☄️ 이 글은 유튜브 나도코딩의 영상 / 한동대학교 이상산 교수님의 수업을 기반으로 쓰여졌습니다!
다항 회귀
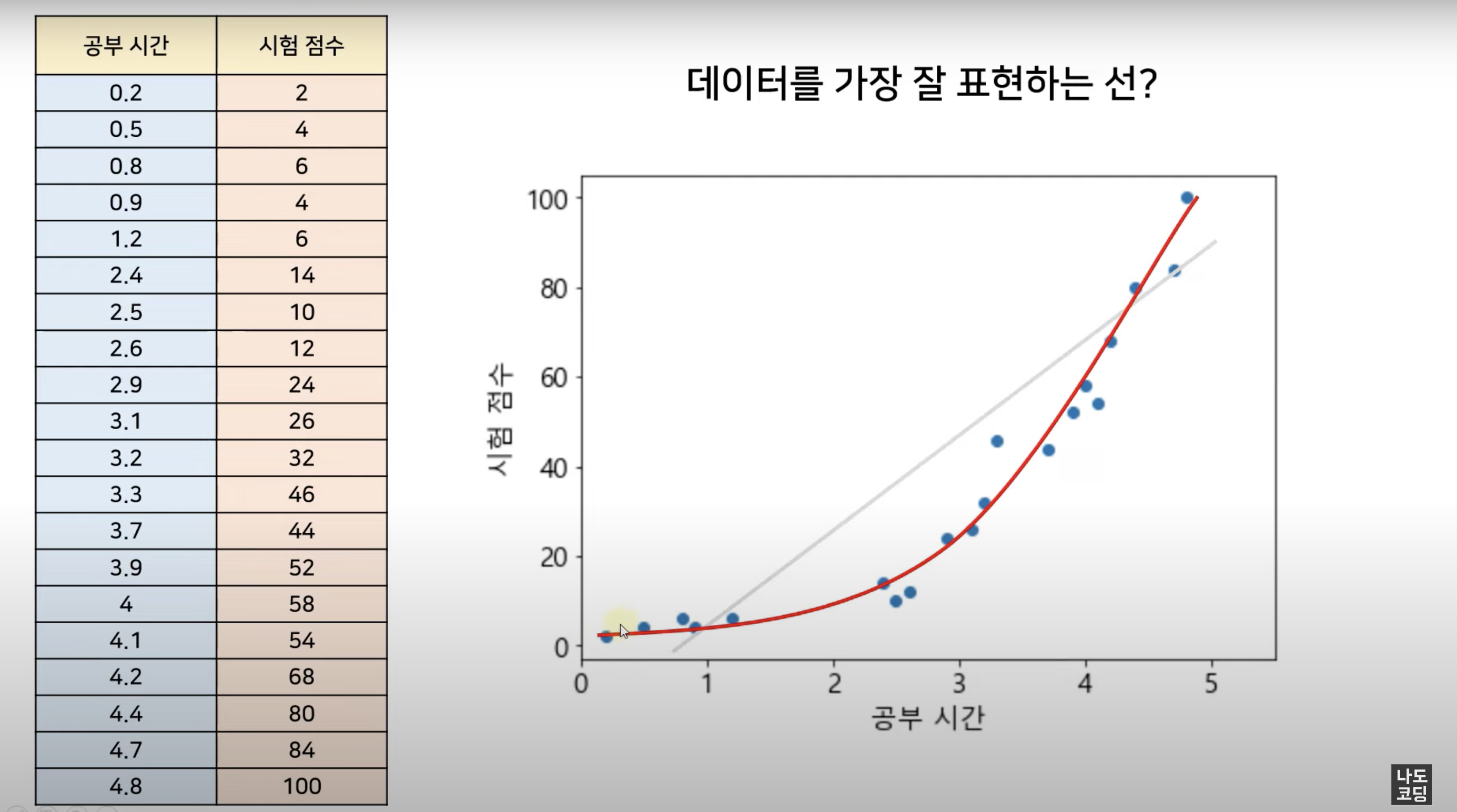
지난 시간에 살펴본 선형회귀는 분석하고자 하는 데이터의 설명변수(X)와 응답변수(y)가 선형적인 관계, 즉 일자 선으로 설명하기에 충분했습니다.
하지만 데이터의 변수들이 곡선으로 이루어져 있으면 어떡할까요?
이럴 경우에 선형회귀를 사용하게 되면 오차가 발생할 것입니다.
이때, 데이터 분포에 따라 적합한 곡선형태로 접근하면 훨씬 오차가 적습니다.
하나의 독립변수 x를 쓰면서 변수의 제곱, 세 제곱, n 제곱까지의 상태를 쓰는..
즉, 2차원 곡선 형태는 2차원 곡선으로, 3차원 곡선 형태는 3차원 곡선으로 말입니다.
데이터의 feature 독립변수 x를 확장하는 개념인 것이죠.
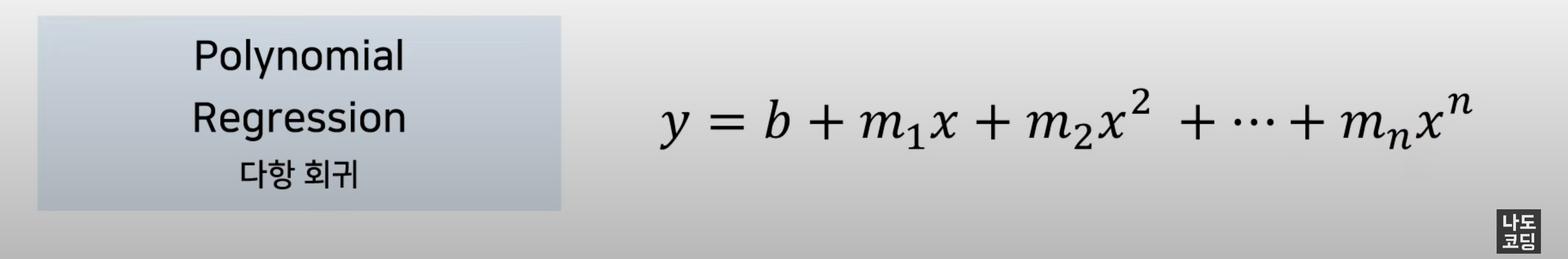
실습1. 공부시간에 따른 시험 점수를 예측해 보아요! 🔥
- 다항 회귀에 필요한 라이브러리를 임포트 하고, X, y의 범위를 지정해 줍니다.
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
dataset = pd.read_csv('PolynomialRegressionData.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:,-1].values- 데이터가 어떻게 구성되어 있는지 위에서부터 5개만 볼게요.
dataset.head()- 객체를 생성해 주고, 2차 다항식으로 지정해 줍니다.
poly_reg = PolynomialFeatures(degree=2)
X_poly = poly_reg.fit_transform(X) # X의 feature 변환
X_poly[:5] # [x] -> [x^0, x^1, x^2] -> x가 3이라면 [1, 3, 9]로 변환array([[1. , 0.2 , 0.04],
[1. , 0.5 , 0.25],
[1. , 0.8 , 0.64],
[1. , 0.9 , 0.81],
[1. , 1.2 , 1.44]])
- 변환된 X 와 y 를 가지고 모델을 생성 (학습)합니다.
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y) - 데이터 시각화를 해줍니다.
plt.scatter(X, y, color = 'blue')
plt.plot(X, lin_reg.predict(poly_reg.fit_transform(X)), color = 'green')
plt.title('score by hours (test data)') # 제목
plt.xlabel('hours') # X 축 이름
plt.ylabel('score') # y 축 이름
plt.show()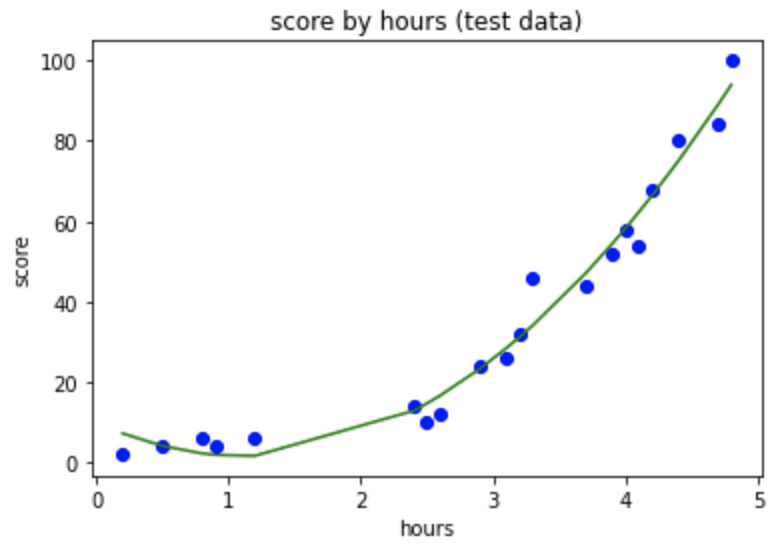
네. 선형회귀를 했을 때 보다 굴곡이 있죠?
그런데 좀 각진 부분이 있네요.
부드럽게 바꾸어 볼게요.
- 스무스한 곡선을 만들어요.
import numpy as np
X_range = np.arange(min(X), max(X), 0.1) # X의 최소값에서 최대값까지의 범위를 0.1 단위로 잘라서 데이터를 생성
X_range- 1차원 배열을 2차원 배열로 바꿔줘야 해요.
X_range.shape # 1차원 배열(46,)
X[:5] # 얘는 2차원 배열array([[0.2],
[0.5],
[0.8],
[0.9],
[1.2]])
X_range = X_range.reshape(-1, 1) # row 개수는 자동으로 계산, column # 2차원으로 바꿨어요!
X_range.shape(46, 1)
X_range[:5]array([[0.2],
[0.3],
[0.4],
[0.5],
[0.6]])
- 데이터를 시각화 해보아요.
plt.scatter(X, y, color = 'blue')
plt.plot(X_range, lin_reg.predict(poly_reg.fit_transform(X_range)), color = 'green')
plt.title('score by hours (test data)') # 제목
plt.xlabel('hours') # X 축 이름
plt.ylabel('score') # y 축 이름
plt.show()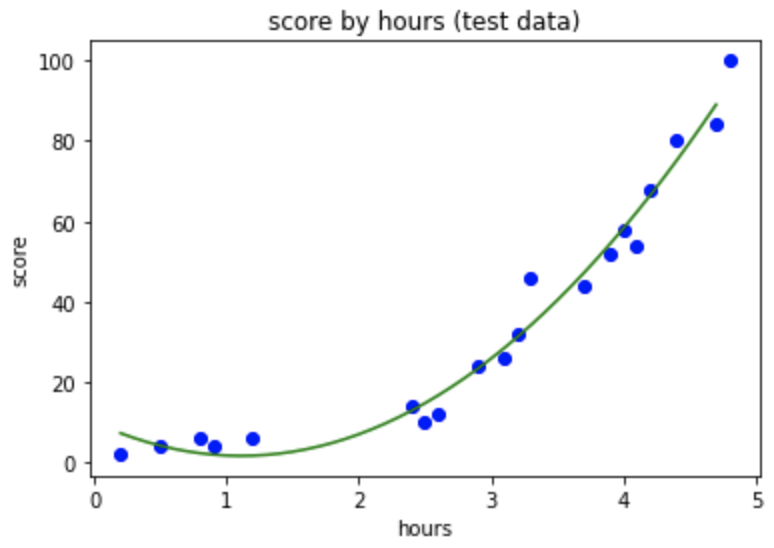
이제 공부 시간에 따른 시험 성적 예측을 해봅시다.
- 2시간을 공부했을 때 선형 회귀 모델의 예측을 해보아요.
reg.predict([[2]]) # 2시간을 공부했을 때 선형 회귀 모델의 예측 # 2차원 배열의 형태로 #19.8점- 과연 점수는?
lin_reg.score(X_poly,y)0.9755457185555199

배낭여행자 도로시, 주변을 살피며 걷는 중입니다. (소개글을 참고해 주세요 찡긋)