- Publish: IJCV 2021
- YEAR: 2021
- LINK: https://arxiv.org/abs/2109.01134
Summary
- CLIP: 이전 representation learning method 와는 다르게, vision, language를 하나의 feature space 상에 align
- 이를 통해 downstream task에서 prompting 을 이용한 zero-shot transfer 가 가능해짐
- 본 논문에서는 이러한 모델을 실제로 배포하는 데 있어 가장 큰 과제는 신속한 엔지니어링임을 지적
- 즉 도메인 전문 지식이 필요하고 시간이 많이 소요되는 작업
- 약간의 prompt 변경이 성능에 큰 영향을 미칠 수 있으므로 prompt engineering 에 상당한 시간을 투자해야 한다는 것을 보여줌
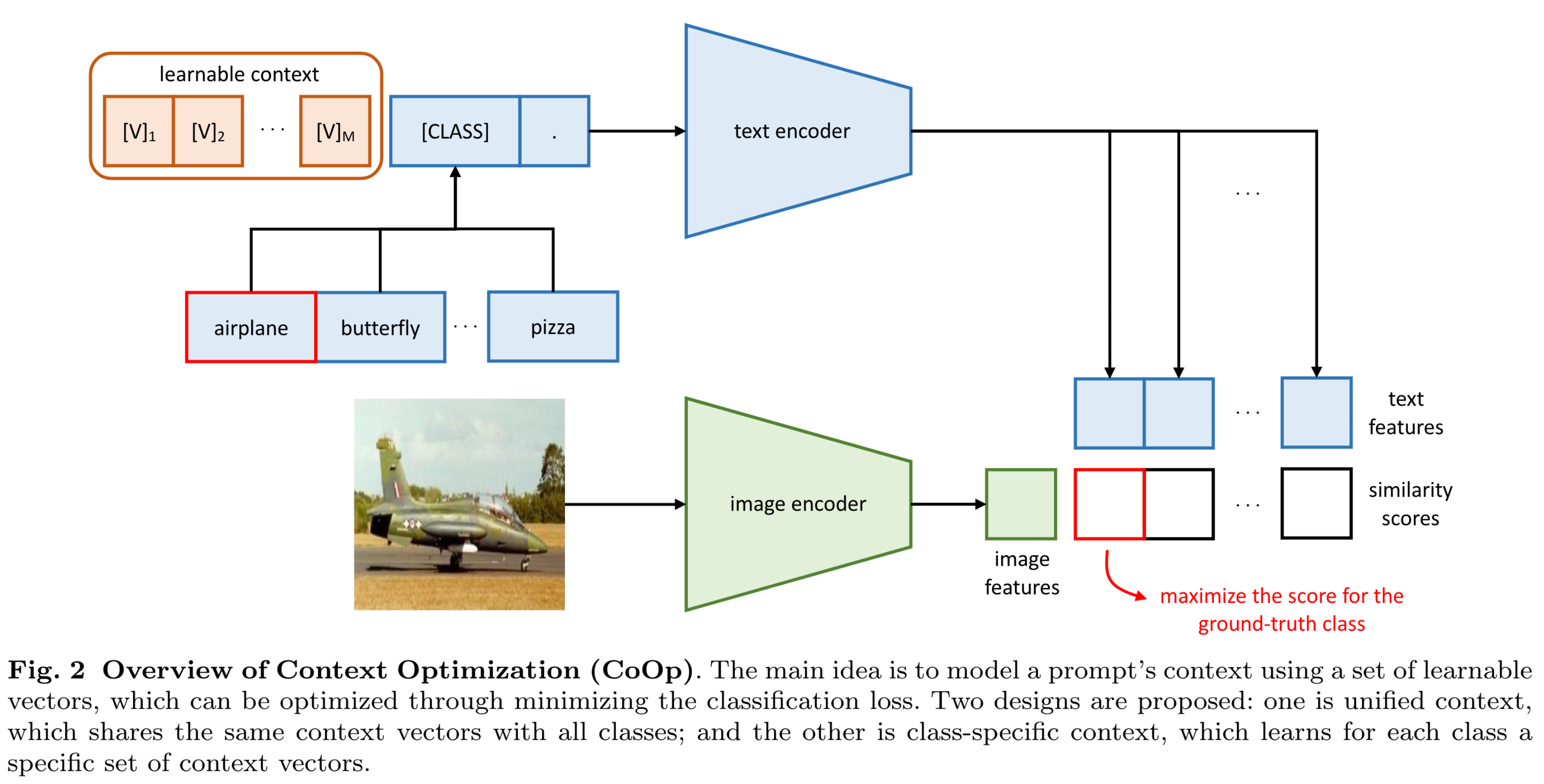
- Context Optimization (CoOp) 제안
- Prompt learning research 에서 영감을 받음
- prompt's context words를 learnable 한 벡터로 바꾸어 모델링
- CLIP과 같은 vision-language 모델을 image recognition에 효과적으로 적용할 수 있는 방법
Method
(Section 3.1 Vision-Lanuage Pre-training 생략)
Context Optimization
- Unified Context (context token)
:- : word embedding과 동일한 차원의 vector
- : hyperparameters
- 따라서, prediction probability 는 아래와 같이 쓸 수 있음
- Training
- Cross-entropy
- Context token 만 학습
Experiments
Dataset
- ImageNet
- Caltech101
- Oxford-Pets
- StanfordCars
- Flowers102
- Food101
- FGVCAircraft
- SUN397
- DTD
- EuroSAT
- UCF101
Result
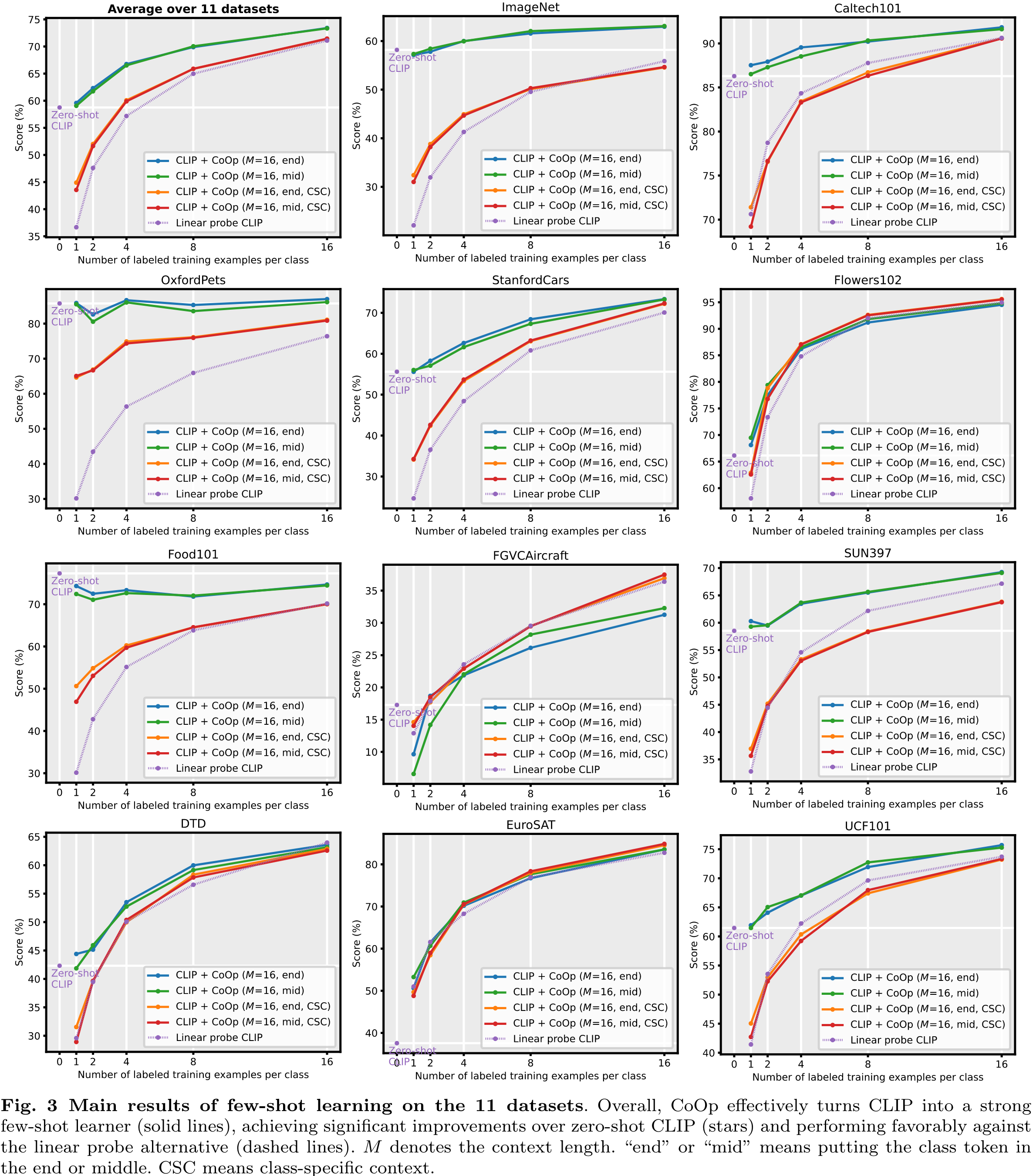

정말 알아?