Addressing Function Approximation Error in Actor-Critic Methods
배경지식
1) Q-learning
Q-learning은 TD의 variant로 target을 정하는 policy는 100% greedy로 아래와 같이 결정된다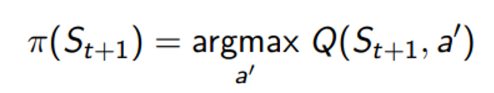
이로부터 Q-learning의 TD target은 아래와 같이 정의될 수 있다.
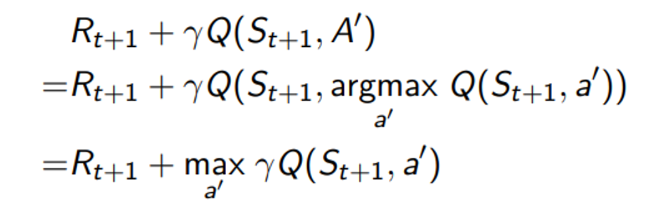
Q-learning 의 다음 action을 선택하는 policy는 한 정책이며 아래와 같이 TD target을 향해 Q-function을 업데이트 한다.
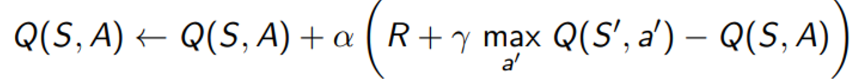
만약 Q-function에 대해 로 function approximation을 사용한다면 아래와 같이 parameter를 업데이트 할 수 있을 것이다.
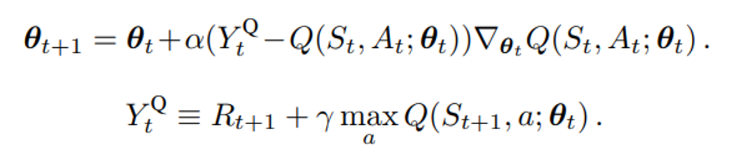
첫 번째 식은 TD target 인 Y와 Q-function 사이의 L2 norm에 대한 미분값에 learning rate 를 곱한 결과로 이해하면 될 것이다.
2) Deep Q-Network (DQN)
Target network의 parameter 를 이용해서 TD target을 설정해 training 과정을 안정화시키는 방식을 의미하며 TD target 수식은 아래와 같다 .
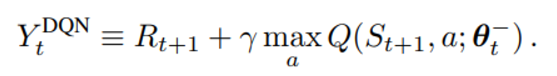
parameter update 과정은 위의 Q-learning과 동일하다.
3) Double Q-learning
위의 두 가지 방법은 Q-value를 최대화 시키는 action을 고르는 parameter와 action을 고른 이후 이를 평가하기 위한 parameter가 동일하기 때문에 overestimation 문제가 발생한다.
이는 원래 TD target 수식을 아래와 같이 변경하면 쉽게 확인할 수 있다.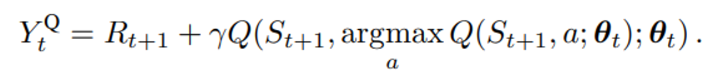
원래의 수식의 action 부분을 argmax 형태로 전개한 모습이다. (로 선정, 평가 parameter가 동일)
Overestimation을 제거하기 위해 아래와 같은 서로 다른 두 parameter를 이용해 선정, 평가가 이뤄지는 framework를 제공한다.
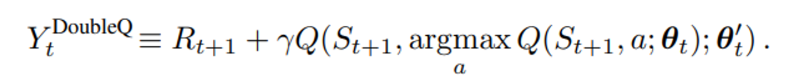
이 때, 두 parameter는 서로 선정, 평가의 역할을 바꿔가며 업데이트 될 수 있다.
4) Double DQN
이 방식의 TD target은 아래와 같다
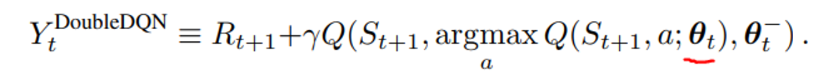
DQN과의 차이점은 DQN은 위의 objective에서 밑줄 친 부분이 로 표시될 것이기 때문에 더 늦게 업데이트 되는 network를 target, 선두하는 network를 policy network라고 한다면
- DQN → TD target action 선택 : target network || action에 대한 평가 : target network
- DDQN → TD target action 선택 : policy network || action에 대한 평가 : target network
와 같은 식으로 이뤄진다는 차이가 있다.
