☄️ 이 글은 유튜브 나도코딩의 영상 / 한동대학교 이상산 교수님의 수업을 기반으로 쓰여졌습니다!
지도 학습이란?
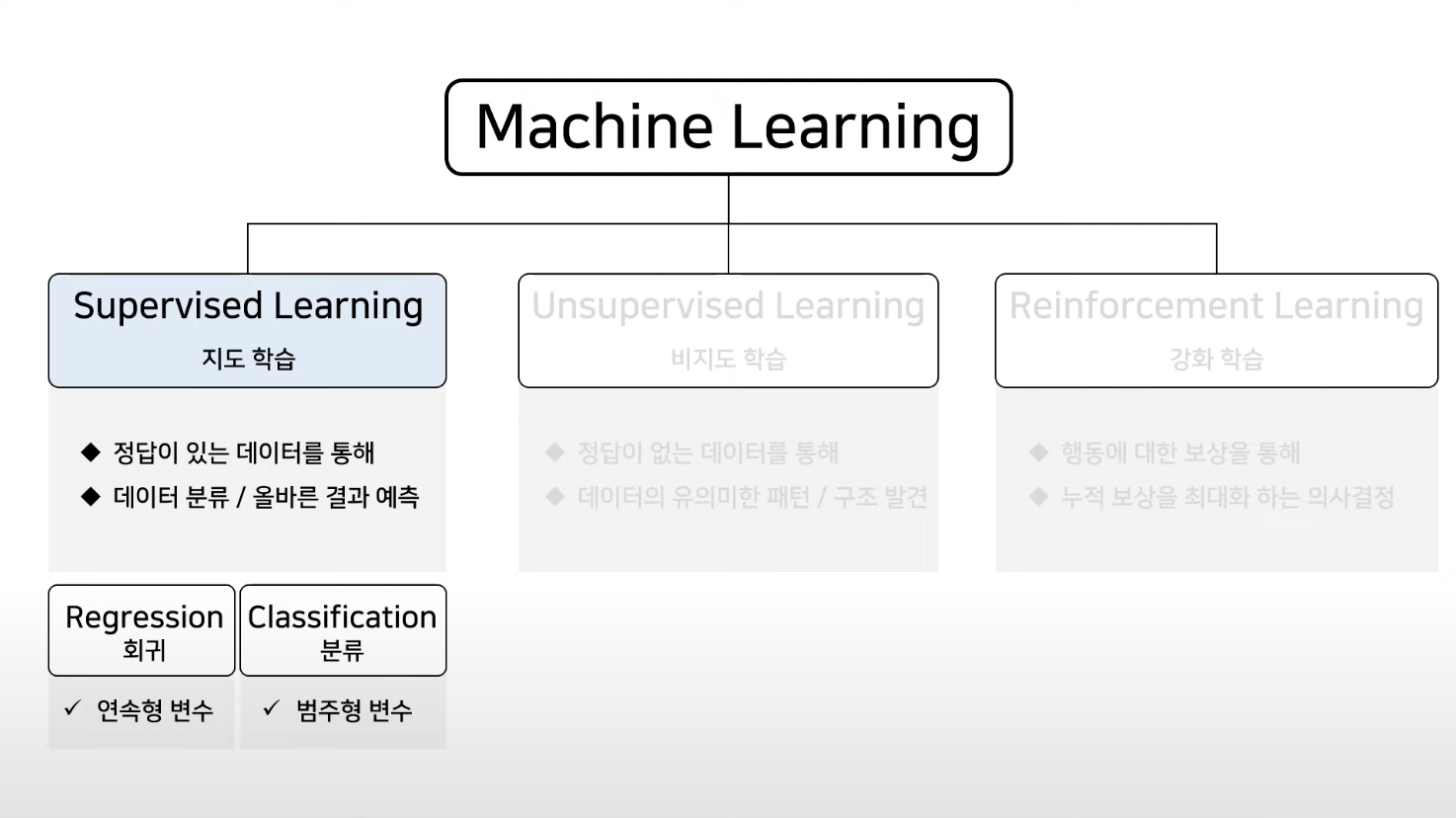
예측 또는 결정을 내리기 위해 레이블이 지정된 데이터에 대해 알고리즘을 훈련하는 기계 학습 기술이에요. 목표는 훈련 세트에 제공된 예제를 기반으로 입력을 출력에 매핑하는 기능을 학습하는 것이죠.
지도 학습의 유형
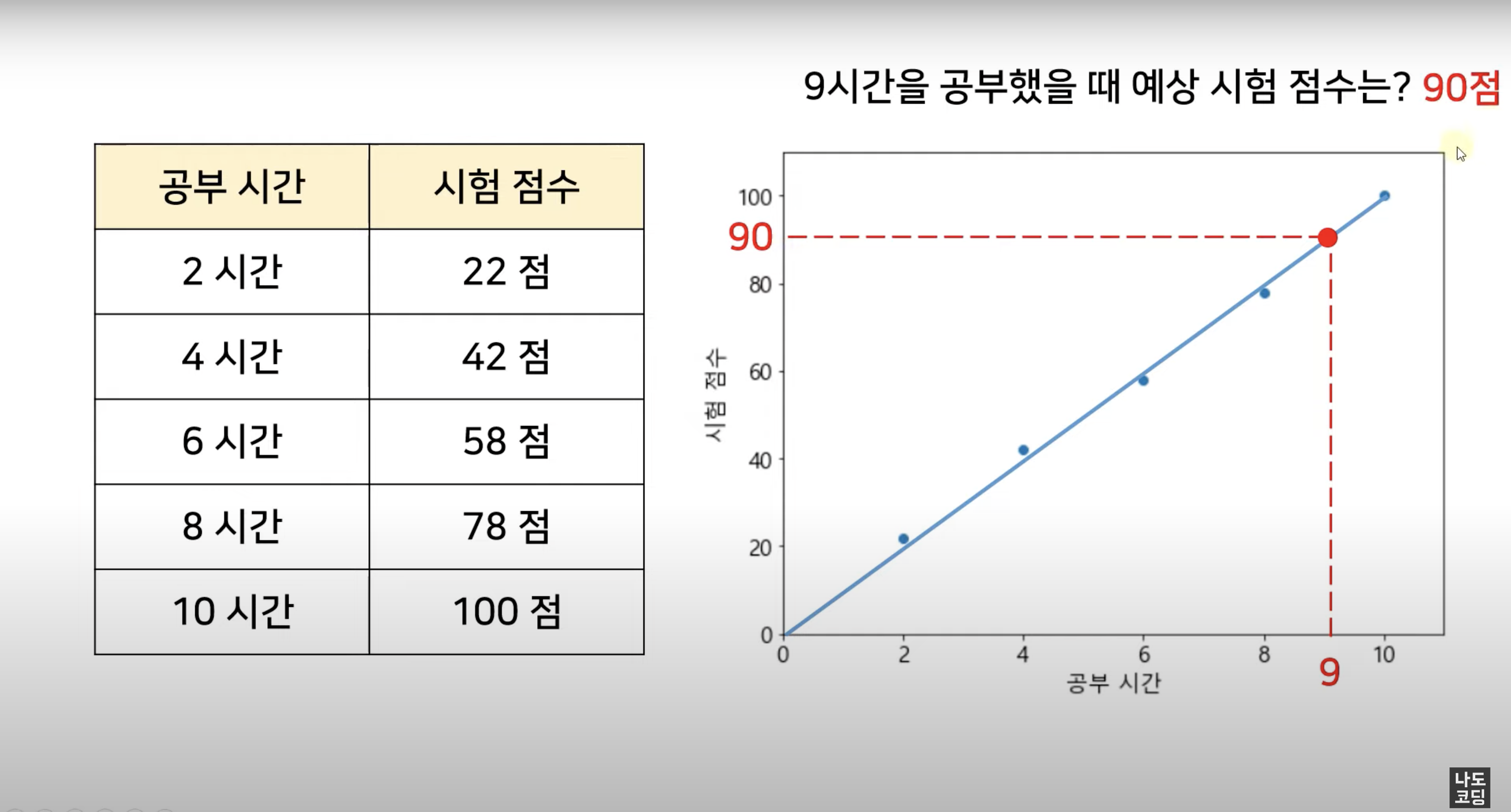
Regression 회귀
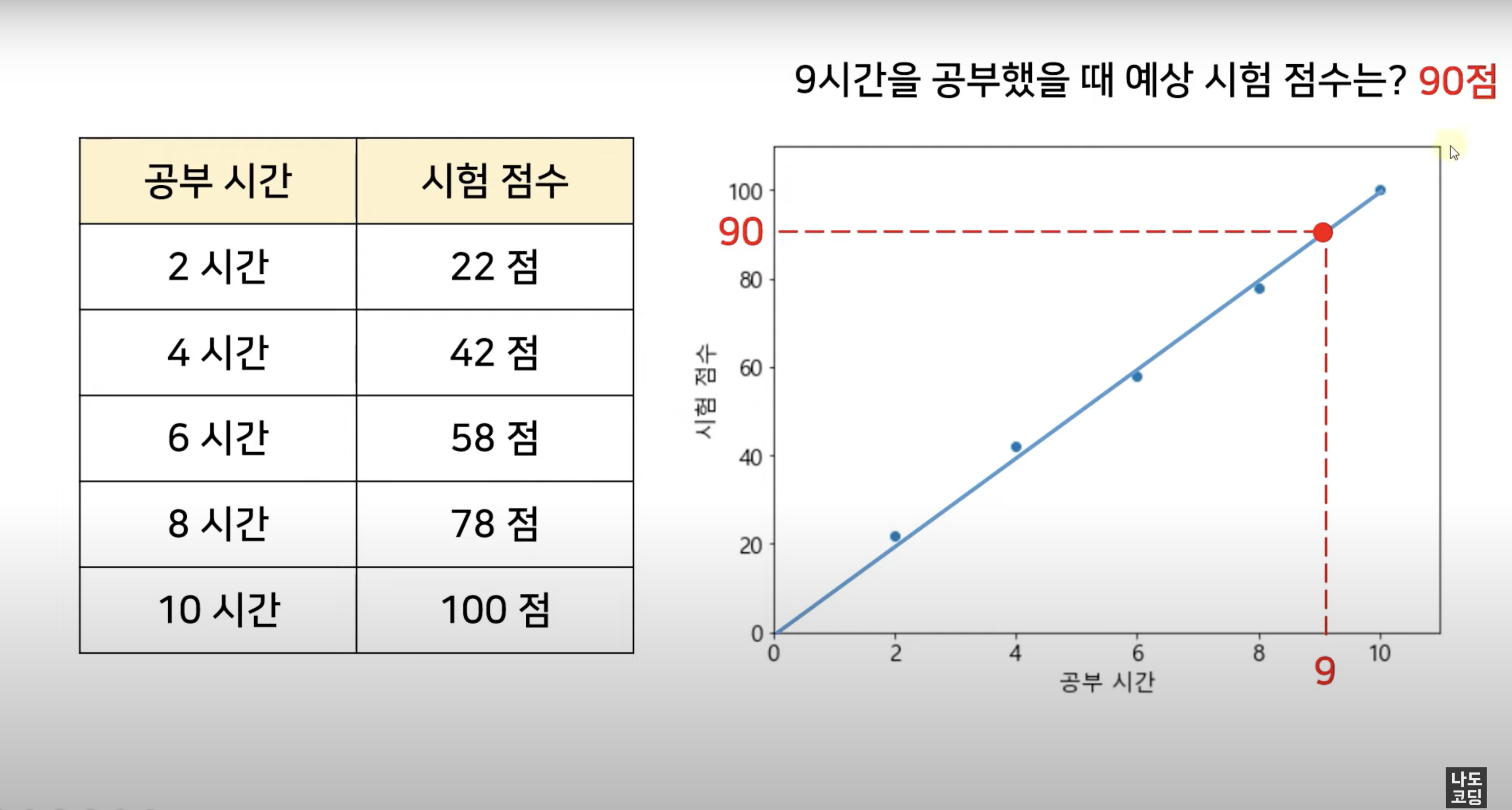
쉽게 말해 변수들 간의 상관관계를 찾는 것, 연속적인 (continuous) 데이터로부터 결과를 예측하는 것이고, 주로 예측 결과가 숫자일 때 적합해요.
예를 들어, 근속연수에 따른 임금, 키에 따른 몸무게, 사용 기간에 따른 스마트폰 가격, ... 등을 알고싶을 때 사용하죠.
Classification 분류
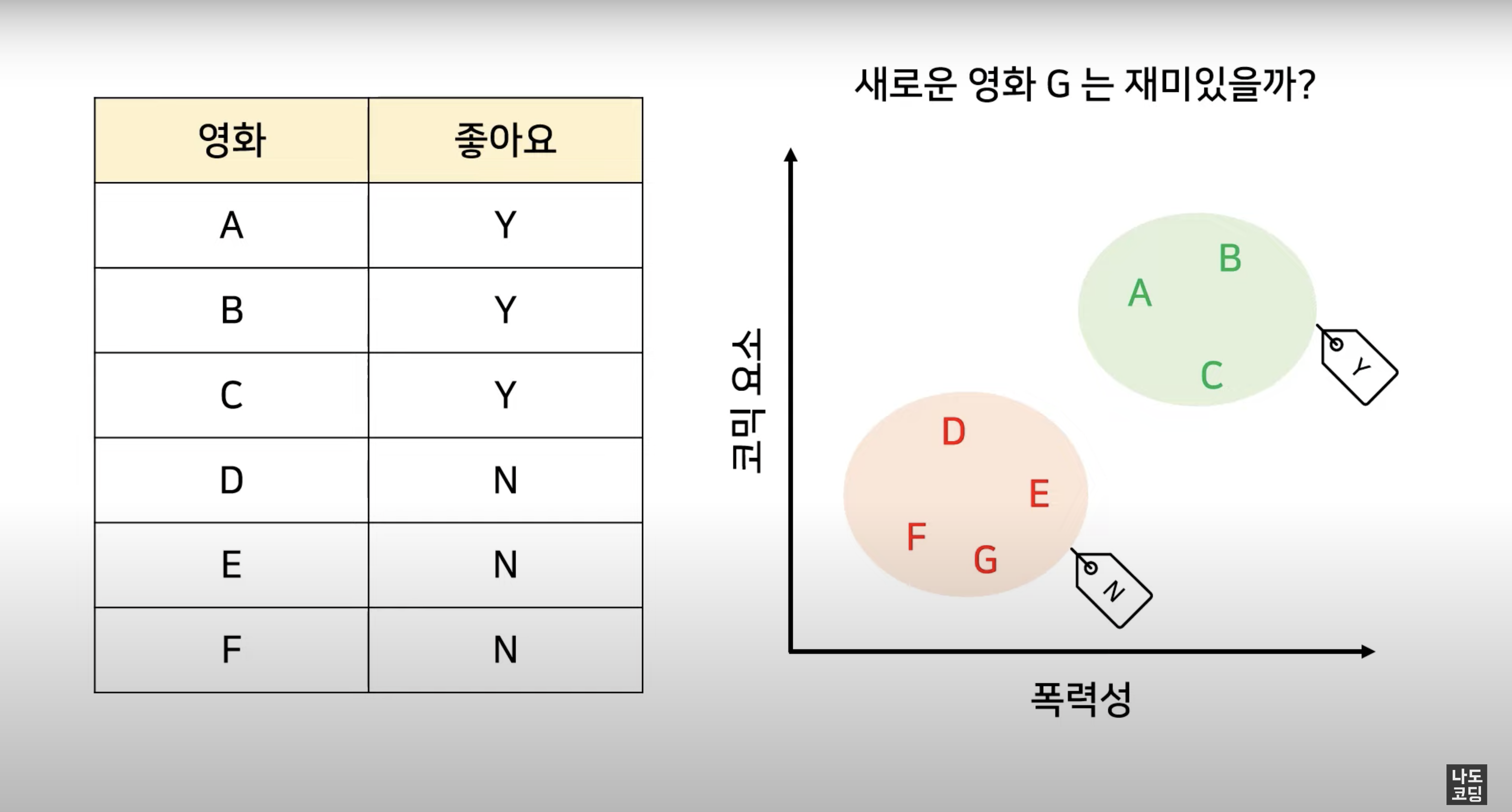
classfication은 주어진 데이터를 정해진 범주 (category) 에 따라 분류하고,
주로 예측 결과가 숫자가 아닐 때 사용해요.
예를 들어, 스팸 메일 필터링, 시험 합격 여부, 재활용 분리수거 품목, 악성 종양 여부, ... 등이 될 수 있겠네요.
Linear Regression 선형 회귀
✅ 용어 체크
X = Independent variable 독립 변수 (원인) = 입력 변수, feature
y = Dependent 종속 변수 (결과) = 출력 변수, target, label
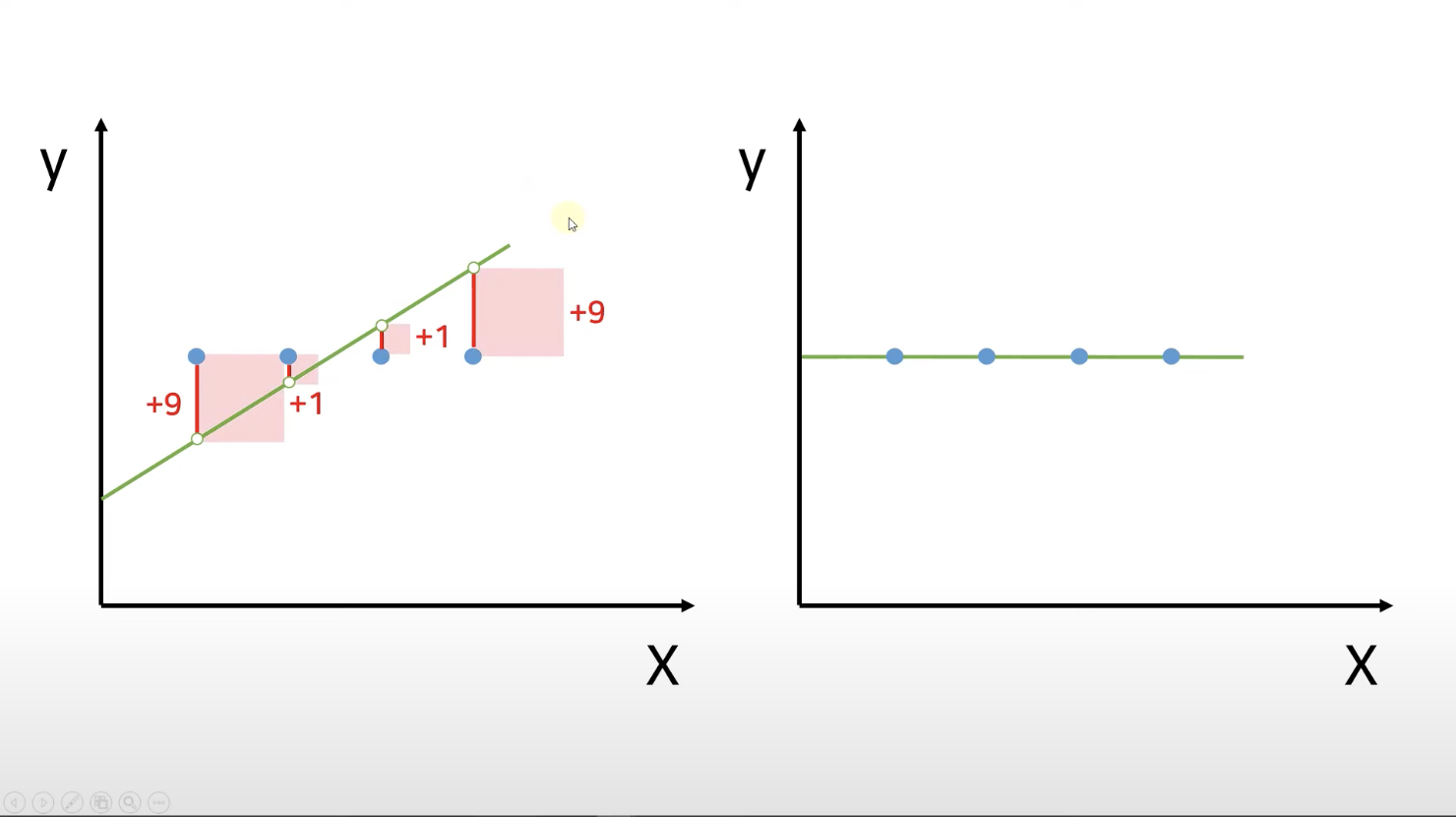
선형 회귀 방법을 통해 우리가 찾으려고 하는 선은
실제 값과 예측 값 차이의 제곱의 합을 최소화한 선이에요.
어떻게 구하냐고요?

실제 값 - 예측 값 = 잔차
이 잔차들을 다 더해서 최소가 되는 직선
➡️ 전체 데이터를 가장 잘 표현하는 최적의 직선, 그 선을 "best-fit" 이라고 해요.
제곱근의 목적은 큰 값의 영향을 줄이고 관계를 보다 선형적으로 만들 수 있고 이는 제곱근 함수가 작은 값보다 큰 값을 더 많이 압축하기 때문이에요.
결국 우리가 원하는 것은 최적의 선에 해당하는
y = mx + b
m : 기울기 (slope, coefficient)
b : y 절편 (intercept)
입니다!
실습1. Linear Regression
- Linear Regression을 그리기 위해 필요한 라이브러리와 데이터셋을 불러옵니다.
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('LinearRegressionData.csv')- 가져온 데이터셋 중 상위 5개를 살펴봅니다.
dataset.head()

3. X에는 독립변수 데이터를, y에는 종속변수 데이터를 저장해요.
X = dataset.iloc[:, :-1].values # 처음부터 마지막 컬럼 직전까지의 데이터 [독립 변수 - 원인]
y = dataset.iloc[:, -1].values # 마지막 컬럼 데이터 [종속 변수 =결과]
X, y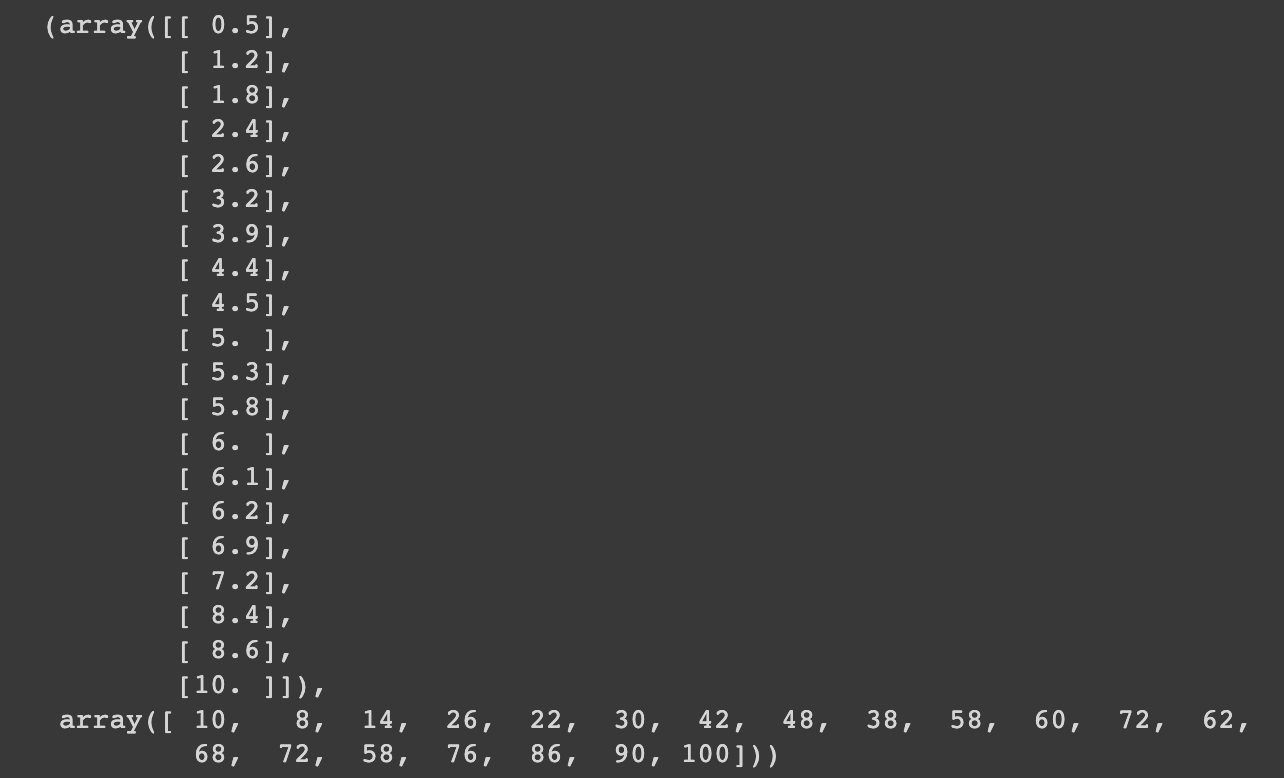
4. 객체를 생성하고 학습 시켜요.
from sklearn.linear_model import LinearRegression
reg = LinearRegression() # 객체 생성 (새로운 선형 회귀를 만들 준비)
reg.fit(X,y) # 학습 [모델 생성, (fit=학습을 시키는 함수, 학습을 하면서 모델 생성 - 모델 완성)]
#reg(모델)
- X에 대한 예측 값을 살펴 봅시다.
y_pred = reg.predict(X) # 데이터를 넣어서 X에 대한 예측 값
y_pred
- 데이터 시각화 뿅!
plt.scatter(X,y, color='blue') # 산점도
plt.plot(X, y_pred, color='green') # 선 그래프
plt.title('Score by hours') # 제목
plt.xlabel('hours') # X 축 이름
plt.ylabel('score') # y 축 이름
plt.show()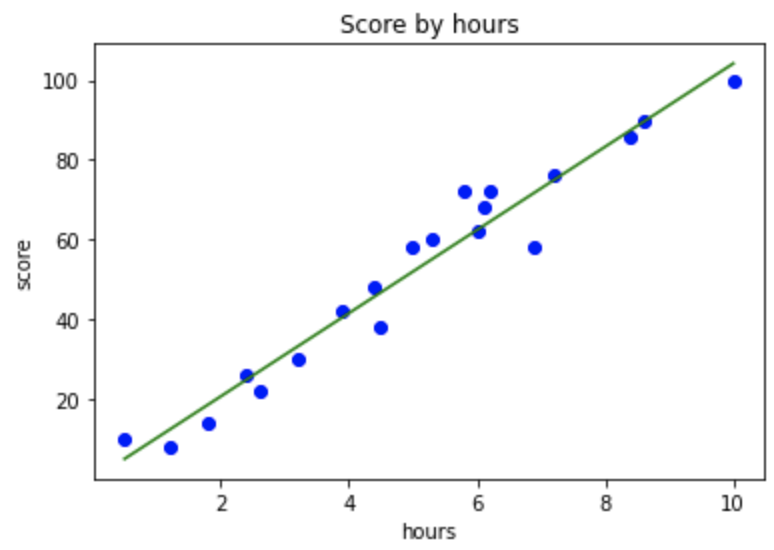
- 마지막으로 기울기와 y절편을 구해봅니다.
print('9시간 공부했을 때 예상 점수 : ', reg.predict([[9], [8], [7]]))
reg.coef_ # 기울기 (m)
reg.intercept_ # y 절편 (b)9시간 공부했을 때 예상 점수 : [93.77478776 83.33109082 72.88739388]
array([10.44369694])
-0.218484702867201
이제 안녕. 다항회귀에서 봐요~
