paper: CVPR'22
code: github
demo: demo
blog: blog
✏️ 한줄요약 ✏️
- Segmentation을 위한 최초의 foundation model
- 어떤 이미지든 (zero-shot) segment을 할 수 있음
Motivation
Foundation Model : 거대한 데이터셋으로 pre-training을 시킨 거대한 모델 (generalizability)
Image Segmentation에 대한 Foundation model 개발
이를 가능하게 하기 위한 세 가지 질문
1. zero-shot generalization을 가능하게 하는 task는 무엇인가? (task)
2. 적절한 model의 구조는 무엇인가? (model)
3. 이 task와 model에 적절한 data는 무엇인가? (data)
1. TASK
ChatGPT: prompt 기반의 모델 (prompt: 점(point), 박스(box), 그리고 텍스트(text))
Segmentation에서도 prompt을 입력 받을 수 있도록 함.
Promptable Segmentation Task 제안
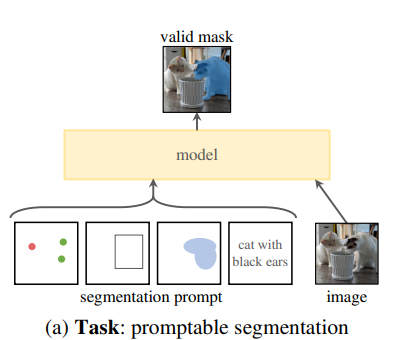
해당 prompt가 애매모호(ambiguity)하거나 여러 object을 지칭해도 됨.
- prompt중 한 종류인 point label이 shirt을 가리키고 있을 때 실제 의도는 shirt 그 자체일수도 있지만 shirt를 입고 있는 사람일 수도 있음. 해당 prompt가 여러 object을 지칭해도 model의 output은 반드시 여러 object 중 하나의 resonable mask을 뽑아내도록 학습할 것.
2. Model
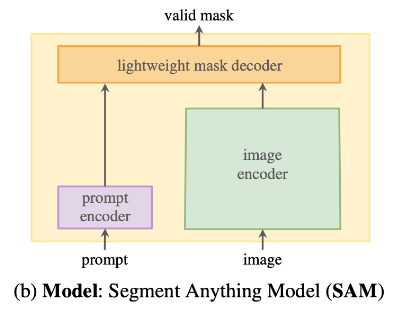
- Flexible 하고 ambiguity-aware한 특성의 prompts 지원
- interactive하게 real-time으로 segmentation mask를 compute 가능하게
SAM 제안
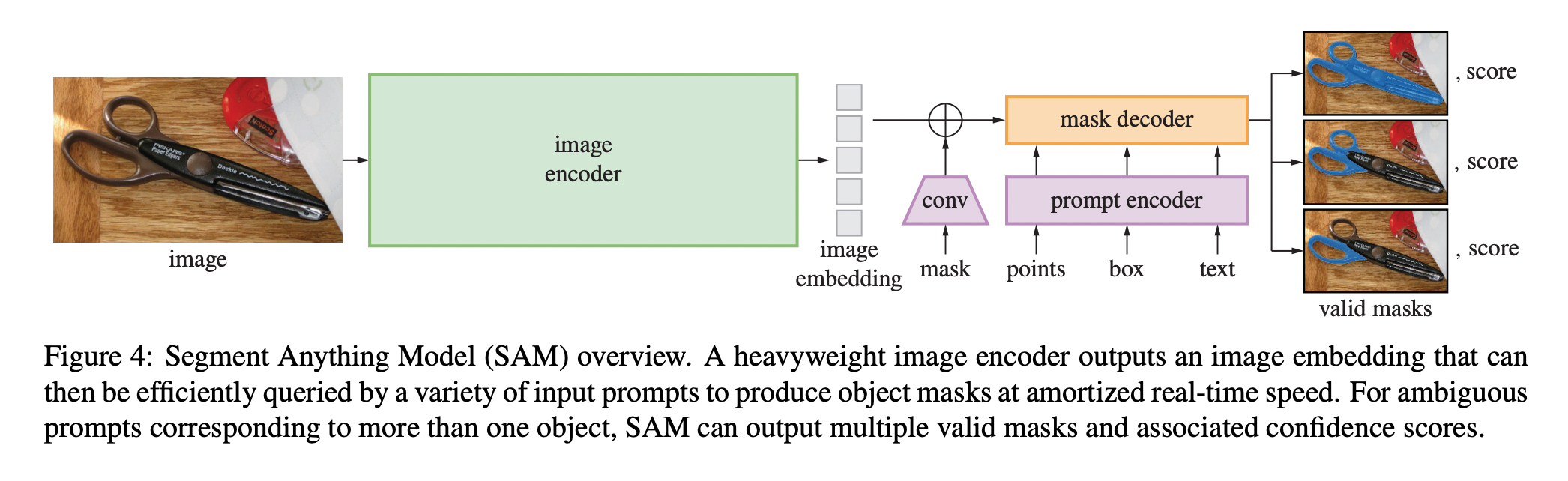
- Image Encoder (Powerful)
- 고해상도 이미지를 처리하기 위해 Masked Autoencoder(MAE)로 pretraining을 한 ViT 기반의 구조 사용
- image을 입력으로 image embedding 출력
- Image Encoding은 Prompt처럼 실시간성이 요구되지 않기 때문에 높은 스케일로 사용하는 것이 가능 (prompt와 달리 이미지당 최초 한번만 수행)(1024, 1024) 이미지 입력을 사용 (사이즈 안맞으면 padding.)
Embedding 의 크기는 1024/16에 해당하는 (64,64)
1x1 conv를 사용해서 256 채널의 출력을 얻은 후 3x3 conv 적용. (각 conv 뒤에는 Layer Normalization 적용) - Prompt Encoder (Flexible)
- prompt를 입력으로 prompt embedding 출력 (flexible)
- Point, Box, Text와 같은 Sparse prompt는 256차원의 embedding으로 mapping
- point : point location과 학습 가능한 Foreground/Background Embedding 중 하나와의 합으로 표현
- Box : Top-left Corner을 나타내는 learned embedding과 bottom-right corner을 나타내는 learned embedding의 합으로 표현
- Free-from Text Encoder : CLIP
- Dense Prompt, 이미지와 공간적으로 대응되는 정보 (mask)
- mask는 입력 이미지보다 1/4 크기로 입력
- 2x2, stride 2의 conv 적용해서 추가적으로 크기를 4배 줄임
- 1x1 conv를 사용해서 채널을 256으로 변환
- 각 layer는 GELU activation과 Layer Normalization 사용
- 그냥 Image Embedding에 Convoltion 수행
- Mask와 Image Embedding은 Element-wise로 더해짐.
- Mask가 없는 경우에는 "no mask"를 나타내는 embedding 값을 사용
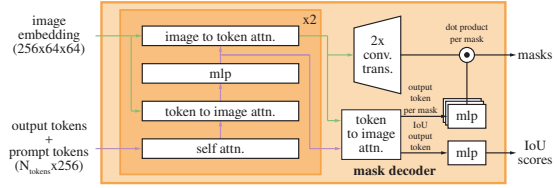
- Mask Decoder (Fast)
- 두 embedding 값을 입력으로 segmentation mask 출력 (fast)
- Mask Decoder은 DETR와 비슷한 구조임. (prompt self attention 및 cross attention -> MLP -> 동적 마스크 예측 head
- Transformer decoder block에 Prompt self attention과 Cross Attention을 양방향으로 활용. (Prompt-to-image, Image-to-Prompt)
- Decoder 적용 이전 단계에서는 Prompt Embedding에 Learned Output Token Embedding을 삽입. (ViT의 class token 처럼)
Decoder Layer 4가지 STEP 으로 동작
1. Token에 대한 Self Attention
2. Token을 Query로 하여 Image Embedding에 Cross-Attention
3. Point-wise MLP로 각 Token를 update
4. Image Embedding을 Query로 하여 Token에 Cross-Attention
(Cross Attention 과정에서 Image Embedding은 64x64의 256차원 벡터)
Loss
Mask - Focal loss : Dice Loss = 20:1 → Linear Combination
IoU Prediction Head - IoU prediction 과 GT 사이의 MSE 계산
IoU loss와 Mask Loss 는 1:1로 합산
3. Data Engine
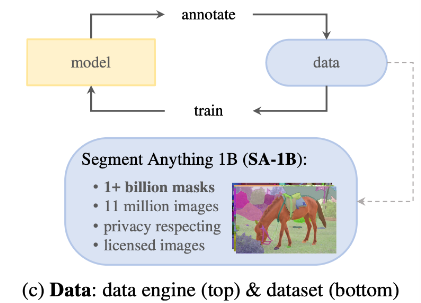
Segmentation에 필요한 마스크를 구하기 위해서 자체적인 Data Engine을 구현.
Data Engine은 세가지 Stage로 구성
- Assisted-manual :
수동적으로 점을 찍어주면 SAM모델이 어느정도 mask 만들어서 labeling 함. - Semi-Automatic :
특정 object 집합에 대해 SAM이 알아서 mask을 만들면 동시에 다른 object에 대해 마스크를 만듦.
ex. SAM에서 "apple에 대한 mask을 그려줘" 라고 하면 사과 mask 만드는 동안 다른애들을 작업하는 것. - Fully-Automatic :
이미지에 grid point을 찍어서 모든걸 알아서 masking함
이렇게 많은 데이터셋 수집 1B masks from 11M images
Segment Anything Dataset
SA-1B 데이터셋은 11M의 다양하고 높은 화질의 이미지를 포함하고 Data Engine으로 취득한 1.1B의 고품질 마스크를 포함
이미지 당 mask 개수가 압도적으로 많고, 평균 마스크 크기가 작음

- Image : 3300x4950 pixels image 취득. 이미지 크기가 너무 커지는 것을 고려하여 Shortest slide 기준으로 1500 pixel로 다운샘플링.
- Masks : Data Engine을 통해 99.1%는 완전 자동으로 취득. 이를 검증하기 위해서 전문가 annotation과 생성된 마스크 사이의 품질을 측정하였고. 생성된 마스크의 품질이 충분히 좋다고 결론.
- Mask Quality : 마스크의 품질을 평가하기 위해 500개의 이미지를 랜덤으로 sampling
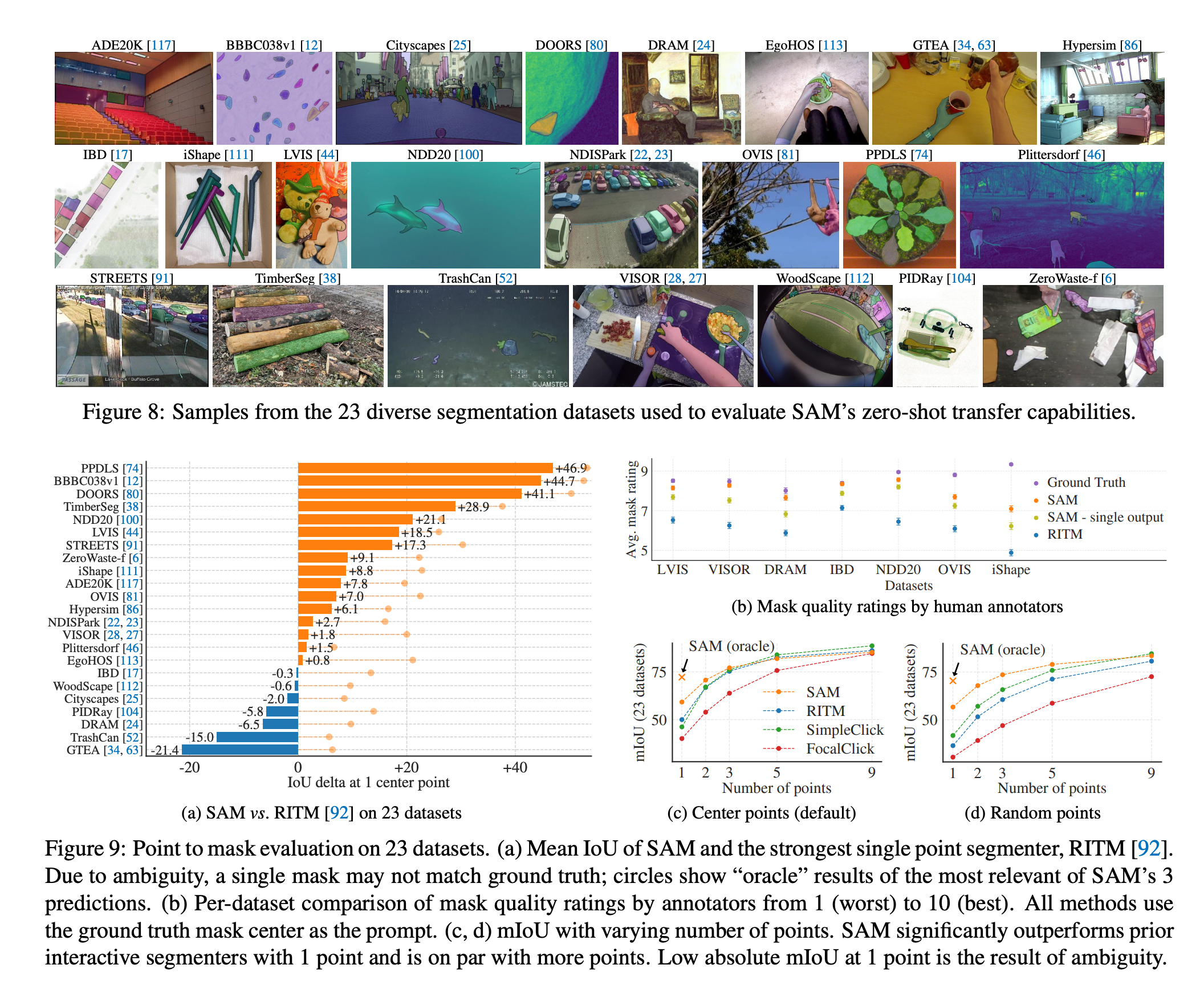
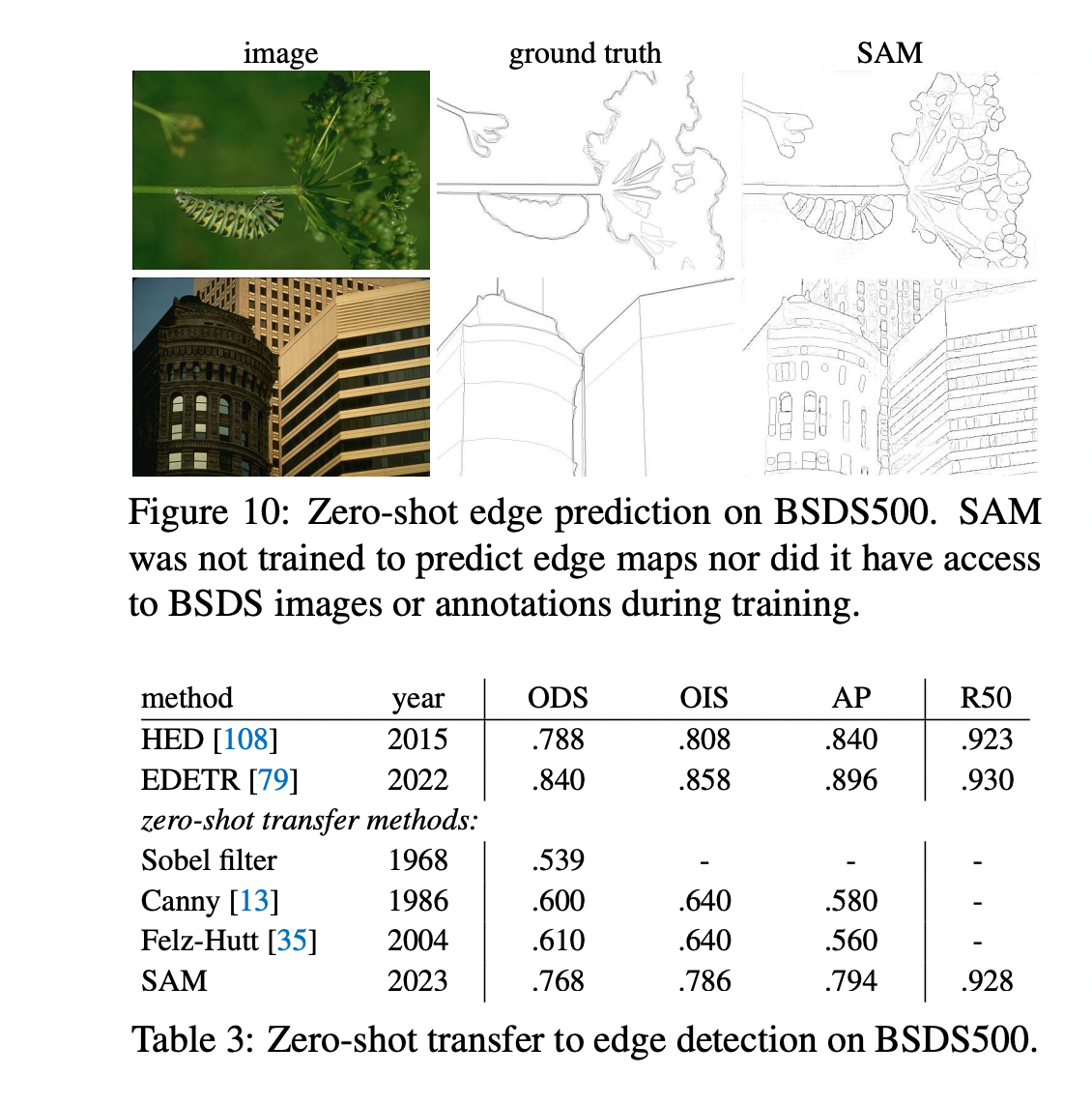
Zero-shot Transfer Experiments