Intro
RL reward 설계의 주요한 문제 : reward exploitation
→ 원하지 않는 방향의 꾀를 생각해내어 sub optimal 한 해를 도출
→ 이에 대한 대안으로 imitation learning의 도입
vs
인간의 경우
→ progress 당 지도자의 feedback을 통해 올바른 길로 가고있는지 확인하면서 학습
2가지 contributions
1) unsupervised pre-training
2) off-policy preference based learning
-
초반 오직 agent의 intrinsic motivation 만을 이용해서 다양한 experience를 야기해 teacher 가 개입된 이후 meaningful 한 feedback을 줄 수 있도록 한다
-
RL의 고질적 문제인 sample inefficiency 와 preference-based learning 에서 인건비를 줄이기 위해 off-policy learning을 도입했는데 이 때 생기는 변화를 최대한 줄이기 위해 reward model이 업데이트 될 때마다 agent의 past experience를 relabing 하는 아이디어를 제안했다
contributions
1) unsupervised pre-training 과 off-policy learning을 통해 feedback 과 sample efficiency에 기여
2) reward function을 구성하기 힘든 behavior를 더 잘 학습할 수 있다
3) reward exploitation 을 피할 수 있다
Related work
Unsupervised pre-training for RL
기존까지 다양한 intrinsic reward들을 통해 방문하는 state space의 boundary를 늘리고자 하는 시도들이 많이 있었다
이 논문에서 제시한 unsupervised pre training을 통해 teacher가 더 의미있는 행동들 중 고를 수 있도록 유도했다
Preliminaries
SAC - soft actor critic
soft value function을 사용하며 아래와 같다
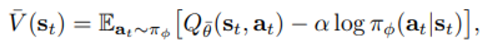
뒤의 항은 expectation 밖으로 나오게 되면 entropy 를 의미하게 된다
actor-critic 방식인 sac는 아래와 같은 loss 들에 의해 훈련된다
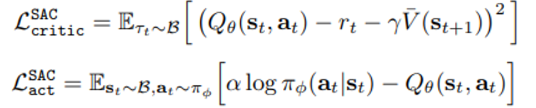
위의 loss를 통해 Q function 을 approximate 하는 theta 를 훈련시키고
아래의 loss를 통해 policy를 나타내는 phi 를 훈련시킨다
- 원래 논문과 다르게 action 확률을 나타내는 phi에 temperature 상수 alpha가 붙어있다
Reward learning from preferences
선호에 의한 reward 와 확률 사이의 관계를 아래와 같이 정의한다
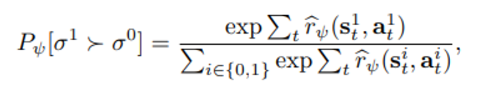
우리가 원하는 것은 reward function의 parameter psi 의 학습방식이며 아래와 같은 loss 함수를 통해 업데이트 된다
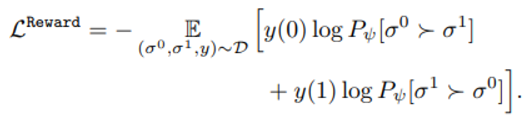
main
큰 흐름
1) teacher에게 의미있는 정보 제공을 위한 policy pre-train 과정(엔트로피를 이용한)
2) reward function 학습
3) SAC 방식에 근거한 actor, critic 학습 (reward stationary 함을 위해 experience buffer relabeling 과정?)
- policy pre-training 의 엔트로피 정의
particle-based entropy estimator 의 간단화 버전을 엔트로피로 사용
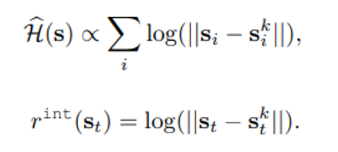
quote : ‘compute k-NN distances between a sample and all samples in the replay buffer’ → 이 부분이 잘 이해되지 않음!
이 후 std의 running estimate로 normalize 한다
pre-training pseudo code는 아래와 같다

→ 일정 timestep 동안 관찰 결과와 r_int 를 수집 후 batch training을 통해 actor-critic 훈련을 진행함을 알 수 있다
- 전체적인 알고리즘

→ line 4 까지는 algorithm 1 에 설명된 pre-training 부분
→ line 9-12 는 특정 sampling 방식에 따라 뽑힌 data들에 대한 preference 제공
이 때 sampling 방식은
1) uniform sampling
2) ensemble-based sampling
3) entropy-based sampling
→ line 14-16 위에서 설명한 entropy 형태의 reward 의 loss를 최소화 하는 방향으로 reward function parameter를 훈련
→ line 20-26 는 env 상호작용 이후 buffer 에서 batch 만큼 뽑아 actor-critic 훈련을 의미
