2023, WHU-Alibaba [MISP 2022]
Figure
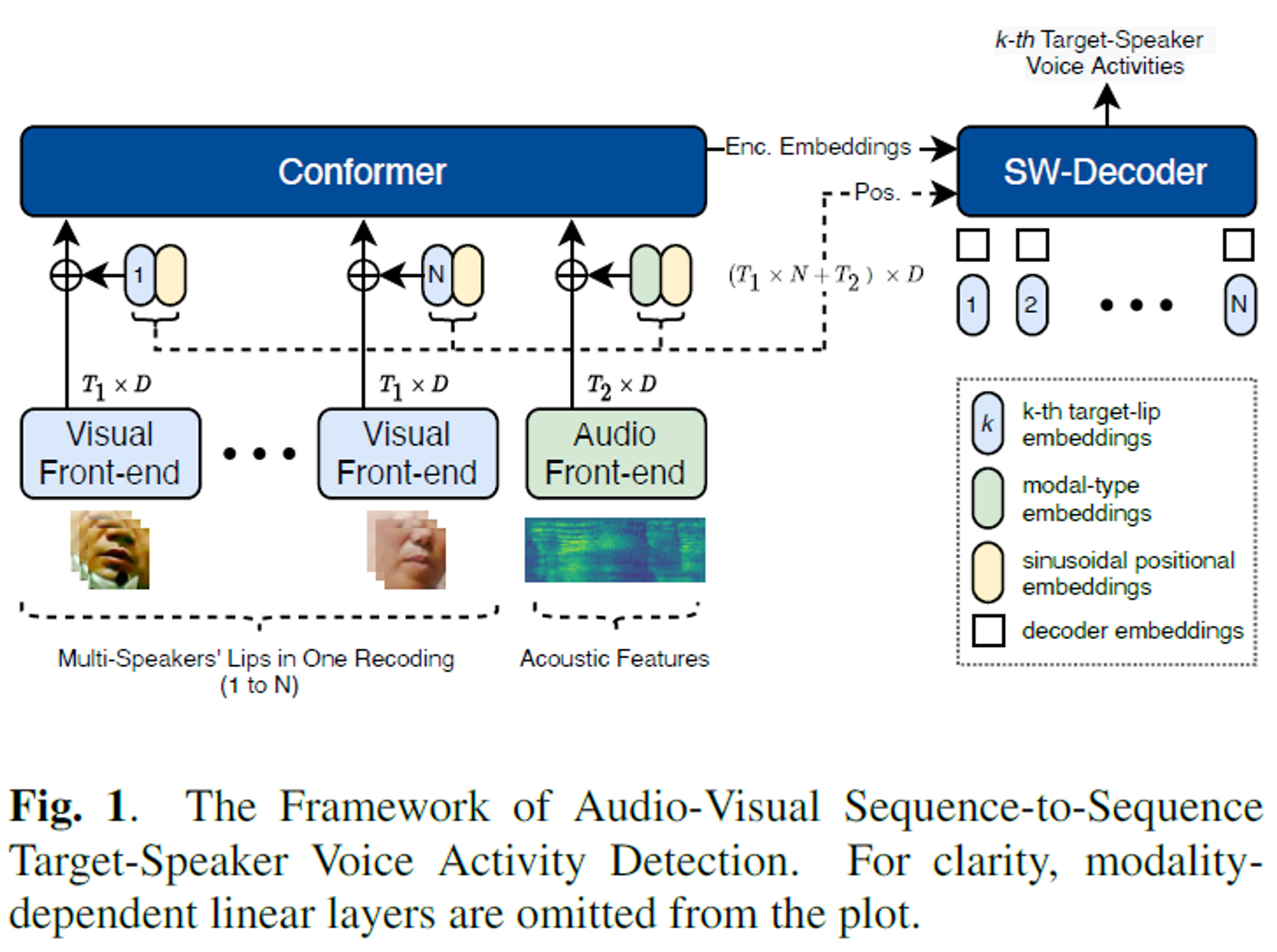
SYSTEM DESCRIPTION
Visual front-end
- modified ResNet18-3D model for processing lip videos
- They make three changes to the standard Pytorch implementation:
- 1) adjusting the first stem layer's convolutional
- kernel size(=7), stride(=2), and output channels(=32) w/o maxpooling
- 2) altering the output channels of the residual blocks
- {32, 64, 128, 256}
- 3) removing all temporal downsampling operations in the residual blocks.
- 1) adjusting the first stem layer's convolutional
- The model ultimately transforms lip image sequences into feature embedding sequences through a spatial global average pooling layer
Learnable embeddings
Target-lip embeddings ()
- Represent the relative identities of input lips and corresponding voice activities
- relationship between the movements of the lips in the input videos and the corresponding voice activities
- Additionally, learnable modality-type embeddings are initialized to differentiate between encoded acoustic and visual features.
Modality-type embeddings ()
- Help distinguish between the sound (acoustic) features and the visual features (lip movements) in the input data
- These embeddings help the model better understand and process the information from both the audio and visual aspects of the videos
The authors propose a new approach for handling positional embeddings by incorporating target-lip embeddings, modality-type embeddings, and sinusoidal positional embeddings.
They use two modality-dependent linear layers
to map audio-visual features to the exact dimension of positional embeddings.
Conformer
- Inputs
- Sum of aligned feature sequences and positional embeddings
TS-VAD
- Inputs
- acoustic features and speaker enrollments (e.g., x-vectors).with the order of enrollments determining the target-speaker voice activities.
- Target-speaker embeddings are replaced with the new target-lip embeddings on the decoder side, and decoder embeddings are set to zeros
- lip videos are used as both visual features and enrollments
- since there are no off-screen speakers in the competition database
- lip videos are used as both visual features and enrollments

Currently pursuing my Ph.D. in GIST, I am deeply intrigued by the field of speaker diarization and committed to making meaningful contributions to it.