데이터를 숫자로만 보는건 지루하니 seaborn으로 시각화해보자.
plt.style.use('ggplot')
sns.set()
sns.set_palette("Set1")
def chart(dataset, feature):
survived = dataset[dataset['Survived'] == 1][feature].value_counts()
dead = dataset[dataset['Survived'] == 0][feature].value_counts()
df = pd.DataFrame([survived, dead])
df.index = ['Survived', 'Dead']
df.plot(kind='bar', stacked=True)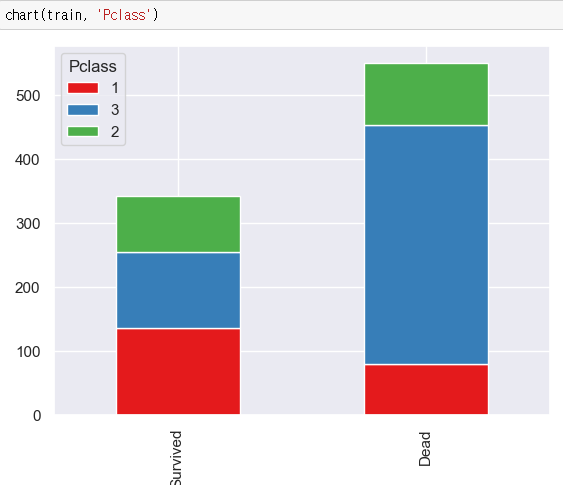
클래스에 따른 생존률이 크게 차이남을 한 눈에 볼 수 있다. 1등석은 생존자가 사망자의 2배, 2등석은 반반, 3등석은 사망자가 생존자의 3배 수준이다.
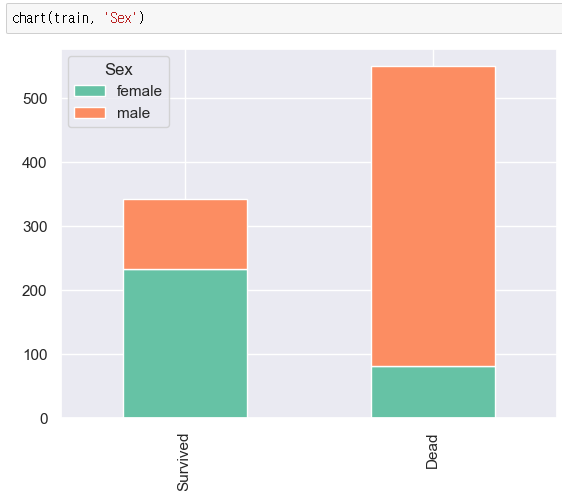
성별에 따른 차이도 크다. 여성과 아이를 먼저 구한다는 원칙이 이 당시에도 적용된 듯 하다. 한번 나이에 따른 결과도 확인해 보자.

나이에 따른 생존률을 보려면 20대,30대 단위로 나이를 묶을 필요가 있어 보인다.
bins = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90] # 연령대 구간 설정
labels = ['0~10','10대', '20대', '30대', '40대', '50대', '60대', '70대', '80대'] # 라벨 지정
train['Age_Rounded'] = train['Age'].round() # 소수점 값을 반올림하여 정수로 변환
test['Age_Rounded'] = test['Age'].round()
train['Age_Group'] = pd.cut(train['Age_Rounded'], bins=bins, labels=labels, right=True)
test['Age_Group'] = pd.cut(test['Age_Rounded'], bins=bins, labels=labels, right=True)
# 불필요한 열 제거
train.drop('Age_Rounded', axis=1, inplace=True)
test.drop('Age_Rounded', axis=1, inplace=True)
이렇게 Age_Group 을 만들어 주고 다시 잘 됬는지 head를 보자.
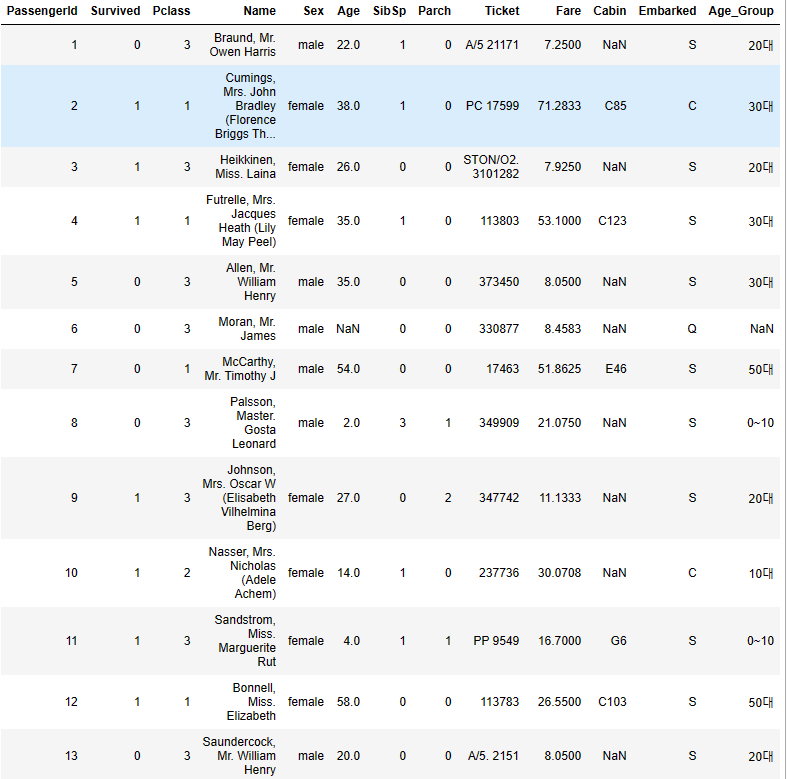
데이터 자체가 없는 NaN을 제외하곤 잘 적용되었다.right=False에서 right= True로 하면 20살이 10~20 구간에 들어가 10대로 적용되니 주의하자. 이제 표로 확인해보자.
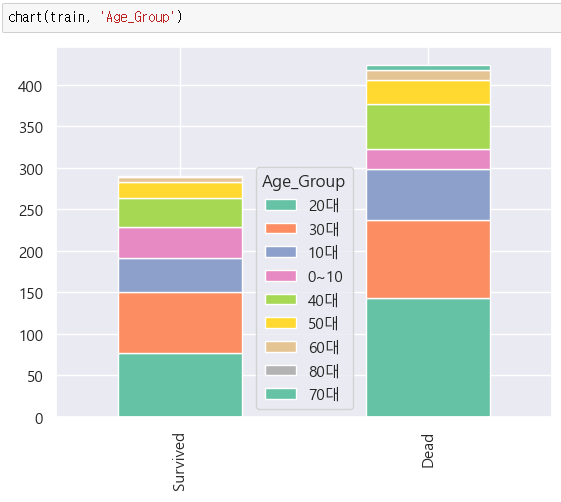
탑승객 수는 70,30,10 대 순으로 많았으며 생존률은 70대가 확연히 낮아보인다. 하지만 생존율을 따로 그래프로 만들면 좀 더 잘 보일것 같으니 만들어 보자.
def chart(dataset, feature):
survived = dataset[dataset['Survived'] == 1][feature].value_counts()
dead = dataset[dataset['Survived'] == 0][feature].value_counts()
df = pd.DataFrame([survived, dead])
df.index = ['Survived', 'Dead']
# 생존율 계산
df.loc['Survival_Rate'] = (df.loc['Survived'] / (df.loc['Survived'] + df.loc['Dead'])) * 100
ax = df.plot(kind='bar', stacked=True)
plt.legend(loc='upper left')
# 함수 호출
chart(train, 'Age_Group')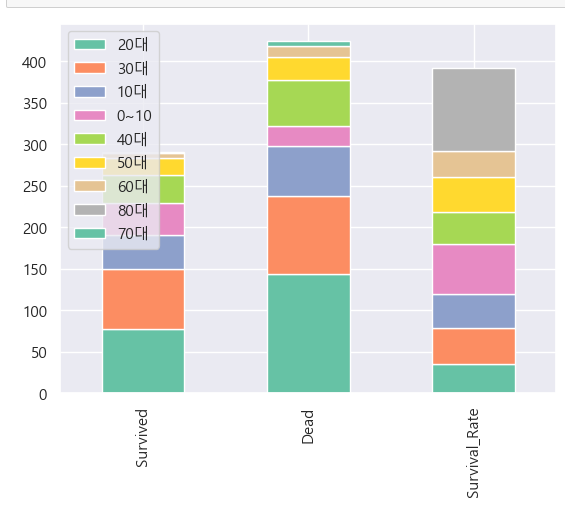
이렇게 보니 70대의 생존률이 크게 낮은것이 한눈에 보인다. 80대의 높은 생존률은 80대 인원수 자체가 워낙 적었기 때문으로 보인다.
다음은 탑승지에 따른 차이도 확인해 보자.
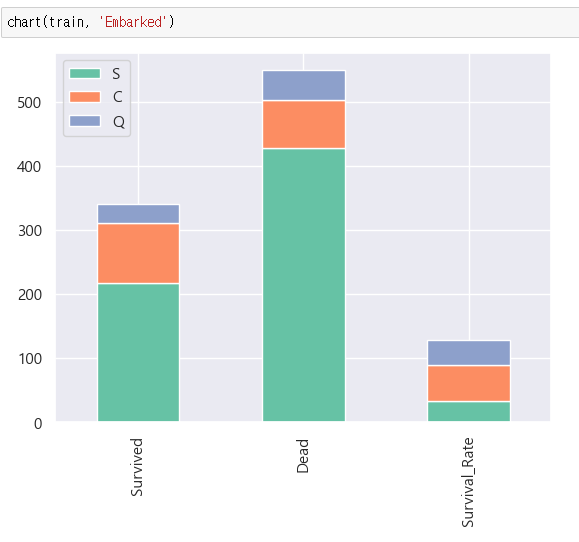
의외로 차이가 난다. 아마 탑승지에 따라 1,2,3등석 비율이 달라서 그런것 이 아닐까? 이번에는 탑승지에 따른 클래스 차이를 확인해 보자.
def chart_1(dataset, feature):
Southampton = dataset[dataset['Embarked'] == 'S'][feature].value_counts()
Cherbourg = dataset[dataset['Embarked'] == 'C'][feature].value_counts()
Queenstown = dataset[dataset['Embarked'] == 'Q'][feature].value_counts()
df = pd.DataFrame([Southampton, Cherbourg, Queenstown])
df.index = ['Southampton', 'Cherbourg', 'Queenstown']
ax = df.plot(kind='bar', stacked=True)
plt.legend(loc='upper left')
# 함수 호출
chart_1(train, 'Pclass')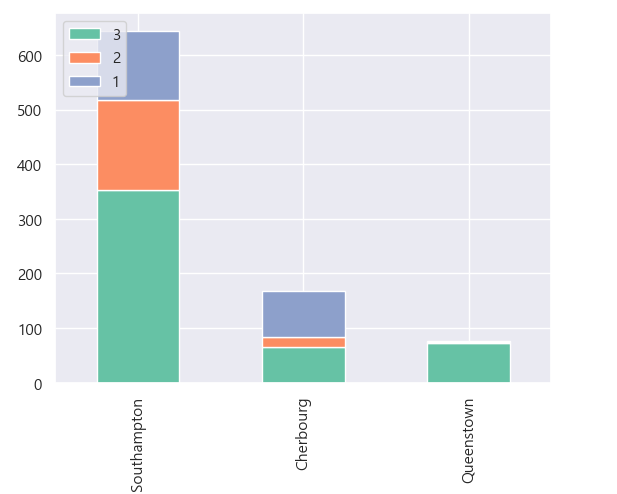
Cherbourg 탑승지의 생존률이 높았던 이유는 1등석 인원의 비율이 높았기 때문이었다. 반대로 Queenstown은 3등석 비율이 매우 높기에 낮은 생존률을 보였던 것이다.
