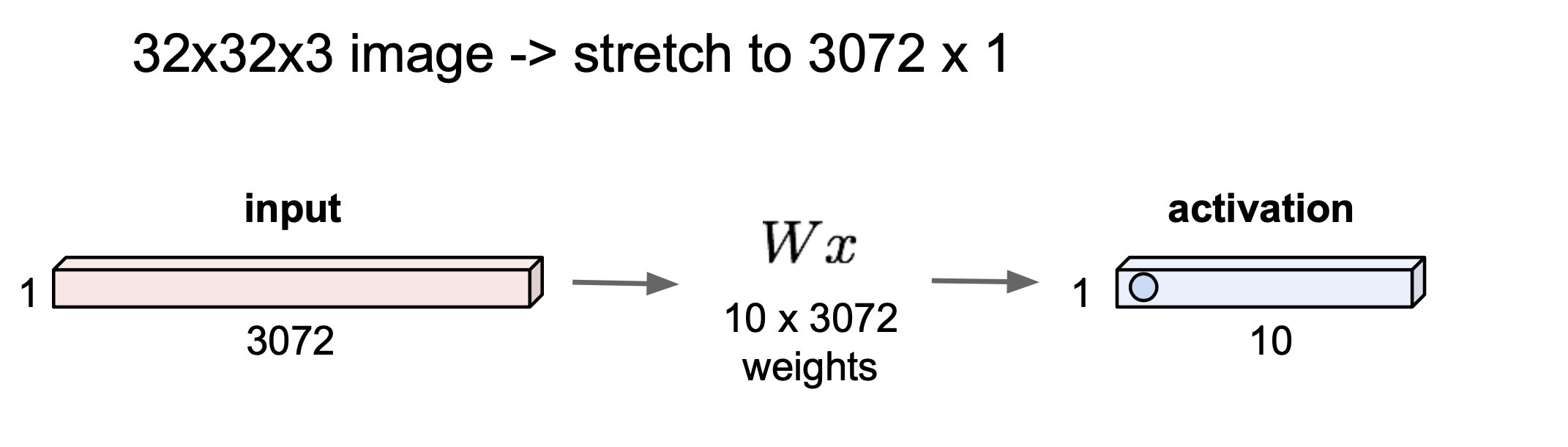
Fully Connected Layer
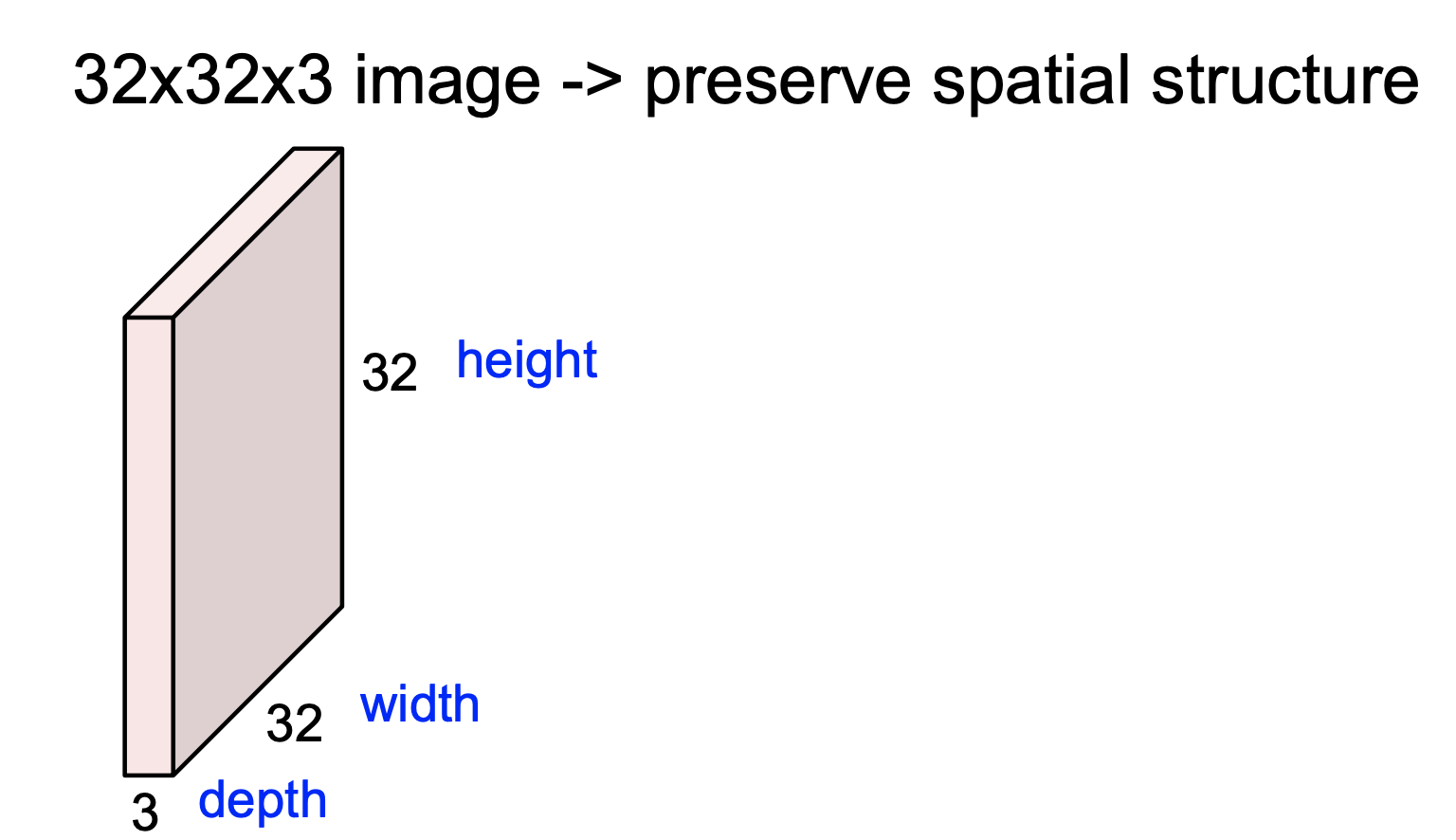
Convolutional Layer
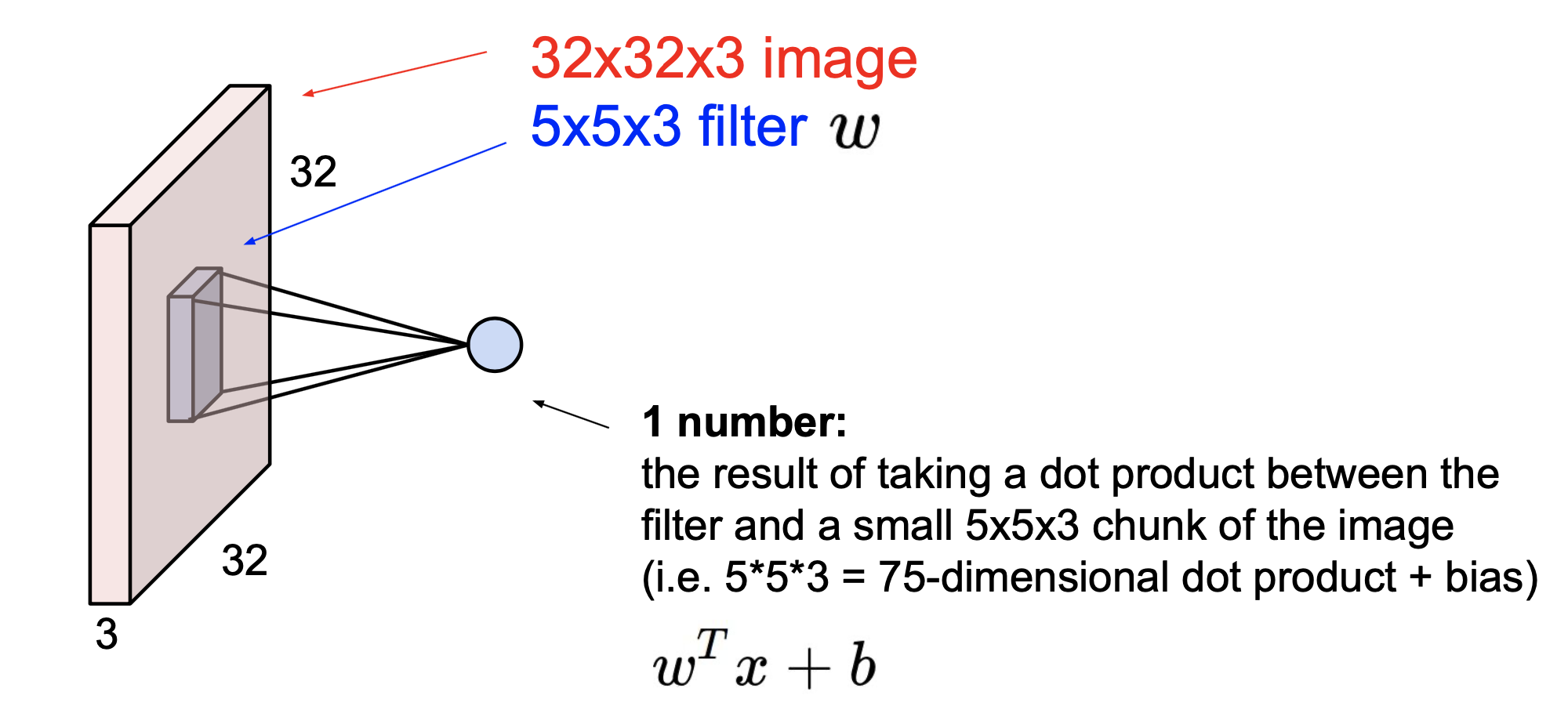
filter는 가중치 역할을 한다.

아래와 같은 연산을 행한 후
activation map이라는 출력이 생긴다.
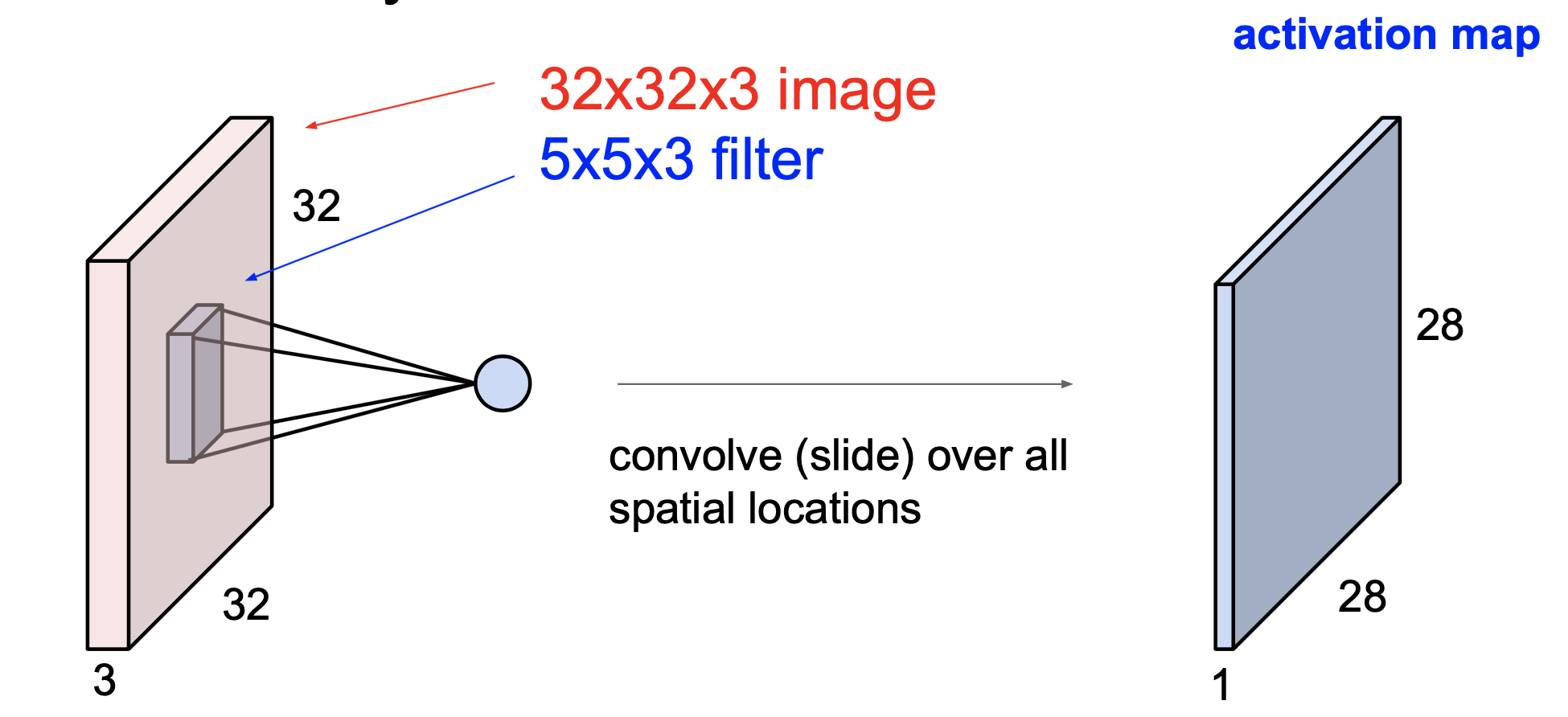
연산할 때 filter의 갯수를 늘리면, filter의 갯수와 상응하는 activation map이 생성된다.
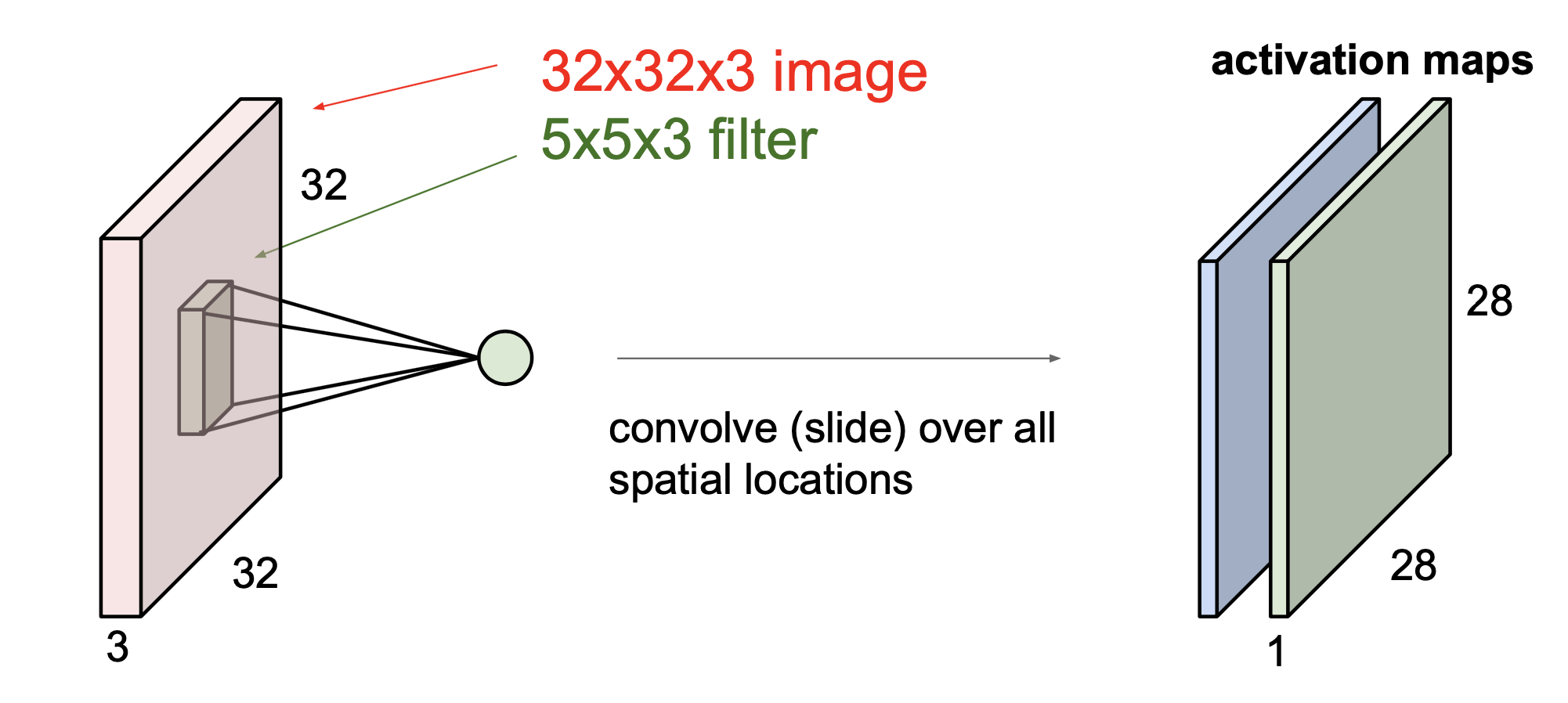
보통 Convolution layer에선 여러 개의 필터를 사용한다. 왜냐하면 필터마다 다른 특징을 추출하고 싶기 때문이다. 여러개의 필터를 우리가 임의대로 쌓을 수 있으며, 5x5 필터가 6개 있다면 activation map은 6개가 될 것이다.
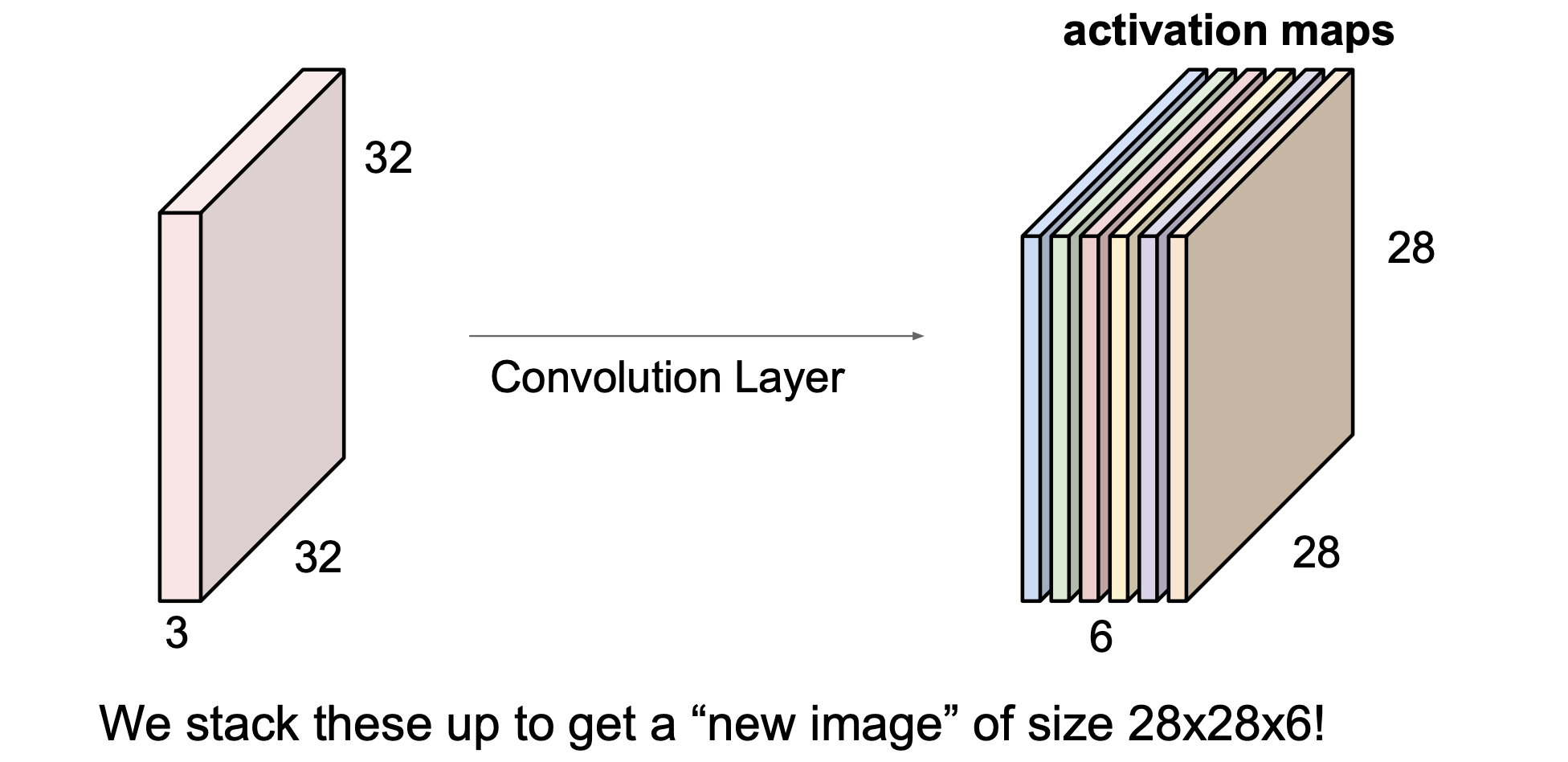
위의 기본 Convolutional Layer를 기반으로 ConvNet을 만들수 있다.
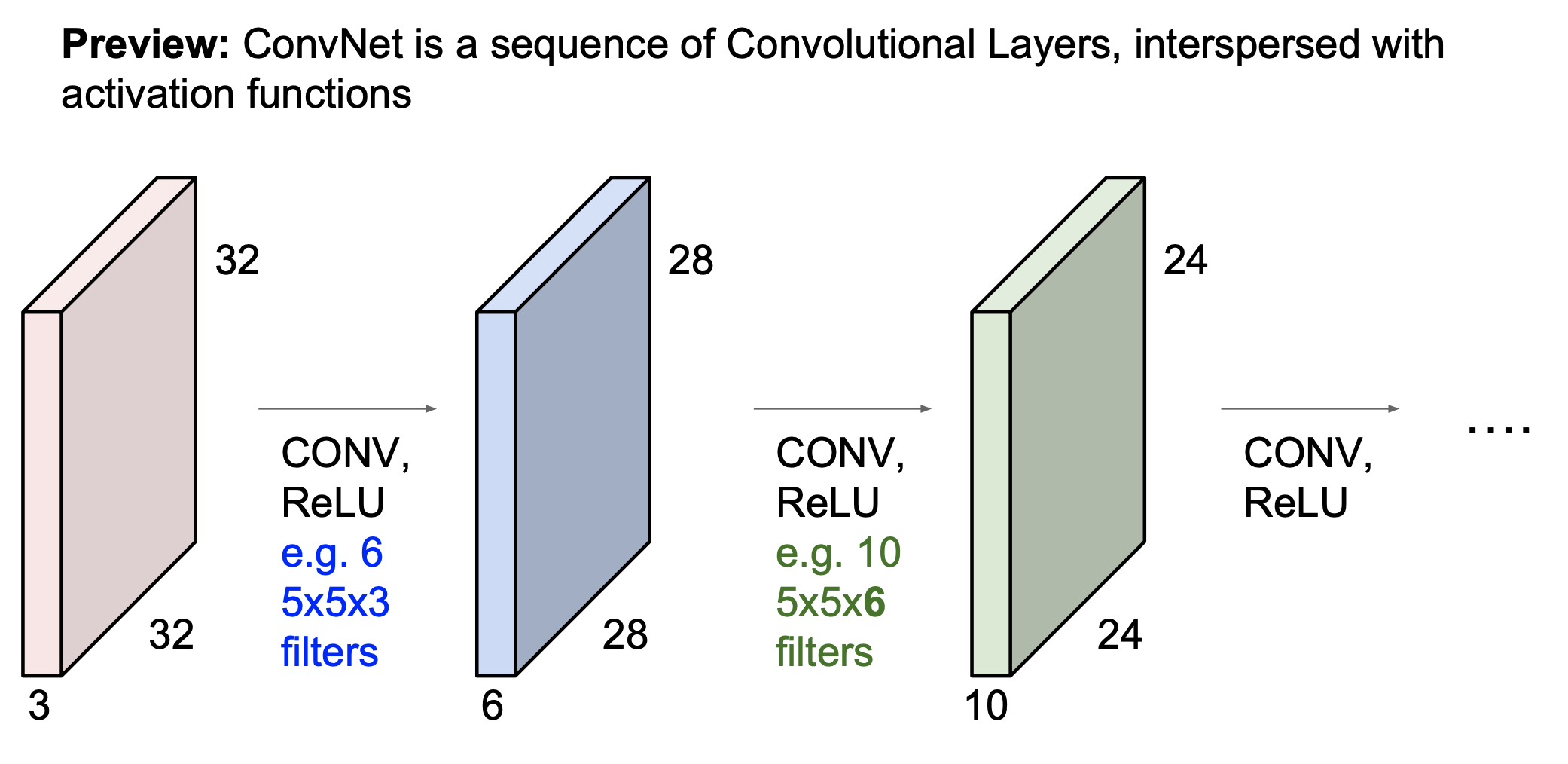
ConvNet의 Flow는 아래와 같다.

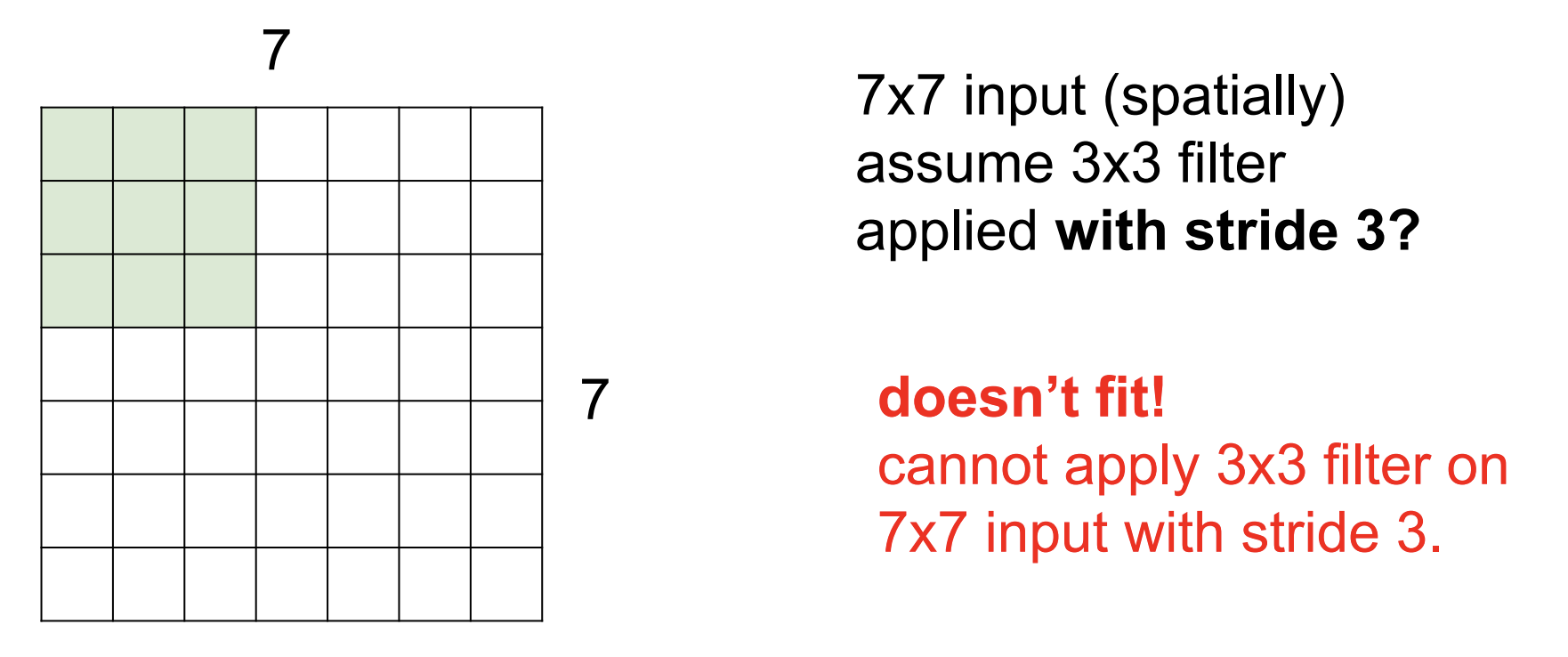
stride
filter가 layer를 훑을때 stride를 설정해주면 설정값 대로 건너뛰면서 연산한다.
<stride = 1 일때>
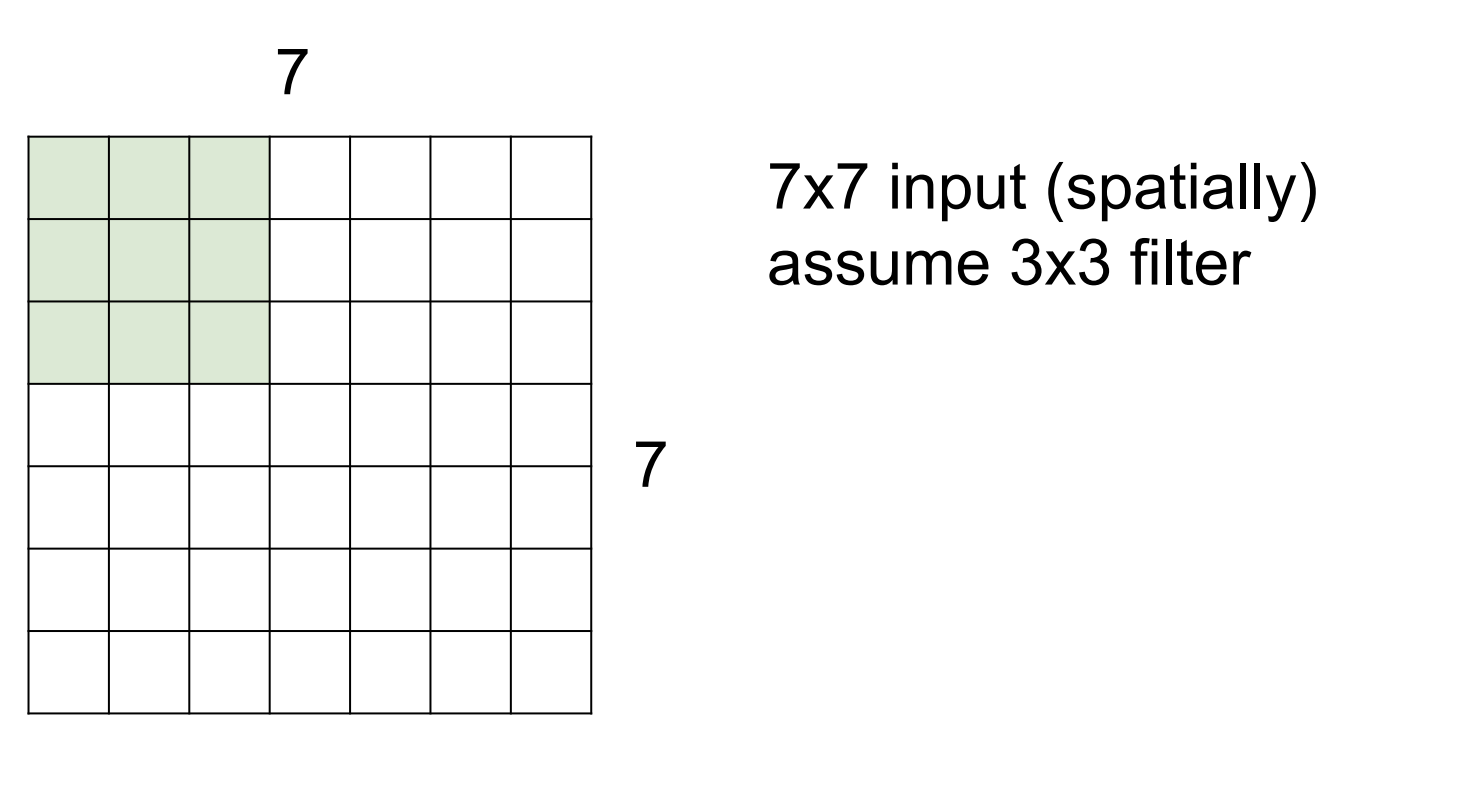
<stride = 2 일때>
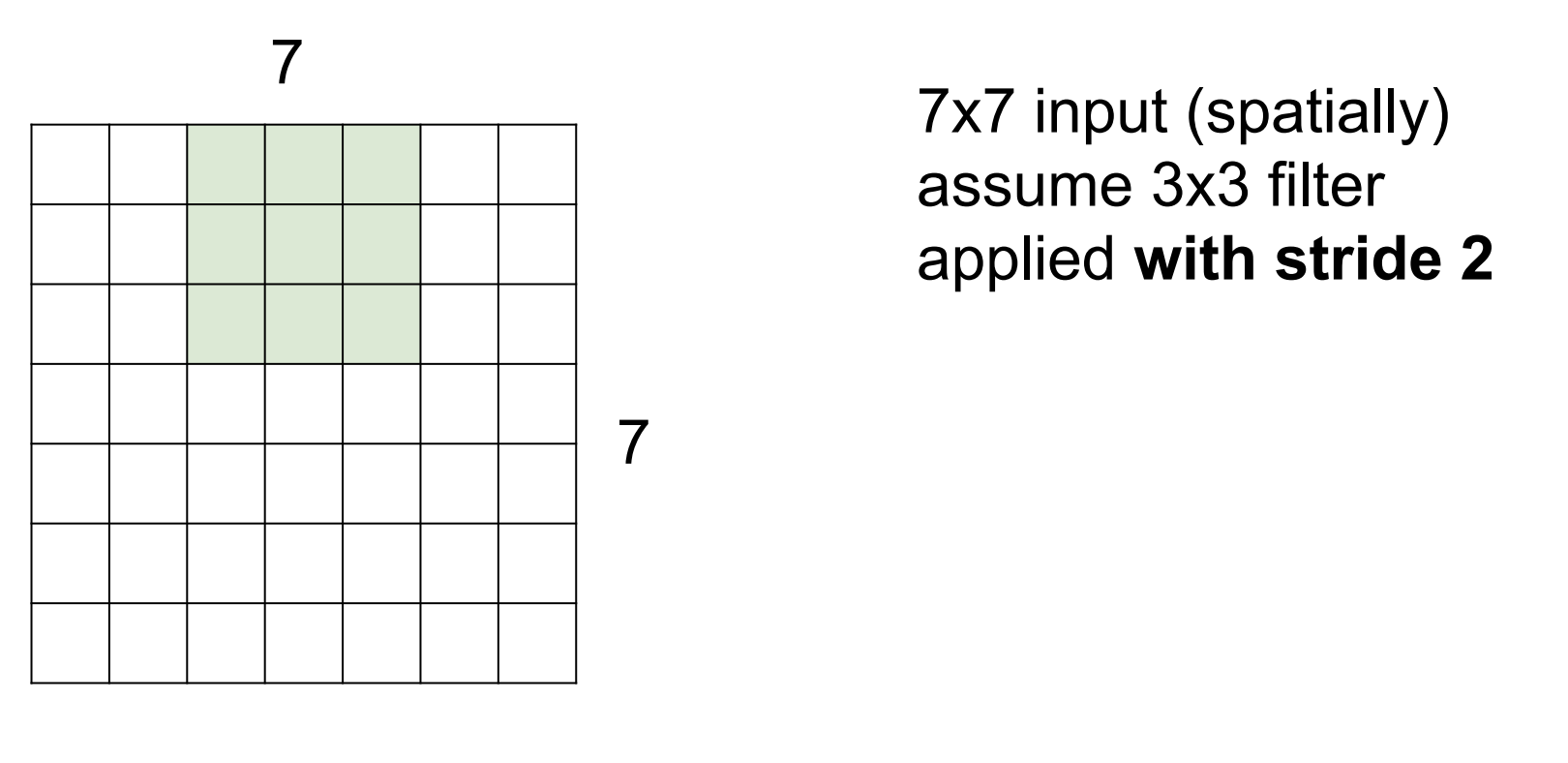
<stride = 3 일때 해당 input에는 동작하지 않는다>
pooling
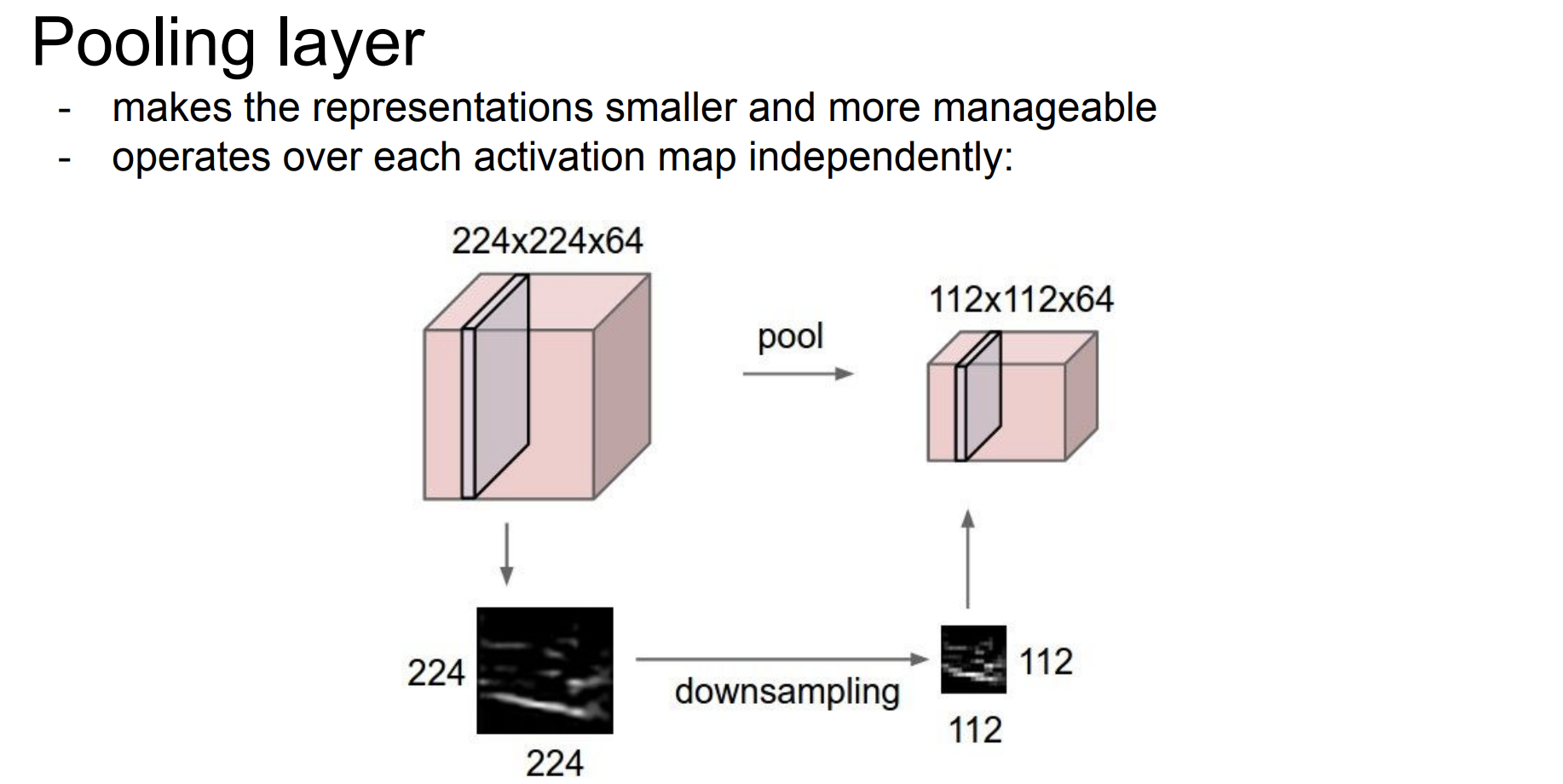
- 데이터의 크기를 작게 만들어 준다.
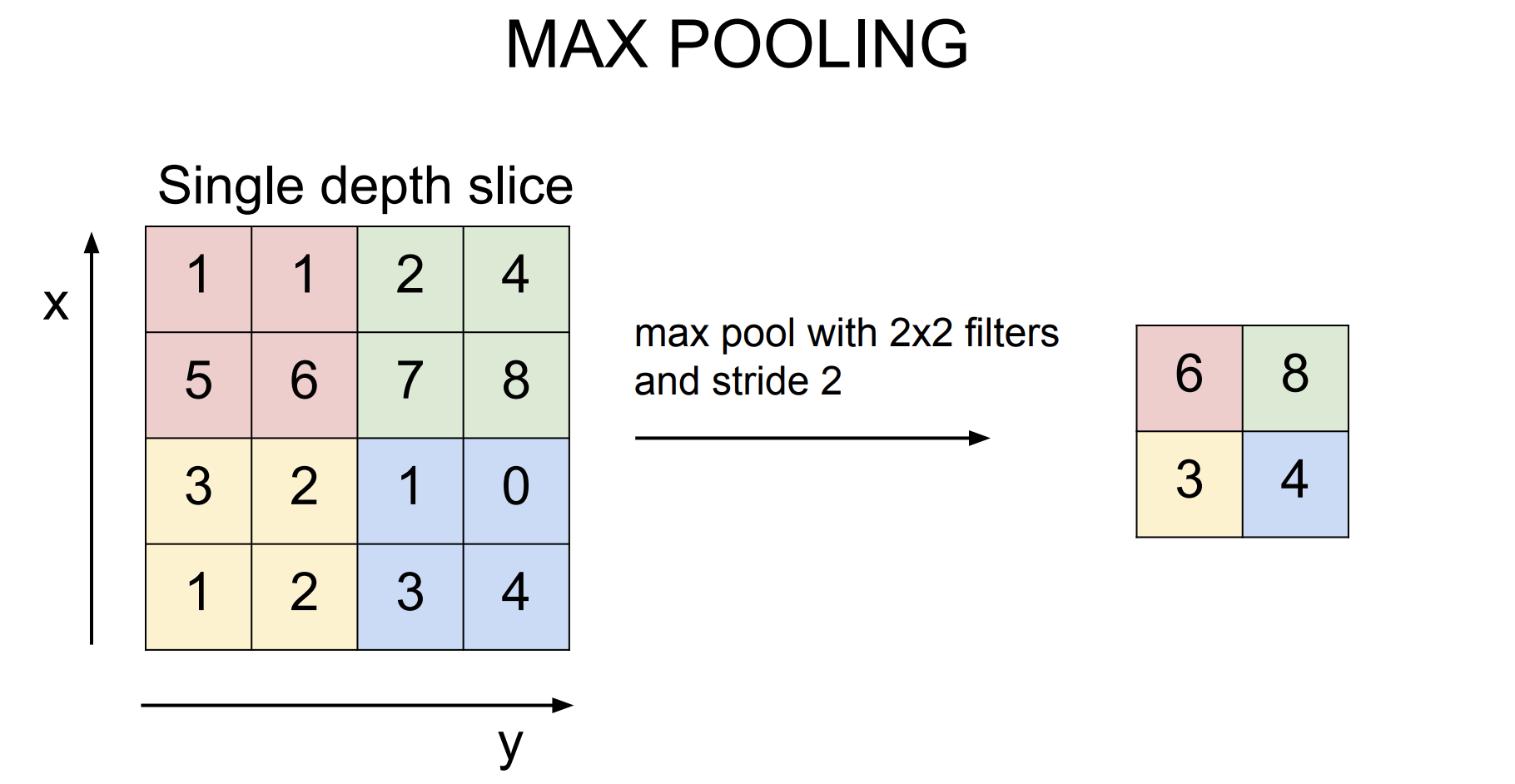
pooling 중 많이 쓰는 것은 Max Pooling이며 위의 그림과 같이 해당영역에서 가장 큰 숫자를 선택해 데이터의 크기를 축약한다.
stride가 일반적으로 pooling보다 성능이 더 좋다고 알려져 있으며,
실제로도 성능이 잘 나오는 경우가 다수다.
