2022, End-to-End Audio-Visual Neural Speaker Diarization [2022, Interspeech]
Figure
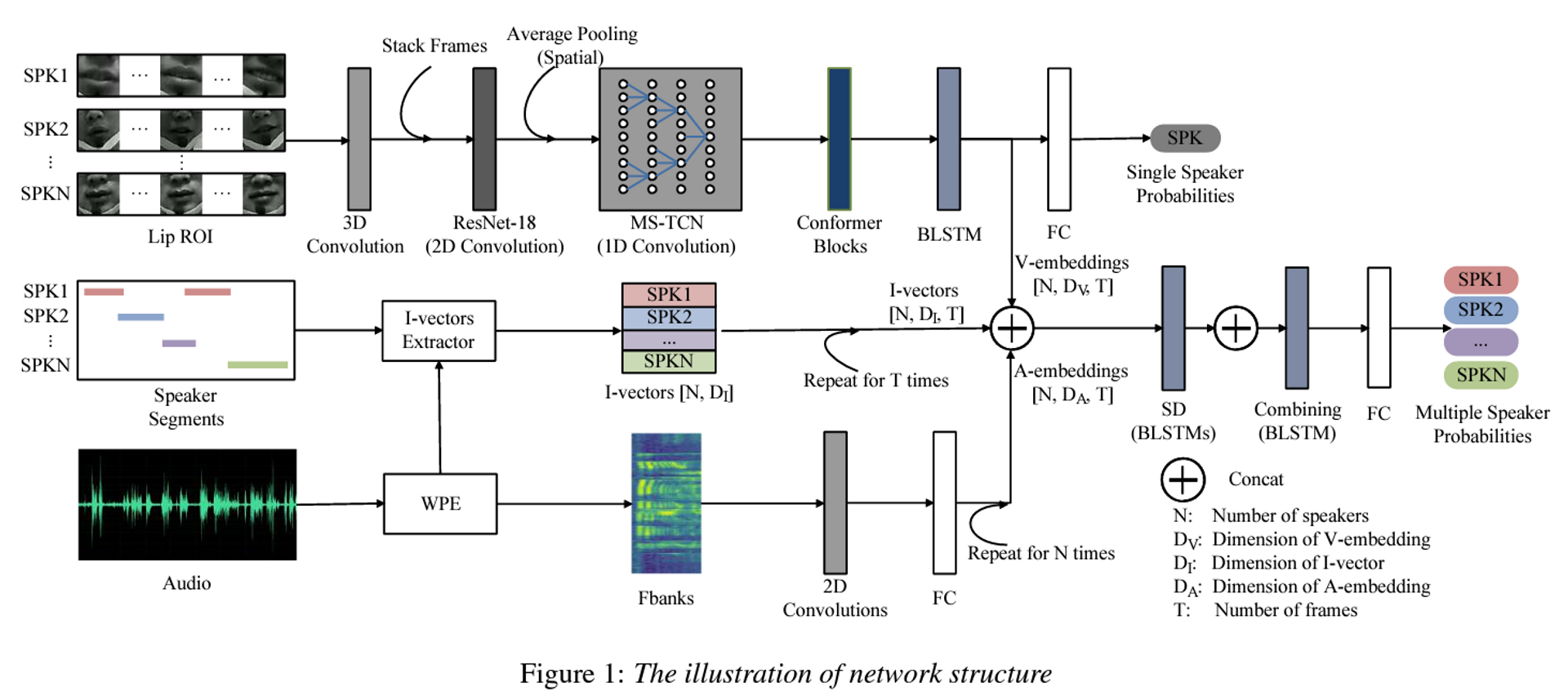
Abstract
- multimodal inputs
- uses audio features, lip regions of interest, and i-vector embeddings
- I-vectors are the key point to solve the alignment problem caused by visual modality errors
- e.g., occlusions, off-screen speakers, or unreliable detection
- Our audio-visual model is robust to the absence of visual modality, where the diarization performance degrades significantly using the visual-only model
- It is robust to visual modality errors and outperforms audio-only and video-only systems
Introudction
- exploring the effects of lip motion and speech on speaker diarization using high-definition lip ROIs and single-channel audios
- By manually removing lip ROI fragments, we can compare the impact of different degrees of lip misalignment on speaker diarization.

3개의 댓글

Neural speaker diarization is a cutting-edge technology in speech processing that involves the identification and separation of individual speakers within an audio recording. This technology uses neural networks to analyze the acoustic features of speech, such as pitch and tone, making it possible to attribute spoken words to distinct speakers accurately. While the concept might seem as specialized as shopping for rzr xp1000 accessories in the world of off-road vehicles, its applications are broad, ranging from enhancing voice assistants to improving transcription accuracy in multi-speaker environments. This approach improves over traditional methods by adapting more dynamically to varied speech patterns and overlapping conversations.

The system may provide a strong framework that makes up for these visual disparities by using i-vector embeddings slope 2. By aligning the auditory characteristics with the visual data via statistical representation, the i-vectors improve the identification system's overall accuracy.
From the very core only up online of my being, I want to express my heartfelt thanks for your extraordinary generosity, both in material ways and in the warmth and love you have shown me.
only up