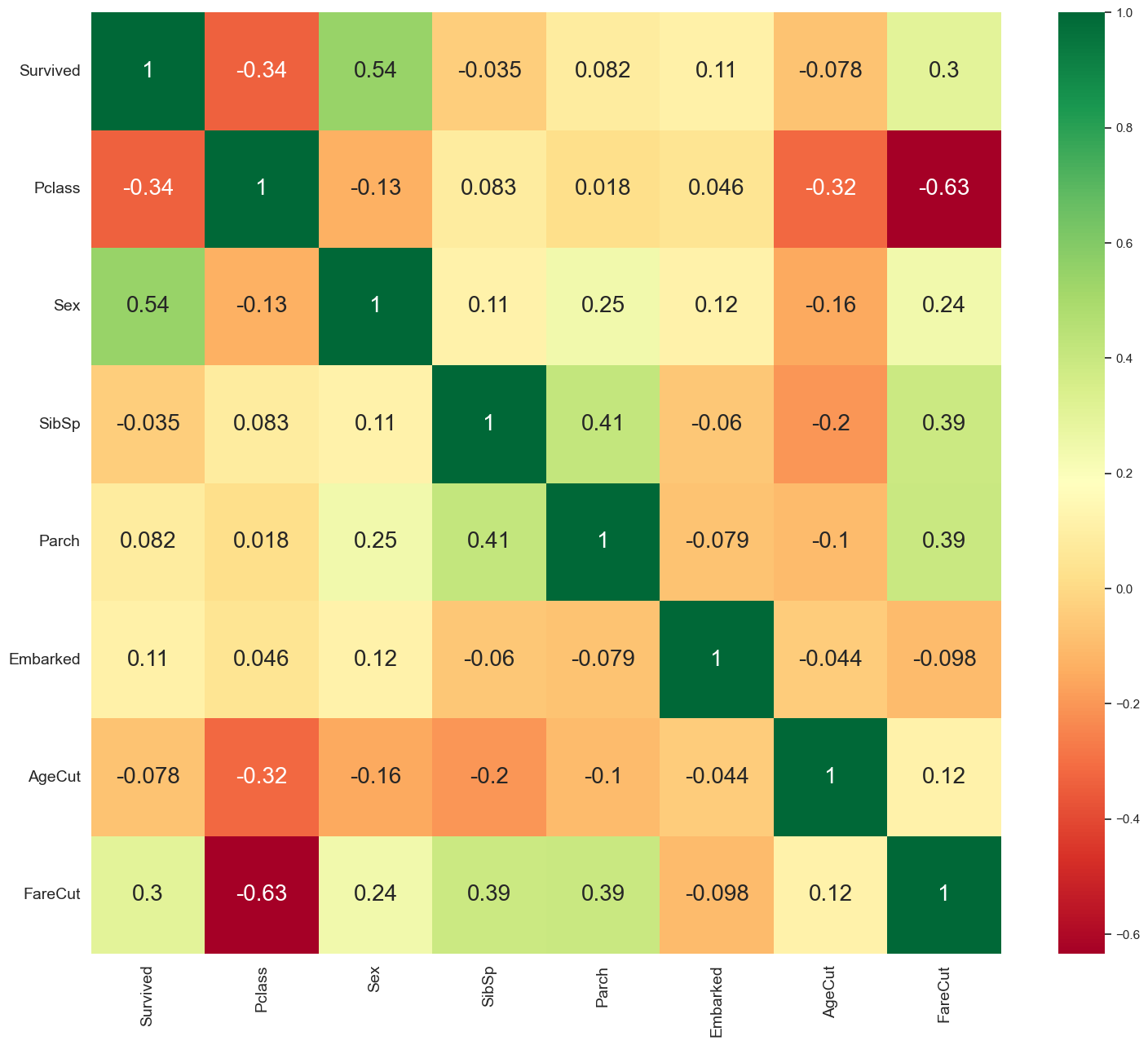
Pclass/FareCut의 관계와 SibSp/Parch의 관계를 비교해보면 클래스가 높을 수록(1등급) 비용(FareCut)을 많이 지불했고, 동승한 자매(SibSp)가 있으면 부모(Parch)도 같이 있다는 인과관계를 -0.63과 0.41이라는 숫자로 알 수 있다. 또한 클래스와 성별이 생존율에 가장 연관성 있다고 보여진다. 머신러닝을 돌렸을 때 결과와 비교하면 어떨지 궁굼하다.
위 공정을 그대로 test에도 적용하면 다음과 같이 시각화된다.
dic = {"male": 0, "female": 1}
test.loc[:, 'Sex'] = test.loc[:, 'Sex'].map(dic)
test['Embarked'] = test['Embarked'].fillna('S')
test['Fare'] = test['Fare'].fillna(33)
test.head()
test['Initial']=0
for i in test:
test['Initial']=test.Name.str.extract('([A-Za-z]+)\.')
pd.crosstab(test.Initial,test.Sex).T.style.background_gradient(cmap='summer_r')
test['Initial'].replace(['Mlle','Mme','Ms','Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don','Dona'],['Miss','Miss','Miss','Mr','Mr','Mrs','Mrs','Other','Other','Other','Mr','Mr','Mr','Mrs'],inplace=True)
pd.crosstab(test.Initial,test.Sex).T.style.background_gradient(cmap='summer_r')
test.loc[(test.Age.isnull())&(test.Initial=='Mr'),'Age']=33
test.loc[(test.Age.isnull())&(test.Initial=='Mrs'),'Age']=36
test.loc[(test.Age.isnull())&(test.Initial=='Master'),'Age']=5
test.loc[(test.Age.isnull())&(test.Initial=='Miss'),'Age']=22
test.loc[(test.Age.isnull())&(test.Initial=='Other'),'Age']=46
test.Age.isnull().any()
test.Age.isnull().sum()
test['AgeCut'] = pd.qcut(test['Age'], 4, labels=[0,1,2,3])
test.drop('Age', axis=1, inplace=True)
test.head()
test['FareCut'] = pd.qcut(test['Fare'], 4, labels=[0,1,2,3])
test.drop('Fare', axis=1, inplace=True)
test.head()
test.drop(['Name','Ticket','Cabin','Initial','PassengerId','Age_Group'],axis=1,inplace=True)
sns.heatmap(test.corr(),annot=True,cmap='RdYlGn',linewidths=0,annot_kws={'size':20})
fig=plt.gcf()
fig.set_size_inches(18,15)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.show()