[Paper] SINC: Spatial Composition of 3D Human Motions for Simultaneous Action Generation
paper

그래도 그동안 논문을 읽지 않은 것은 아닌데 ... velog에서의 논문 리뷰는 꽤 오랫동안 취었네 ^^ ...
앞으로 일주일에 한 논문 리뷰하기 프로젝트 시작!
📑 SINC: Spatial Composition of 3D Human Motions for Simultaneous Action Generation
0. Overview
이 논문을 먼저 전반적으로 훑어보자.
먼저, 이 논문 저자들의 목적은 텍스트가 동시에 들어왔을 때, 정확하게 두 텍스트의 의미를 담고 있는 모션을 생성하는 것이다. 쉽게 예를 들자면, waving hand, 즉 손을 흔들면서 walking 걸어가는 액션을 생성하도록 한다. 이를 달성하기 위해서 사용하는 방법이 바로 Spatial compostion 이다.
이 Spatial composition을 단순히 한 줄로 설명하자면, body, 즉 신체에서 다른 부분들의 움직임 (손을 흔드는 것, 다리로 걷는 것) 을 적절히 판단한 후 이를 하나의 신체에서 가능하도록 모션을 합친다. 어떻게 할 수 있는지는 이후 좀 더 자세히 알아보도록 하자.
이 논문의 contribution을 정리하자면 다음과 같다.
- 3D human motion을 위한 spatial composition task의 new benchmark 제안
- new evaluation metric 제안
- GPT-guided 데이터 생성 방법 제안
- BABEL dataset의 추가적인 학습 데이터셋 제안
자, 그럼 이제부터 본격적으로 SINC를 뜯어보도록 하자.
- 목적: 텍스트가 동시에 들어왔을 때 정확한 모션을 생성하는 것 (waving hand + walking)
- 이를 Spatial composition 을 통해서 해결하자!
- temporal composition
- 모션을 composition 하려는 기존 연구
- 한 액션부터 다른 액션까지의 transition을 구해서 사용
- 단순히 “transition”만 구하면 됨
- Spatial composition
- 각 액션이 몸의 어떤 부분에 속해있는지를 알아야함
- [왜?] 몸의 움직임을 동시에 표현하기 위함
- LLM이 해당 부분을 잘 encoding 할 수 있음
- 이러한 action-part 간의 관계를 GPT-3로부터 뽑아옴
- 이를 통해 두 가지의 모션을 하나의 모션으로 합칠 수 있음
- 이렇게 combine한 모션을 생성하여 training data로 사용함
- 각 액션이 몸의 어떤 부분에 속해있는지를 알아야함
1. Introduction
Fine-grained human motion generation
Text2Motion, 줄여서 T2M이라고 불리는 태스크는 최근 들어 아주 핫한 주제였다. MDM, MLD, FLAME과 같은 여러 SOTA 모델들이 제안되었는데, 이 모델들은 한 가지 문제점을 가지고 있다. 바로,
fine-grained human motion generation 의 성능이 떨어진다!
라는 것이다. fine-grained human motion generation은 이름에서 직관적으로 알 수 있듯이, motion을 생성할 때 좀 더 세밀한 부분까지 생성하는 것을 의미한다. 예를 들면, jumping down 이라는 모션을 생성 하고 싶은데, 이때 두 발은 허리 뒤에 놓으면서 뛰게 바꾸고 싶은 것이다. 그럼 우리는 with arms behind the back 이라는 구절을 붙일 수 있을 것이고, 좀 더 구체적으로 정보를 주기 위해서 while bending the knees 라는 구절까지 던져준다고 해보자. 그럼 모델은 손은 뒤로 하고 무릎은 굽히면서 뛰는 모션을 생성해야할 것이다.
설명이 길어졌는데, 여하튼 이렇게 동시에 두 액션이 들어왔을 때 이를 적절히 처리하는 것이 상당히 어렵다고 한다. 그래서 저자들은 Overview에서 언급하였듯이, Spatial composition 을 제안한다.
Composition in Time vs Space
사실 이렇게 모션을 합성한다는 아이디어가 처음 제안된 것은 아니다. 과거 TEACH 라는 논문에서는 시간적 차원에서 모션을 합성하기 위한 방법론을 제안하였다.
TEACH에서 제안한 Temporal composition은 단순히 각 시점에서 모션의'transition' 값을 구하여서 smooooooothly 하게, 즉 interpolation을 해주면 된다. 이는 다른 말로, 어떤 action에 대해서 이 body의 어떤 부분에 속하는지에 대한 지식인 action-specific knowledge를 이해할 필요가 없다는 것이다.
하지만 본 논문에서 제안한 Space 딴에서 composition을 수행하는 Spatial composition의 경우에는 이 knowledge를 정확하게 이해하고 있어야한다. 예를 들어 보면, waving과 walking이라는 모션을 합치고 싶을 때, 우리는 각각의 모션이 어느 body의 어느 파트에 속하였는지를 알아야지 두 모션을 합칠 수 있다. 즉, waving은 손, 팔에 포함된 모션, walking은 다리에 포함된 모션이므로, 상하체를 적절히 잘라 합성하면 하나의 모션으로 만들 수 있게 된다. 아래의 사진을 보면 확실하게 이해할 수 있을 것이다.

자 그러면 어떻게 한 모션이 body의 어느 부분에 속한 모션인지 알 수 있을까? 저자들은 이 과정에서 GPT-3를 사용한다. 더불어 이렇게 composition 된 데이터를 추가적인 학습 데이터로 사용하여 데이터를 더 풍부하게 만든다. 그리고 그렇게 만들어진 데이터로 학습을 시킨 모델을 SINC 라고 명명했다.
자, 그럼 이제 구체적인 방법을 알아보자!
2. Method
본 논문에서 제안하는 방법은 크게 2 stage로 구성되어있다. 바로 GPT 기반으로 만들어진 training data를 생성하는 것과 실제로 spatial composition 된 모션을 생성하는 것이다. 하나씩 살펴보자!
- GPT-guided synthetic training data creation
모션을 합성하기 위해서는 우선 해당 모션이 body의 어느 부분에 속해 있는지 알아야 한다. Introduction에서 언급했듯이, 이 과정에서 GPT-3를 사용한다. 사용 방법은 단순히 GPT에게 <이 모션은 신체 중 어떤 부분에 속한 모션이니 ?> 라고 물어보는 것이다. 본 논문에서는 크게 3가지의 방법으로 실험을 진행한다. 다음 그림은 appendix A에 제공되어 있다.


- Free-form (line 40 ~ 41)
: 2번 방법에서 list를 제외한 것
- Choosing from a list (line 1~11 + line 40~41)
: "Choose answers from the list < list of body part > " 를 통해 GPT가 part를 고르도록 함 (이때 list는 [left arm, right arm, left leg, right leg, torso, neck, buttocks, waist]로 구성됨)
- Choosing from a list + Few-shot examples (all lines)
: 2번 방법에서 몇 가지의 질문-대답 예시를 추가로 제시한 것
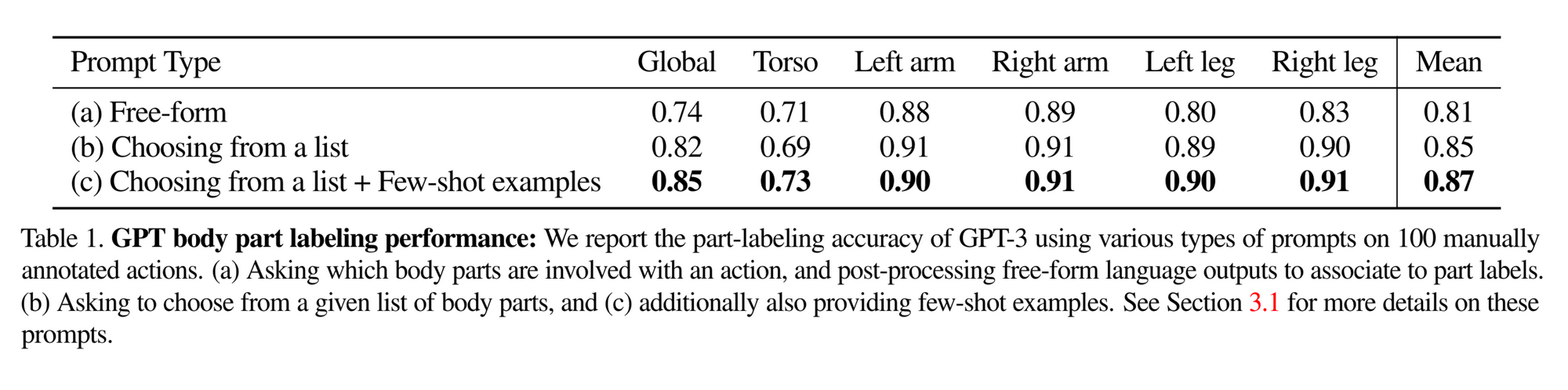
저자들은 세 방법들을 아래와 같은 평가 방법으로 순위를 매겨 GPT 기반의 action-specific knowledge를 추출하려했다. 위의 결과를 보면 Choosing from a list + Few-shot examples, 즉 3번 방법의 정확도가 가장 높았다.
정확도의 경우, quantitative metrics를 사용했다. BABEL 데이터에서 100개의 action description을 뽑는다. 즉 여러 가지 action을 뽑아주는 것이다. 그 후 GPT로 위의 세 가지 방법을 통해 body part를 뽑아낸다. 그리고 이를 yes/no/sometimes 로 GPT의 답변에 대한 체크를 해준다. 그리고 yes/no/sometimes 를 1/0/0.5을 통해 점수화를 해준다.
각 방법들에 대한 좀 더 디테일한 분석도 있다. Free-form과 Choosing from a list를 비교해보았을 때, 전자의 경우 상당히 상세하게 (삼두근 등) 답변을 하여 후처리를 해주어야 하는 번거로움이 존재했다고 한다. 그에 반해 후자는 이러한 후처리가 없을 뿐더러, 특히나 오른쪽/왼쪽, 그리고 팔/다리에 대한 라벨링 정확도가 올라갔다고 언급했다.
자, 그럼 이제 GPT를 통해 어떤 식으로 body part를 라벨링 해야할지 알게 되었으니, 두 모션을 합쳐서 새로운 모션을 만드는 단계로 넘어가자.
우선, 모선을 합치기 위해서는 주어진 모션들이 compatible, 즉 합쳐질 수 있는 모션인지를 확인해야 한다. 예를 들어, walking과 kicking with the right leg는 둘 다 다리를 사용하는 모션이기 때문에 합쳐질 수 없는 모션이다. 이런 부분들을 어떻게 처리할까?
모션이 합쳐지는 과정은 다음과 같다.
- 모션 A와 B가 주어진다.
- 모션의 길이를 맞춰준다. (더 짧은 모션 길이를 기준으로!)
- 모션 A보다 모션 B가 훨씬 더 적은 body part를 사용하도록 선택한다.
- 모션 A: global motion (walking, sitting)
- 모션 B: local motion (waving the right hand)
- 그런데, 만약 모션 B가 최소 1개의 다리나 global orientation을 포함하고 있다면, 모션 B에서 두 다리의 값, global orientation, translation을 선택한다. (만약 모션 B가 하체나 신체의 전반적인 부분을 담당하고 있지 않다면 모션 A에서 4개의 값을 가져오도록 함)
- 나머지 translation은 A에서 가져온다.
- 마지막으로, composited motion은 세 번째 과정에 의해 얻어진 translation에 따라 A와 B를 합성한다.
이와 같은 과정을 통해 저자들은 composited한 모션을 얻을 수 있다고 말하고 있다. 그럼 이제, spatial composition 모션을 어떻게 생성하는지 알아보자.
- Learning to generate spatial compositions

모델의 전반적인 아키텍처는 위와 같으며 TEMOS와 유사하다.
먼저 text encoder 는 'while', 'at the same time', 'simultaneously', 'during' 등을 이용하여 하나의 문장으로 만들어진 문장을 입력받는다. 그리고 single latent vector인 와 distribution 를 output으로 가진다.
motion encoder 의 경우 motion sequence 를 받는다. 그리고 text encoder처럼 single latent vector 와 distribution 를 output으로 가진다.
마지막으로 motion decoder 의 input은 motion의 length들이 positional encoding 되어 사용된다. 처음에는 뭘 positional encoding을 하는 거지 ...? 싶었는데, 코드를 보니 이해가 되었다.
def forward(self, text_pairs, lens):
# texts = batch["text"]
# lengths = batch["length"]
lengths = lens
texts = [" while ".join(x) for x in text_pairs]
if self.stage in ['diffusion', 'vae_diffusion']:
# diffusion reverse
if self.do_classifier_free_guidance:
uncond_tokens = [""] * len(texts)
if self.condition == 'text':
uncond_tokens.extend(texts)
elif self.condition == 'text_uncond':
uncond_tokens.extend(uncond_tokens)
texts = uncond_tokens
text_emb = self.text_encoder.get_last_hidden_state(texts)
z = self._diffusion_reverse(text_emb, lengths)
elif self.stage in ['vae']:
motions = batch['motion']
z, dist_m = self.vae.encode(motions, lengths)
with torch.no_grad():
# ToDo change mcross actor to same api
if self.vae_type in ["mld","actor"]:
feats_rst = self.vae_decoder(z, lengths)
elif self.vae_type == "no":
feats_rst = z.permute(1, 0, 2)
rotations_datastruct = self.transforms.rots2rfeats.inverse(feats_rst.detach().cpu())
# from sinc.render import render_animation
# self.transforms.rots2joints.jointstype = 'smplh'
# joints = self.transforms.rots2joints(rotations)
# import ipdb; ipdb.set_trace()
# render_animation(joints, output='./some_anim.mp4', title='what', fps=30)
return rotations_datastruct
#return remove_padding(joints, lengths)official code 코드에서 확인할 수 있는데, 상단의 코드는 model의 forward 코드이다. 아래쪽에 vae_decoder를 사용하여 모션을 얻는데, 저때 일단 sampling latent vector z를 받고, 그 옆에 lengths를 추가로 받는 걸 알 수 있다. 저 decoder 코드를 보면,
def forward(self, z: Tensor, lengths: List[int], mem_masks=None):
mask = lengths_to_mask(lengths, z.device)
latent_dim = z.shape[-1]
bs, nframes = mask.shape
nfeats = self.hparams.nfeats
# z = z[:, None] # sequence of 1 element for the memory
# separate latents
# torch.cat((z0[:, None], z1[:, None]), 1)
if len(z.shape) > 3:
z = rearrange(z, "bs nz z_len latent_dim -> (nz z_len) bs latent_dim")
else:
z = rearrange(z, "bs z_len latent_dim -> z_len bs latent_dim")
# Construct time queries
time_queries = torch.zeros(nframes, bs, latent_dim, device=z.device)
time_queries = self.sequence_pos_encoding(time_queries)
# Pass through the transformer decoder
# with the latent vector for memory
if mem_masks is not None:
mem_masks = ~mem_masks
output = self.seqTransDecoder(tgt=time_queries, memory=z,
tgt_key_padding_mask=~mask,
memory_key_padding_mask=mem_masks)
output = self.final_layer(output)
# zero for padded area
output[~mask.T] = 0
# Pytorch Transformer: [Sequence, Batch size, ...]
feats = output.permute(1, 0, 2)
return featslengths 값을 받아 masking 하는 것을 알 수 있다. 즉 length의 dimension만큼 time_queries를 만들고 이를 positional encoding 하여 masking input (원래 우리가 알고 있는 Transformer decoder input) 으로 사용하는 것이다. 그리고 Output은 바로 motion!
Loss를 정리해보면 다음과 같다.
- =
- =
- =
- =
3. Experiment
우선 이 논문에서 사용한 주요 데이터는 BABEL이다. BABEL에 대한 설명은 짧으니 논문 참고!
다음으로 evalation metric을 살펴보면, Visual quality와 Semantic correspondence의 두가지 측면에서 분석하려고 했다. 먼저 Visual quality의 경우 APE (Average Positional Error), AVE (Average Variational Error)을 통해 판단한다.
Semantic correspondence는 TEMOS score을 사용하는데 이 metric은 본 논문에서 제안한 metric으로, TEMOS의 motion encoder를 일종의 feature extractor로 보고, generated motion과 ground truth의 embedding vector를 cosine similarity 계산한 것이다.
실험 부분에서는 크게 Baseline comparison과 Contribution of the synthetic data로 나눌 수 있다. 먼저 Baseline comparison부터 살펴보자.
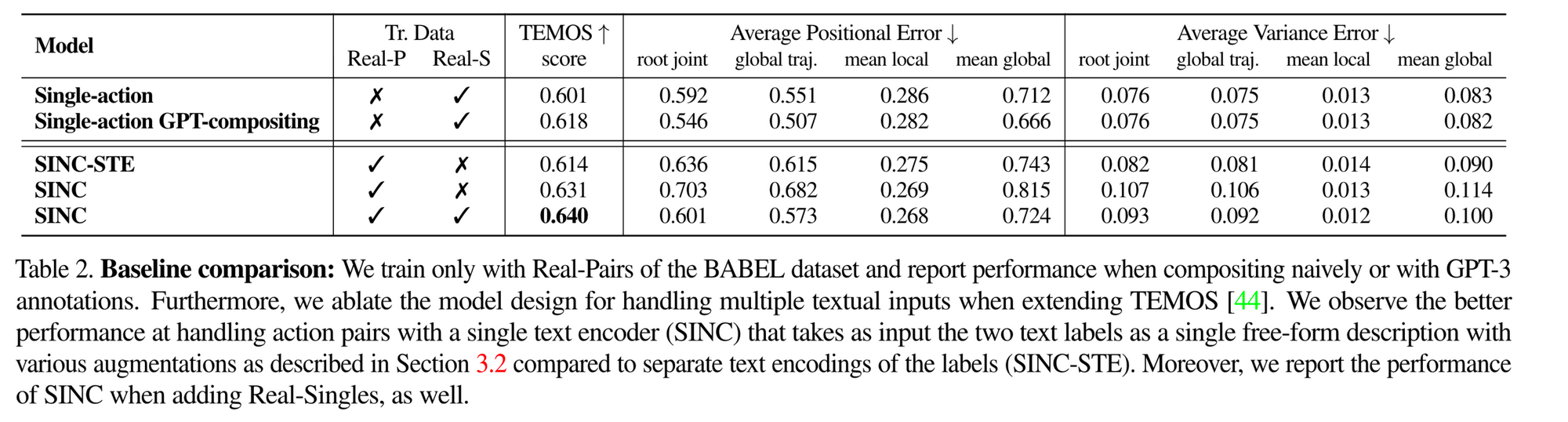
일단 상단의 Single-action, Single-action GPT-compositing을 다뤄보면, Single-action model의 경우, 한 개의 real single action으로 simultaneous motion을 생성할 수 있는지를 실험한 것이다. 그리고 Single-action GPT-compositing은 일단 먼저, 두 개의 text가 주어지면 각각, 두개의 독립적인 모션을 생성한다. 그리고 GPT-guided composition 방법을 통해 합성한다. 실제로 모션을 합성 시킬 때는 연결구 (while, at the same time 등) 를 통해 하나의 문장이 들어와서 생성한다면, 이 방법은 각각 따로! 들어온다는 것이 가장 큰 차이점이다. 이 방법의 단점은 test 시에 GPT가 필요한 것, 그리고 공통 body part에 대한 레이블을 해결하는데 잦은 오류가 발생한다는 것으로 정리할 수 있다.
다음으로 하단을 살펴보자. 하단은 input text format의 효과를 알아보는 실험으로 볼 수 있는데, 일단 먼저 기억하고 가야할 것은 SINC의 경우 while 등의 단어를 통해 두 문장을 묶어서 input으로 제공한다는 점이다. 그럼 첫 번째 SINC-STE는 무엇일까?
SINC-STE는 상단에서 실험했던 부분을 보완하여, 독립적으로 text를 encoding 후 그 사이에 학습 가능한 토큰으로 이를 연결하는 방법이다. 표에 나와있듯이, SINC는 입력을 좀 더 유연하게 주어야 효과가 좋다는 것을 알 수 있다.
그럼 이 논문의 마지막이라고 볼 수 있는, Training with different sets of data로 넘어가보자.
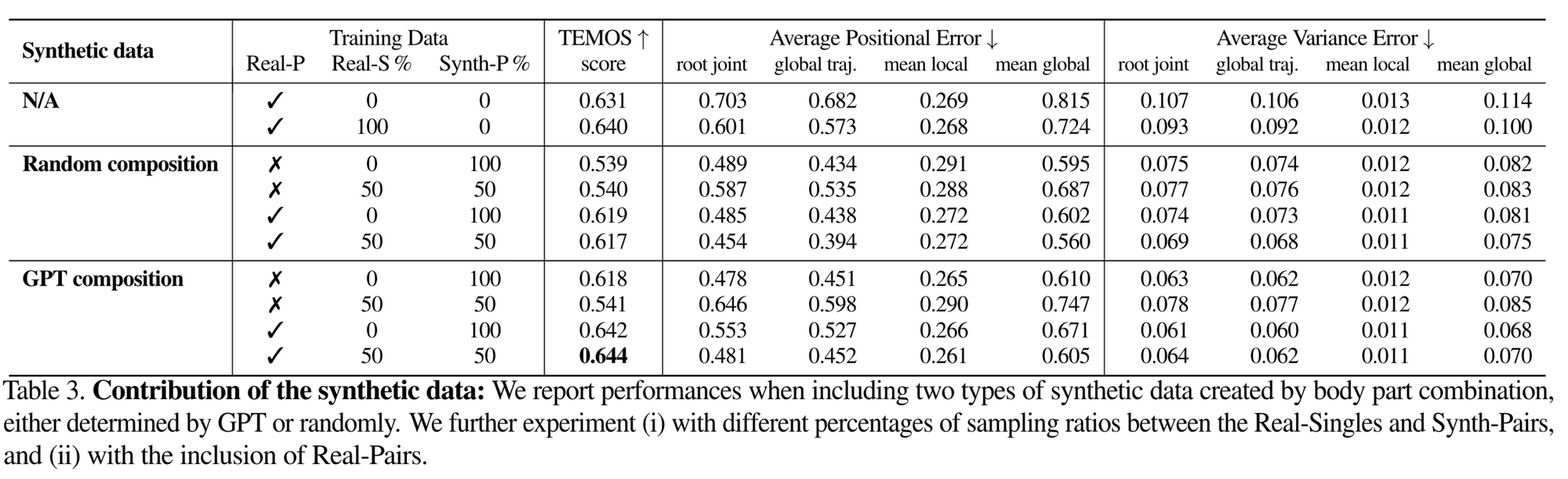
표 3의 %는 real-single action 들이 다른 action과 합성된 확률을 의미한다. 모든 데이터를 썼을 때 (Real-P 100%, Real-S 50%, Synth-P 50%)이 가장 높은 TEMOS score를 보여줬다. 이에 더불어 GPT guidance를 비롯한 다양한 composition 방법을 수행했었는데, 이때에 GPT composition이 가장 높은 성능을 보여주었다.
4. Conclusion
논문의 Limitation과 Contribution은 다음과 같이 정리할 수 있다.
- Limitation
- body part 가 compatible 하더라도 모든 action이 simultaneously together 되지 않음
- walking 과 같은 애매한 모션일 경우 정확한 action-part knowledge를 얻을 수 없음
- Contribution
- 3D human motion을 위한 spatial composition task의 new benchmark 제안
- new evaluation metric 제안
- GPT-guided 데이터 생성 방법 제안
- BABEL dataset의 추가적인 학습 데이터셋 제안
간만의 논문 리뷰 ... 읽고 노션에 정리하고, 다시 블로그에 정제해서 정리하고 ...
쉽지 않았다 ^^ ...
앞으로 일주일에 1회 업로드를 목표로 하고 있는데,
잘 할 수 있겠지? 허허허
