[목차]
- Activation Functions
- Data Preprocessing
- Weight Initialization
- Batch Normalization
- Babysitting the Learning Process
- Hyperparameter Optimization
Activation Functions
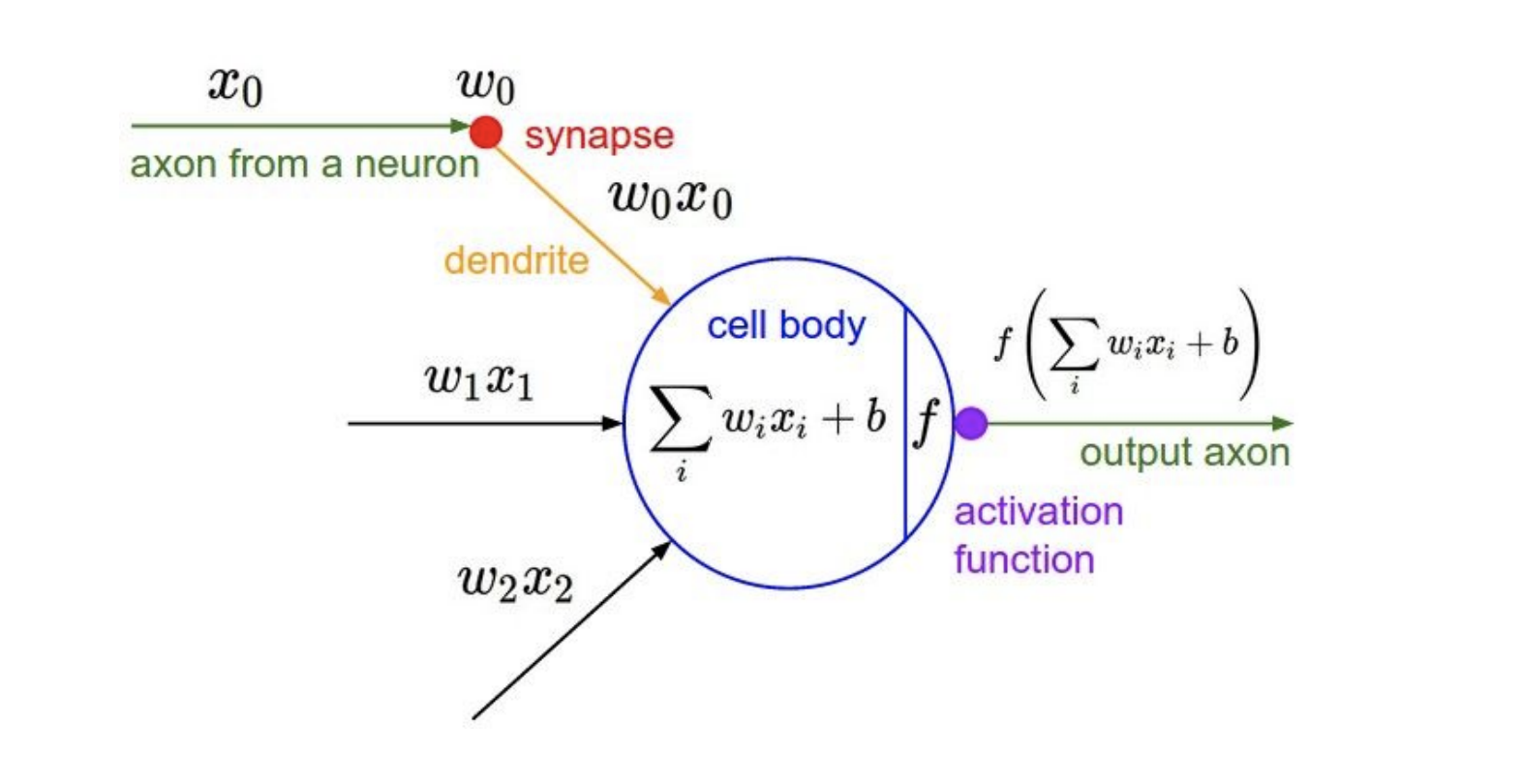
수식에 activation functions을 씌우는 그림이며, activation 종류는 다음과 같다.
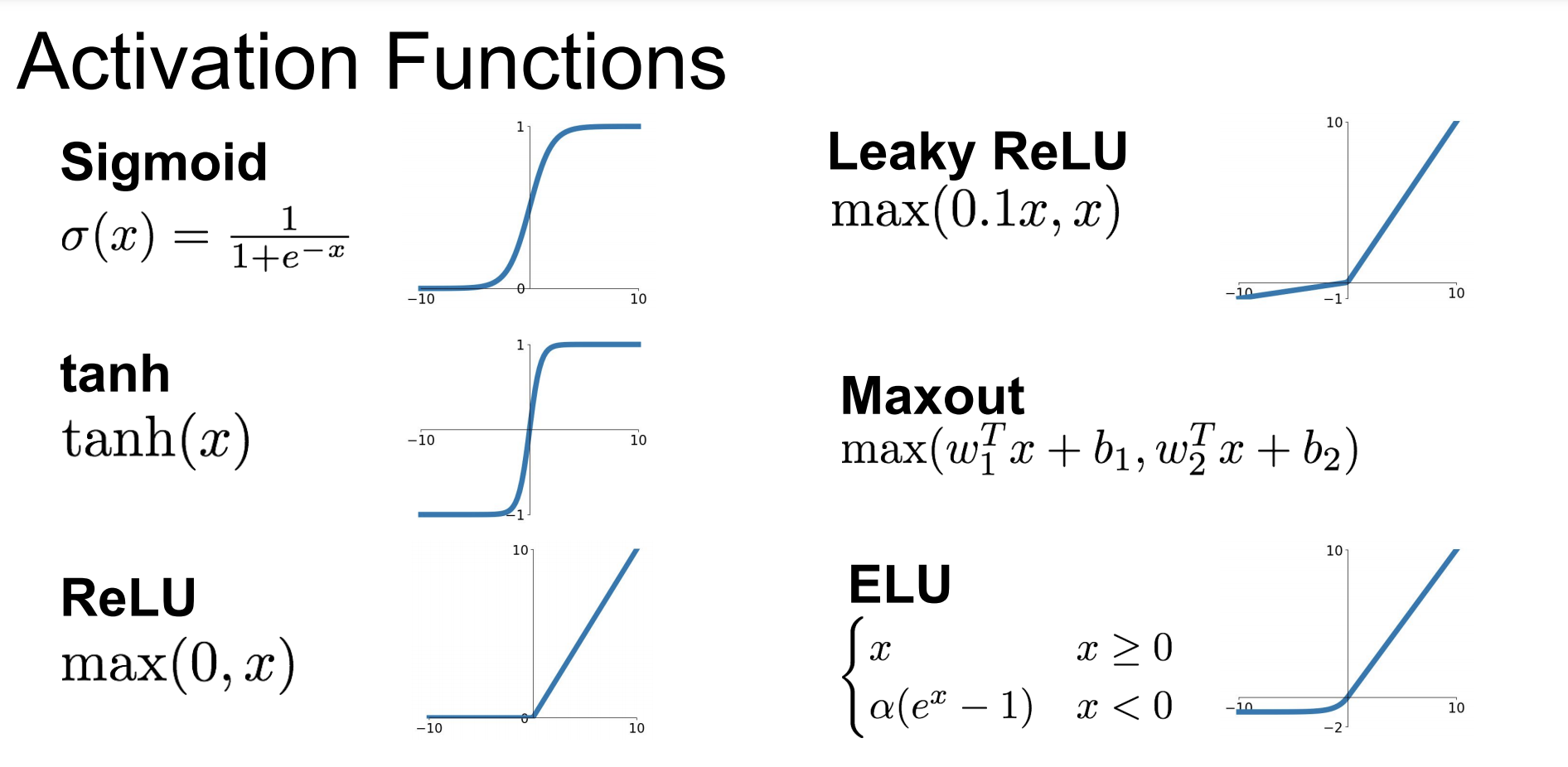
물론 이것들 보다 훨씬 다양한 종류의 activation functions들이 있다. 하지만 가장 많이 사용하는 위주로 모아놓은 것이다.
sigmoid

첫번째로 소개할 activation function은 sigmoid 함수이다.
sigmoid 함수의 문제점이 3가지가 있다.
1. neurons의 신호가 죽는다.(gradients가 0이 된다)
2. output이 zero-centered가 아니다.
3. exp()의 계산 비용이 비싸다.
tanh

두번째로 소개할 activation function은 tanh 함수이다.
sigmoid의 함수의 문제점 중 하나인 2.(zero-centered)문제는 해결됬지만,
아직 neuron이 신호가 죽는 문제(gradient가 0이 되는 문제)는 해결되지 않았다.
ReLU
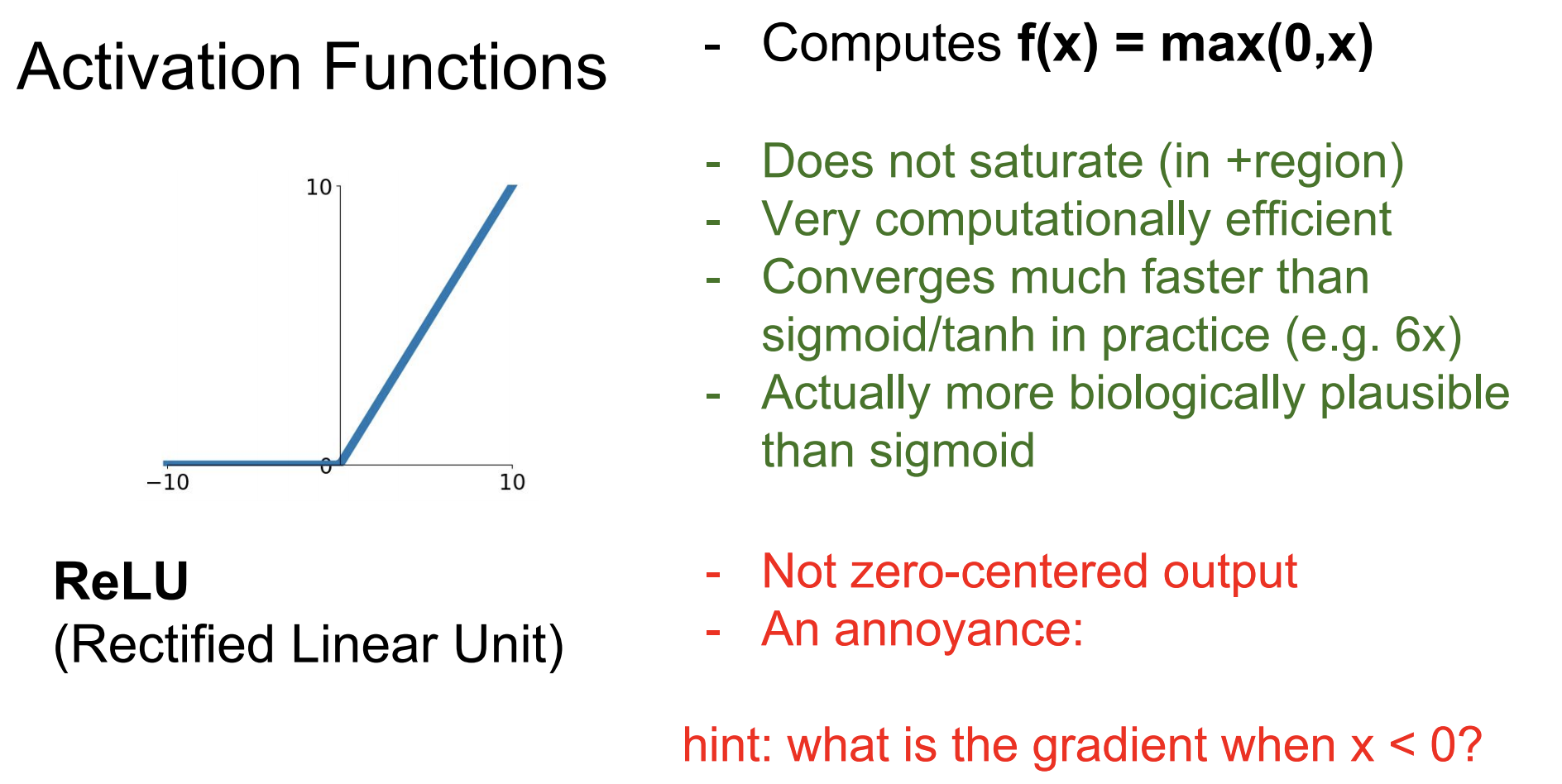
세번째로 소개할 activation function은 ReLU이다.
지금 가장 많이 그리고 널리 쓰이는 함수이다.
양수(+)부분에선 saturate되지 않는다(gradient가 0이 되지 않는다).
(- 부분에선 saturate된다.)
하지만 아직 sigmoid의 zero-centered문제는 해결되지 않았다.
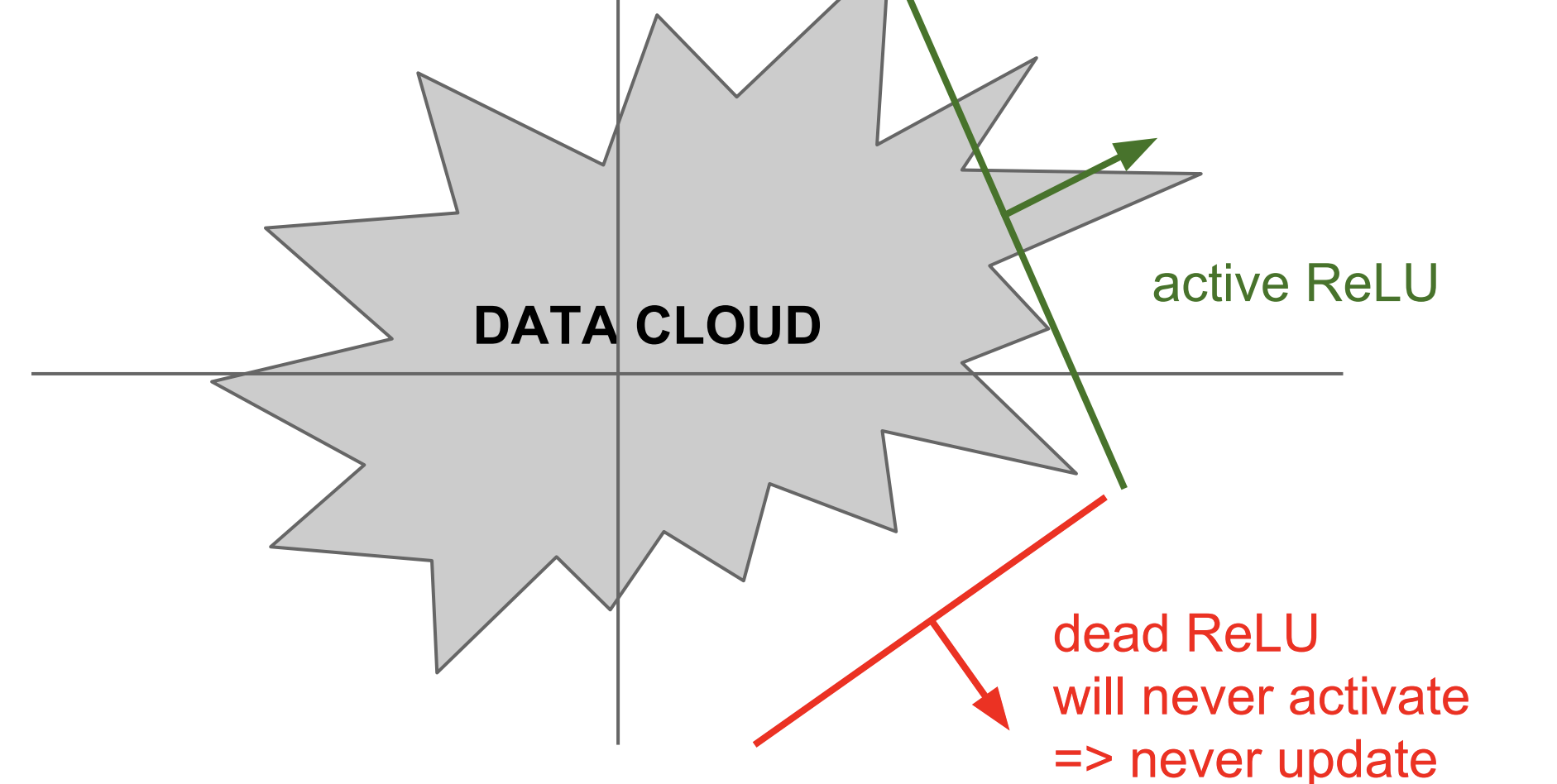
위의 그림을 살펴보면 Data Cloud는 Training data이며, dead ReLU는 never update라고 적혀있다. 즉, 데이터들이 범주 안에 들어가지 않으면 업데이트가 되지 않는다는 얘기다.
Leaky ReLU

Leaky ReLU의 다른 점은 -부분에 0.01를 추가해줘서 saturate되지 않도록 해줬다.
즉, neuron의 신호가 더이상 죽지 않게 된다.
0.01부분을 로 바꿔서 임의로 지정해주는 PReLU도 있다.
ELU

ELU는 ReLU와 Leaky ReLU의 중간 지점에 있는 함수라고 생각하면 된다.
Leaky ReLU와는 다르게 음수(-)부분이 saturation 영역인 것을 볼 수 있다.
activatin function 정리
- Use ReLU. Be careful with your learning rates
ReLU함수를 써라. learning rates를 조심해서 써야한다. - Try out Leaky ReLU / Maxout / ELU
Leaky ReLU / Maxout / ELU는 시도해봐라. - Try out tanh but don’t expect much
tanh는 시도해보되 결과를 기대하지마라. - Don’t use sigmoid
sigmoid는 쓰지마라.
