Introduction
Background: TS-VAD
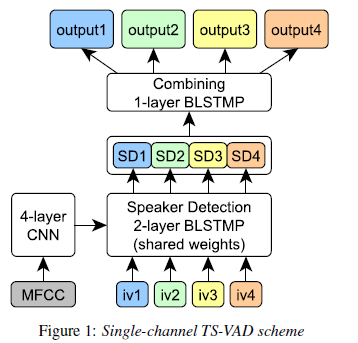
- TS-VAD (Target Speaker Voice Activity Detection)\, 2020 Interspeech
- Detect speech activity based on the target’s profile (e.g. i-vector)
- Modules
- CNN based encoder
- Extracts embedding vectors
- BLSTM based ISD (Independent speaker detection)
- Process each target speaker independently based on speaker profile and embedding
- BLSTM based JSD (Joint speaker detection)
- Models both cross-time and cross-speaker information
- Predict activities of all speakers simultaneously
- CNN based encoder
-
Drawback of TS-VAD
- Unable to handle an arbitrary number of speakers
- High demand for GPU memory
-
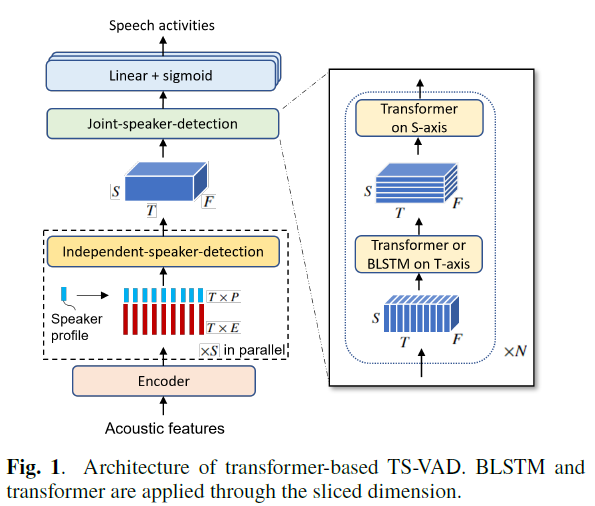
Transformer based TS-VAD
- Using Transformer to cope with any number of speakers
- Use an input tensor with variable-length time and speaker dimensions
- Model capture the correlations both in time and across the speakers
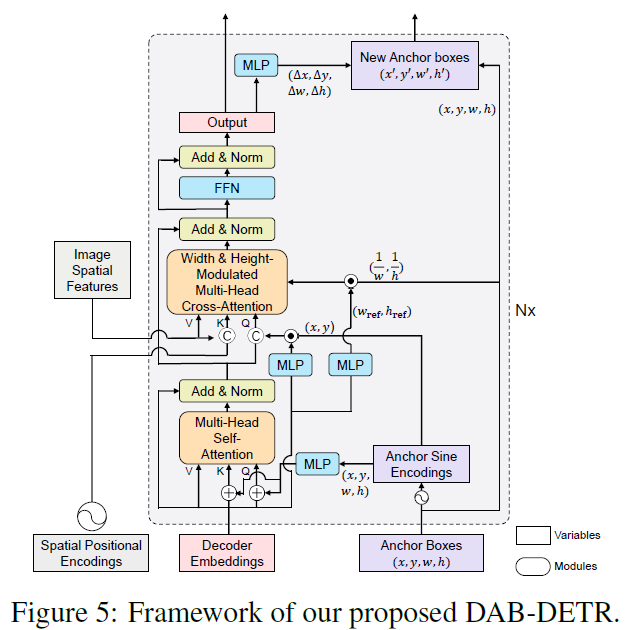
- DAB-DETR
- Novel query formulation using dynamic anchor boxes (DAB) for DETR
- Offer a deeper understanding of the role of queries in DETR
- Directly uses box coordinates as queries and dynamically updates them layer by layer
- 1. Query - Feature 간 similarity 향상
- 2. DETR 에서 training convergence 속도가 느렸던 점을 개선
- 3. Positional attention map 을 직접 box 의 width\, height 정보를 통해 조절 가능
Transformer decoder part
- Dual queries fed into the decoder
- Dual query
- Positional queries (anchor boxes)
- content queries (decoder embeddings)
- objects which correspond to the anchors and have similar patterns with the content queries
- Dual query
- The dual queries are updated layer by layer
- to get close to the target ground-truth objects gradually
- to get close to the target ground-truth objects gradually
Seq2Seq TS-VAD
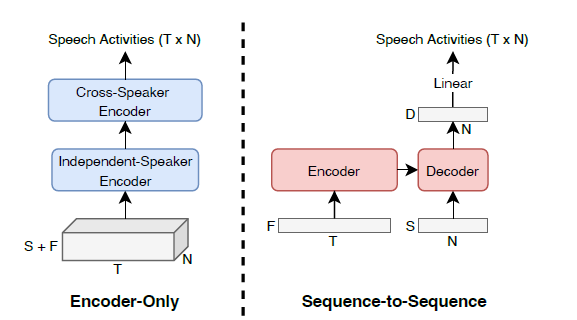
-
High demand for GPU memory
- Predict speech activities has a shape of T x N x (S + F)\,
- T is the length of the feature sequence
- N is the number of speakers
- S is the number of speaker profiles dimension
- F is the number of frame-level representations
- As T and N increase \, the memory usage also increases and limits the model's ability to process longer feature sequences and more speakers at once
- => Seq2Seq model
- Output length of encoder-only models is fixed at T\, meaning that the temporal resolution of voice activity detection (VAD) cannot be changed freely
- => more temporal resolution
- Predict speech activities has a shape of T x N x (S + F)\,
-
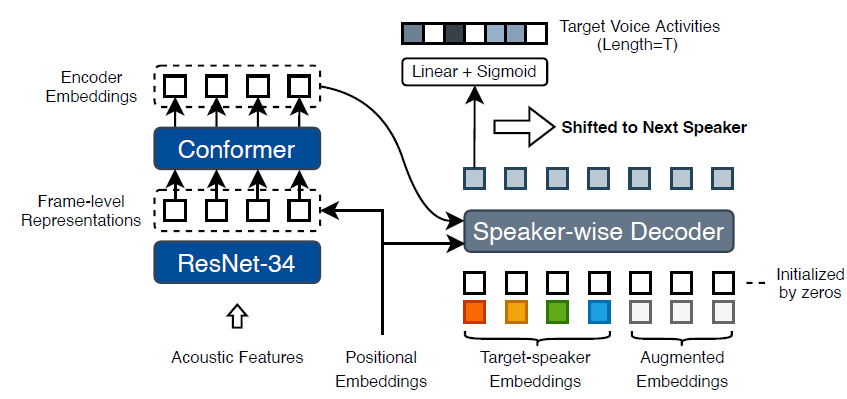
Architecture
- separates the frame-level representations and speaker embeddings
- Feeds them into the encoder and decoder sides separately
- T x F + N x S (기존: T x N x (S + F))
- This reduces the need for massive tensor concatenations and reduces the memory consumption.
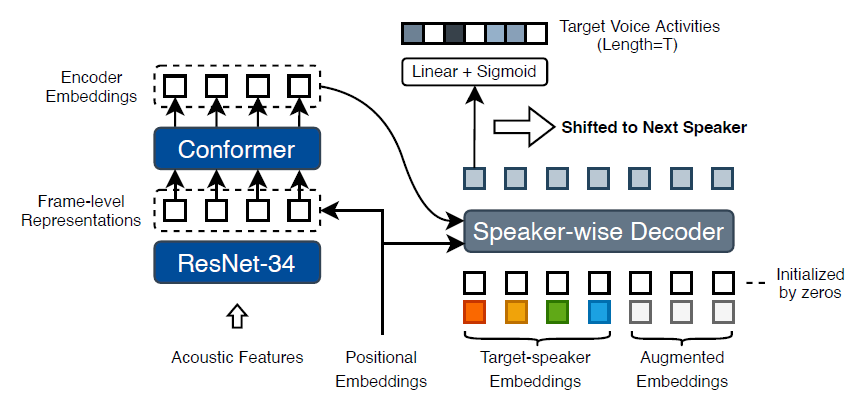
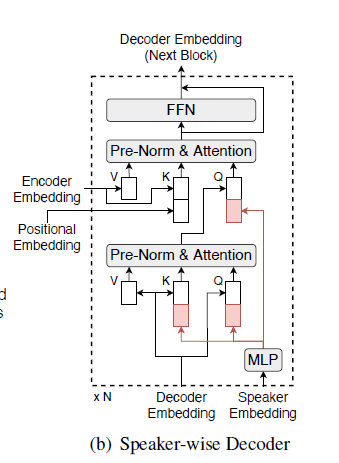
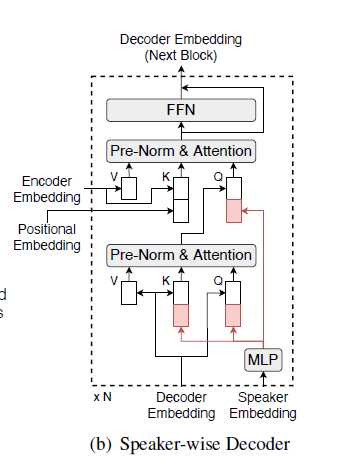
Speaker Wise Decoder (SW-D)
- SW-D
- estimate target-speaker voice activities
- considering cross-speaker correlations
- two inputs
- decoder embeddings
- Learning temporal positional information
- auxiliary queries (target-speaker embeddings)
- decoder embeddings
- Output
- posterior probabilities of voice activities for each speaker
- dimension of the last linear layer controls the temporal resolution of detected voice activities
- means a longer output length can provide more precise timestamps
- estimate target-speaker voice activities
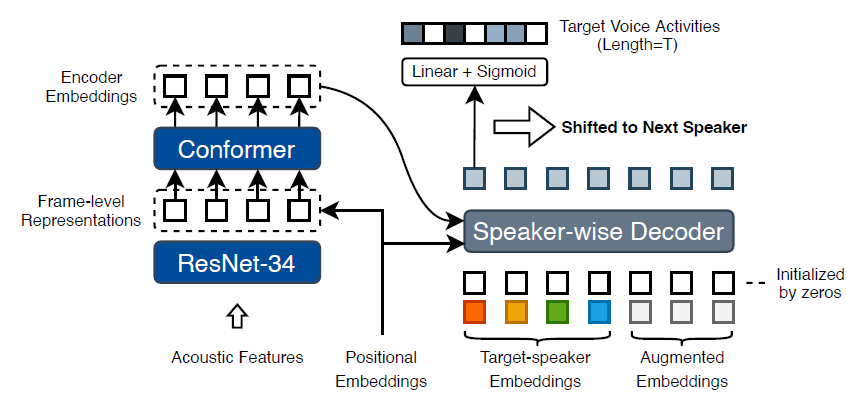
- Embedding Augmentation
- align different numbers of speakers in training mini-batch data
- SW-D module has a fixed decoding length L
- align different numbers of speakers in training mini-batch data
- The method of Embedding Augmentation is as follows
- embeddings may be directly set to zeros or randomly replaced with another speaker not appearing in the current signal
- Furthermore\, a group of embeddings may have a probability of 0.2 to be entirely replaced with non-existent speakers.
- Embeddings are shuffled to keep the model invariant to speaker order

Currently pursuing my Ph.D. in GIST, I am deeply intrigued by the field of speaker diarization and committed to making meaningful contributions to it.