☄️ 이 글은 유튜브 나도코딩의 영상 / 한동대학교 이상산 교수님의 수업을 기반으로 쓰여졌습니다!
분류 Classification
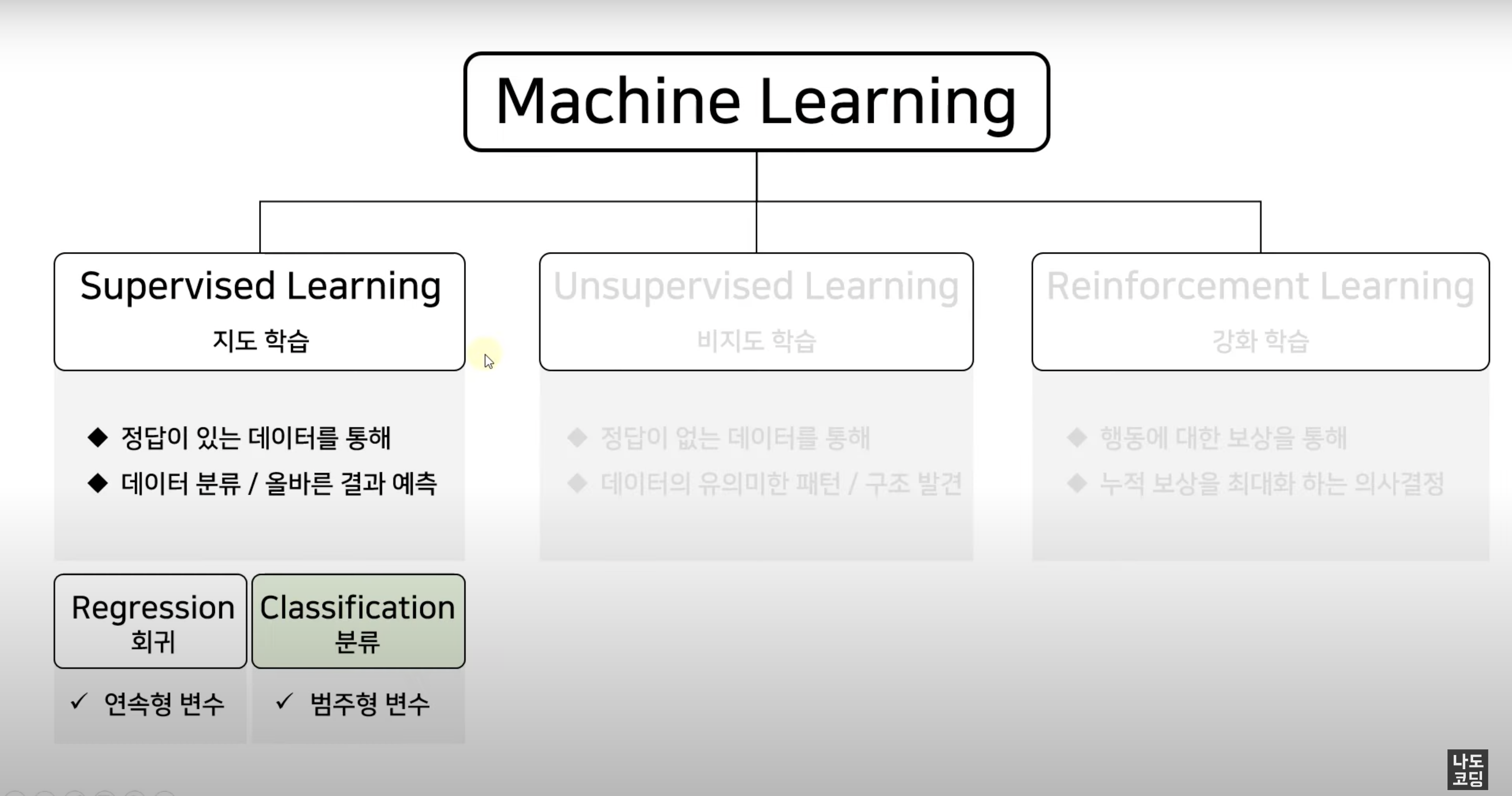
분류는 주어진 데이터를 정해진 범주 (category)에 따라 분류하는 것이에요.
주로 예측 결과가 숫자가 아닐 때 사용하죠.
로지스틱 회귀 Logistic Regression
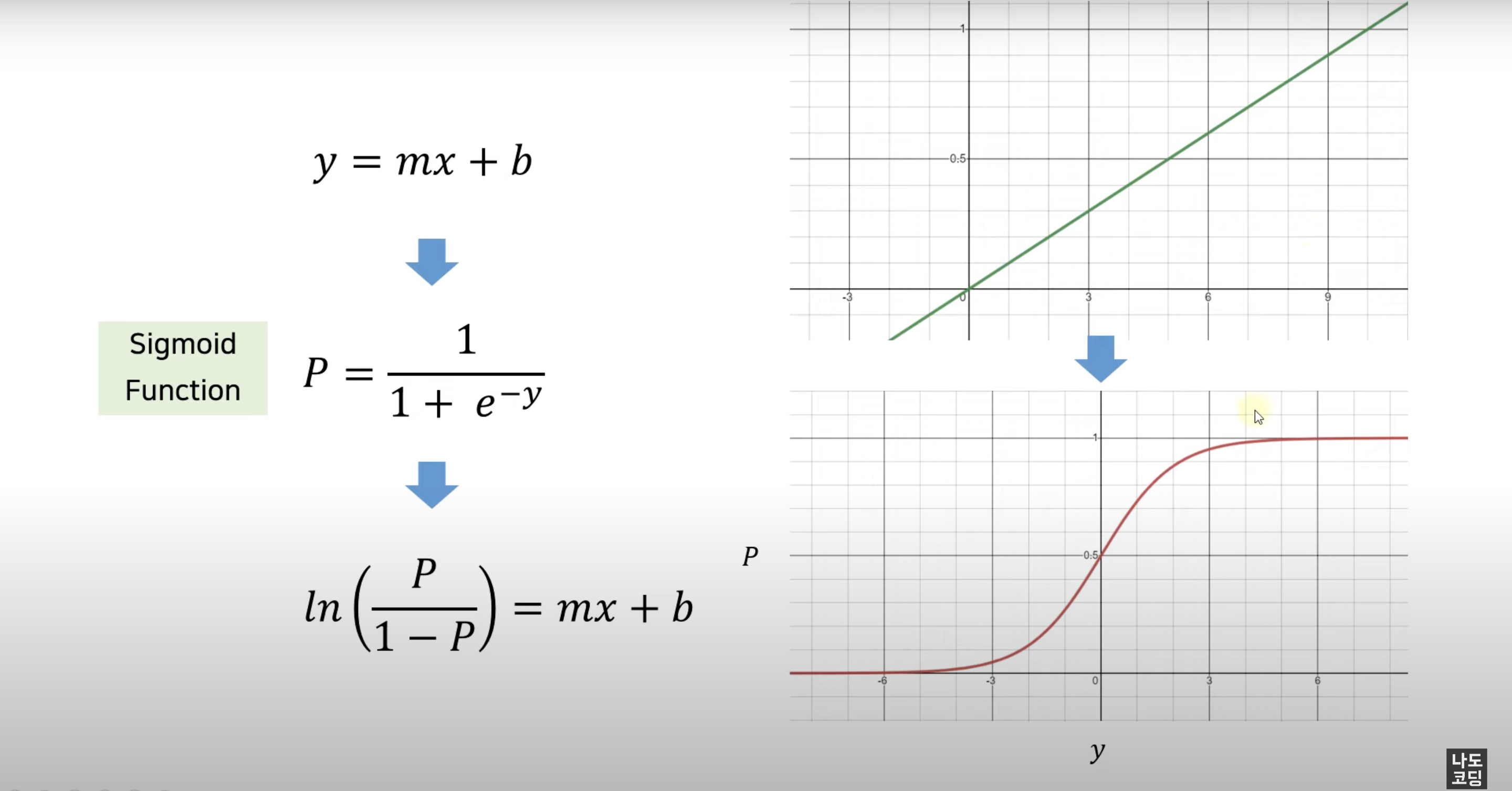
선형 회귀 방식을 분류에 적용한 알고리즘, 데이터가 어떤 범주에 속할 확률을 0~1 사이의 값으로 예측, 더 높은 범주에 속하는 쪽으로 분류합니다.
즉, 0보다 작은 값들은 0으로 1보다 큰 값들은 1로 보는 것이죠.
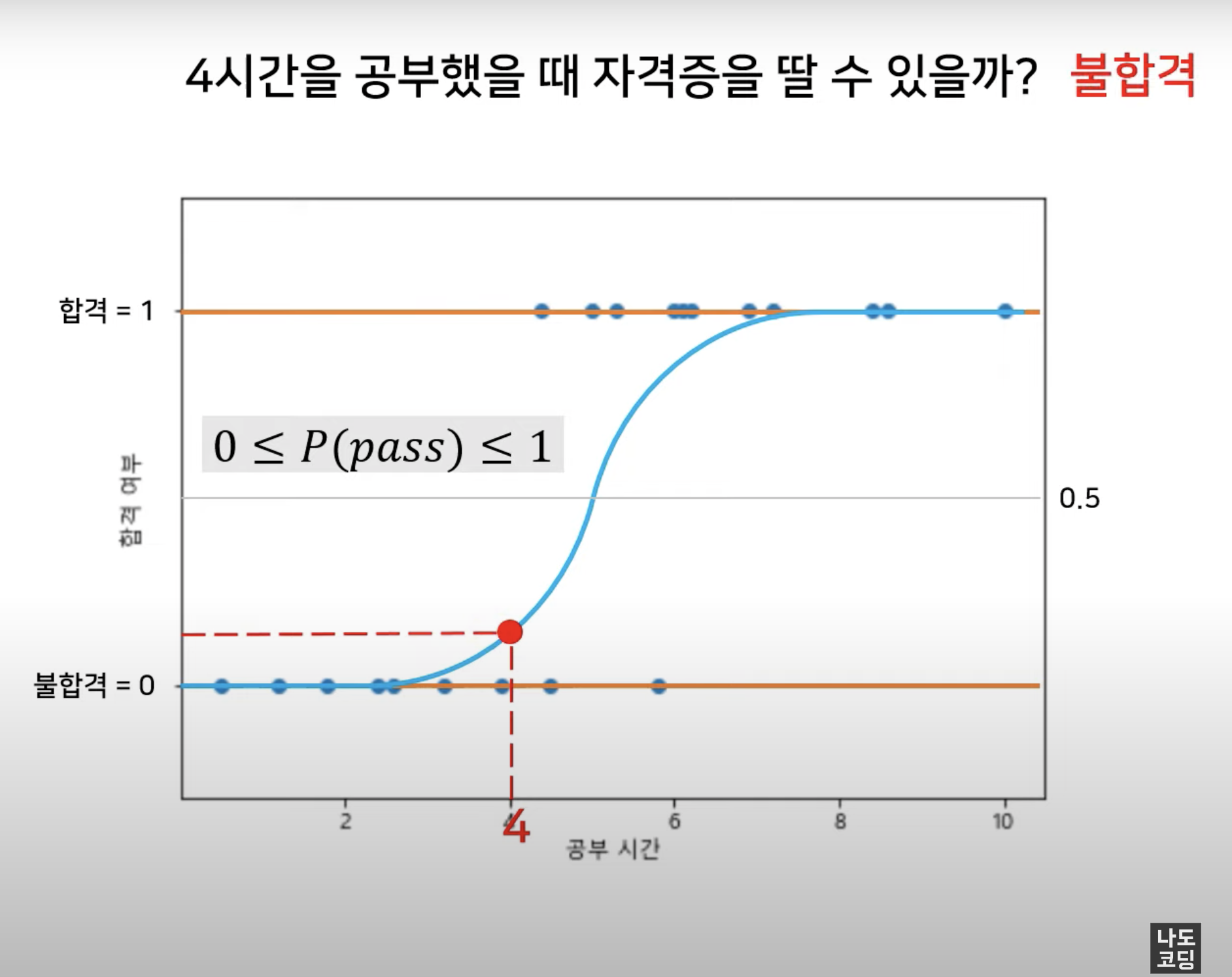
범주: True / False, Yes / No, 합격 / 불합격, ...
예) 스팸 메일, 은행 대출, 악성 여부, 고객의 제품 구매 의사, ...
공부시간에 따른 합격 / 불합격 여부를 예측하는 실습을 해볼게요.
- 로지스틱에 필요한 라이브러리를 임포트 할게요.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression- 데이터를 불러오고, X와 y를 정해줍니다.
dt = pd.read_csv('LogisticRegressionData.csv')
X = dt.iloc[:, :-1].values
y = dt.iloc[:, -1].values- train 과 test로 데이터를 분리해 줍니다.
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2, random_state=0)- 학습시켜 줍니다.
classifier = LogisticRegression()
classifier.fit(X_train, y_train)- 6시간 공부했을 때 과연 합격할까요? 불합격 할까요?
classifier.predict([[6]])
# 결과 1 : 합격할 것으로 예측array([1])
6. 합격 / 불합격 확률을 알아볼게요.
classifier.predict_proba([[6]]) # 합격할 확률 출력
# 불합격할 확률 14%, 합격할 확률 85%array([[0.14150735, 0.85849265]])
- 테스트 세트를 통해 분류 결과를 예측해 봅시다.
y_pred = classifier.predict(X_test)
y_pred # 예측 값array([1, 0, 1, 1])
y_test # 실제 값 (테스트 세트) => 예측 4개 중 하나 틀림array([1, 0, 1, 0])
8. 이 모델의 점수는
classifier.score(X_test, y_test) # 점수 # 전체데이터세트 중에서 올바르게 분류한게 몇 개가 되는지 점수로 반영 된다는 점 회귀하고 다름 0.75
75점!
- 데이터 시각화를 위해 작업 시작!
import numpy as np
X_range = np.arange(min(X), max(X), 0.1) # X의 최솟값에서 최대값까지를 0.1단위로 잘라서 데이터 생성
X_rangearray([0.5, 0.6, 0.7, 0.8, 0.9, 1. , 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7,
1.8, 1.9, 2. , 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9, 3. ,
3.1, 3.2, 3.3, 3.4, 3.5, 3.6, 3.7, 3.8, 3.9, 4. , 4.1, 4.2, 4.3,
4.4, 4.5, 4.6, 4.7, 4.8, 4.9, 5. , 5.1, 5.2, 5.3, 5.4, 5.5, 5.6,
5.7, 5.8, 5.9, 6. , 6.1, 6.2, 6.3, 6.4, 6.5, 6.6, 6.7, 6.8, 6.9,
7. , 7.1, 7.2, 7.3, 7.4, 7.5, 7.6, 7.7, 7.8, 7.9, 8. , 8.1, 8.2,
8.3, 8.4, 8.5, 8.6, 8.7, 8.8, 8.9, 9. , 9.1, 9.2, 9.3, 9.4, 9.5,
9.6, 9.7, 9.8, 9.9])
- 로지스틱 회귀 선을 표현해 주기 위해서는 X에 대한 y값도 수식에 대입을 해서 결과를 미리 만들어 놓아야 해요.
p = 1 / (1 + np.exp(-(classifier.coef_ * X_range + classifier.intercept_))) # y = mx + b
parray([[0.01035705, 0.01161247, 0.01301807, 0.0145913 , 0.01635149,
0.01832008, 0.02052073, 0.02297953, 0.02572521, 0.02878929,
0.03220626, 0.03601375, 0.04025264, 0.04496719, 0.05020505,
0.05601722, 0.06245802, 0.06958479, 0.07745757, 0.08613861,
0.09569165, 0.10618106, 0.11767067, 0.13022241, 0.14389468,
0.15874043, 0.17480509, 0.19212422, 0.2107211 , 0.23060425,
0.25176509, 0.27417574, 0.29778732, 0.32252874, 0.34830616,
0.3750034 , 0.40248315, 0.43058927, 0.45914989, 0.48798142,
0.51689314, 0.54569221, 0.57418876, 0.60220088, 0.6295591 ,
0.65611024, 0.68172044, 0.70627722, 0.72969059, 0.75189324,
0.77283994, 0.79250621, 0.81088652, 0.82799203, 0.84384828,
0.85849265, 0.871972 , 0.88434036, 0.89565683, 0.90598377,
0.91538521, 0.92392546, 0.93166808, 0.93867499, 0.9450058 ,
0.95071738, 0.95586346, 0.96049453, 0.96465764, 0.96839647,
0.97175136, 0.97475939, 0.97745455, 0.97986786, 0.9820276 ,
0.98395944, 0.98568665, 0.9872303 , 0.98860939, 0.98984107,
0.9909408 , 0.99192244, 0.99279849, 0.99358014, 0.99427745,
0.9948994 , 0.99545406, 0.99594865, 0.99638963, 0.99678276,
0.99713321, 0.99744558, 0.997724 , 0.99797213, 0.99819325]])
- 1차원 형태로 변경
p = p.reshape(-1)
p.shape- train 모델 결과를 시각화 해보아요.
plt.scatter(X_train, y_train, color='blue')
plt.plot(X_range, p, color='green')
plt.plot(X_range, np.full(len(X_range), 0.5), color='red') # X_range 개수만큼 가득찬 배열 만들기
plt.title('Probability by hours')
plt.xlabel('hours')
plt.ylabel('P')
plt.show()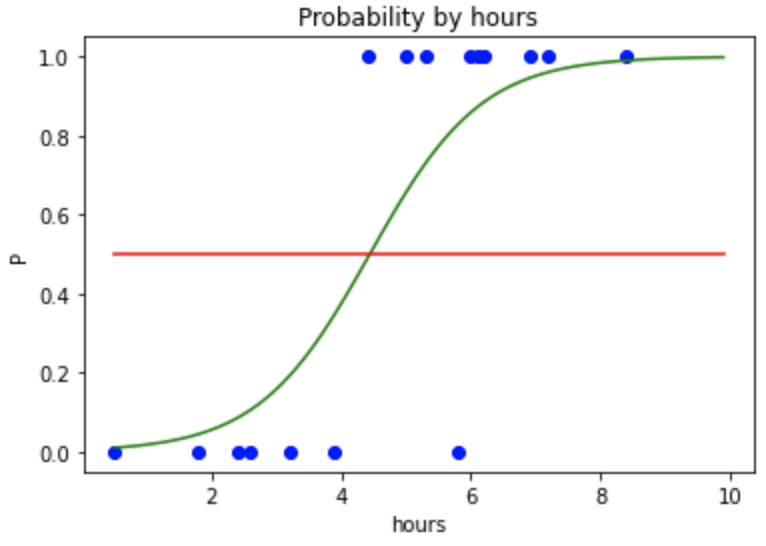
13. 이번엔 test!
plt.scatter(X_test, y_test, color='blue')
plt.plot(X_range, p, color='green')
plt.plot(X_range, np.full(len(X_range), 0.5), color='red') # X_range 개수만큼 가득찬 배열 만들기
plt.title('Probability by hours(test)')
plt.xlabel('hours')
plt.ylabel('P')
plt.show()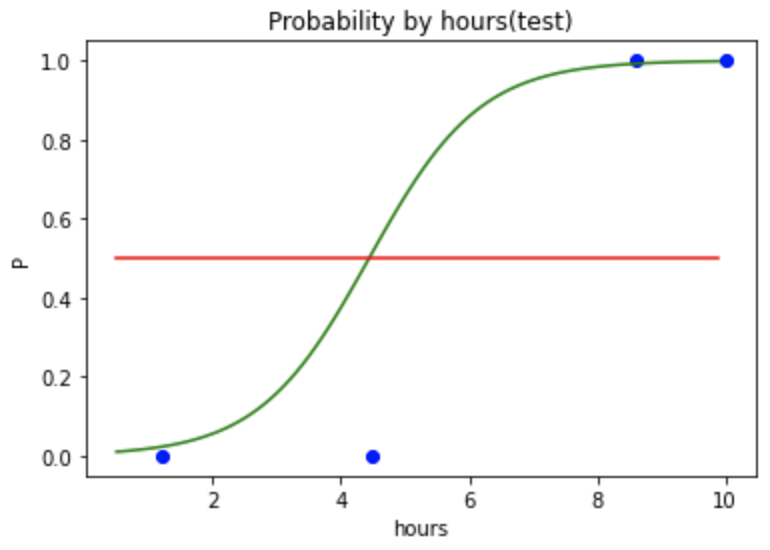
14. 4.5시간을 공부했을 때 합격 / 불합격 확률은?
classifier.predict_proba([[4.5]]) # 4.5시간 공부했을 때 확률 (모델에서는 51% 확률로 합격 예측, 실제로는 불합격)
# 불합격에 해당하는 48%, 합격에 해당하는 51%array([[0.48310686, 0.51689314]])
