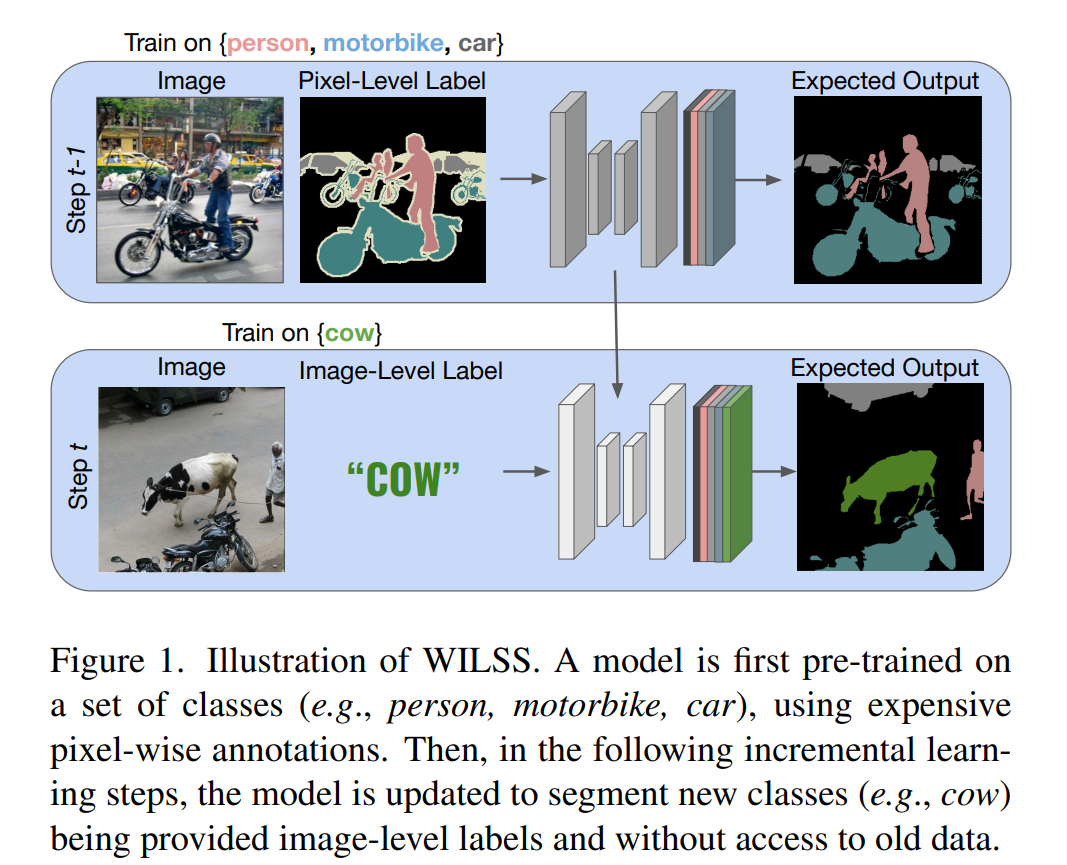
✏️ 한줄요약 ✏️
- Weakly Incremental Learning for Semantic Segmentation Task 제안
Motivation
Public datasets을 사용하고 있는 Pretrained models은 시간이 지남에 따라 incremental하게 update되지 않으며, 그들의 knowledge은 미리 정의된 set of classes에 제한되어 있음.
해결책:
기존 데이터셋에 새로운 주석이 달린 샘플을 추가하고 처음부터 모델을 학습
문제점:
업데이트가 빈번한 경우에는 실용적이지 않음.
왜냐하면 증강된 전체 데이터셋에서 학습하는 것은 시간이 너무 오래 걸리며 이는 machine learning model의 에너지 소비 및 탄소 배출량을 증가시킴.
또한, 원래 데이터가 더 이상 사용할 수 없을 때 (e.g., 개인정보보호 또는 지적 재산권 등) retraining이나 fine tuning은 불가능.
해결책:
기존 모델에 새로운 클래스를 incrementally 추가.
incremental learning은 새로운 데이터만을 사용하여 모델의 parameter를 update하며, 이전 클래스의 catastophic forgetting을 방지하기 위해 특별한 기법을 사용함.
문제점:
이러한 방법은 학습 비용을 줄이지만, 새로운 클래스에 대한 pixel-wise supervision은 비싸며 시간이 많이 걸리며 expert human annotator가 필요.
해결책:
annotation cost을 줄이기 위해서 weak supervision이 연구되어옴.
< bounding boxes, scribbles, points and image-level labels>
Image level labels들은 이미지 분류 벤치마크나 웹에서 쉽게 검색할 수 있으므로 annotation 비용을 크게 낮출 수 있음.
문제점:
하지만, 그들은 incremental learning setting에서 연구되어 온 적은 없음.
Weakly Incremental Learning for Semantic Segmentation 제안
incremental learning (training only on new class data) and weak supervision (cheap and largely available annotations)
기존의 weakly supervised semantic segmentation + incremental learning
(1) pixel-wise pseudo supervision 추출
(2) update segmentation network
기존의 약한 지도학습 방법을 직접적으로 적용하면 점진적 세그멘테이션에서 오프라인으로 픽셀 단위의 의사 주석을 추출하고, 증분 학습 기술을 활용하여 세그멘테이션 네트워크를 업데이트해야 합니다. 그러나 점진적인 설정에서 오프라인으로 의사 라벨을 생성하는 것은 최적화되지 않는다고 주장합니다. 왜냐하면 이는 두 개의 별개 학습 단계를 포함하며, 이전 클래스에 대한 모델의 지식을 활용하여 새로운 클래스를 더 효율적으로 학습할 수 있는 기회를 놓치기 때문입니다.
Contribution
-
Weakly Incremental Learning framework for Semantic Segmentation (WILSON) 를 제안
-
Standard encoder-decoder segmentation architecture 확장하여 encoder에 localizer 를 도입하여 segmentation backbone을 위한 pseudo-supervision 추출.
-
Pseudo-supervision을 개선하기 위해 localizer을 이전 클래스 knowledge에 기반한 pixel-wise loss로 교육
- 이전 class knowledge에 대한 강력한 prior knowledge로 작용하여 모델이 이전 클래스가 이미지에서 어디에 위치해있는지 알 수 있음
- 더 나은 object boundary를 추출하기 위한 saliency prior 제공
-
pseudo supervision에서의 noise를 다루기 위해서 이전 작업에서처럼 hard pseudo labels 대신 localizer에서 확률 정보를 제공하는 soft label을 사용.
-
Pascal VOC 및 COCO 데이터 세트에서 평가를 수행하여, WILSON 방법이 offline weakly supervised 방식보다 뛰어나며, fully supervised 방법과 비교하여 성능이 유사하거나 약간 낮은 것을 보여줍니다.
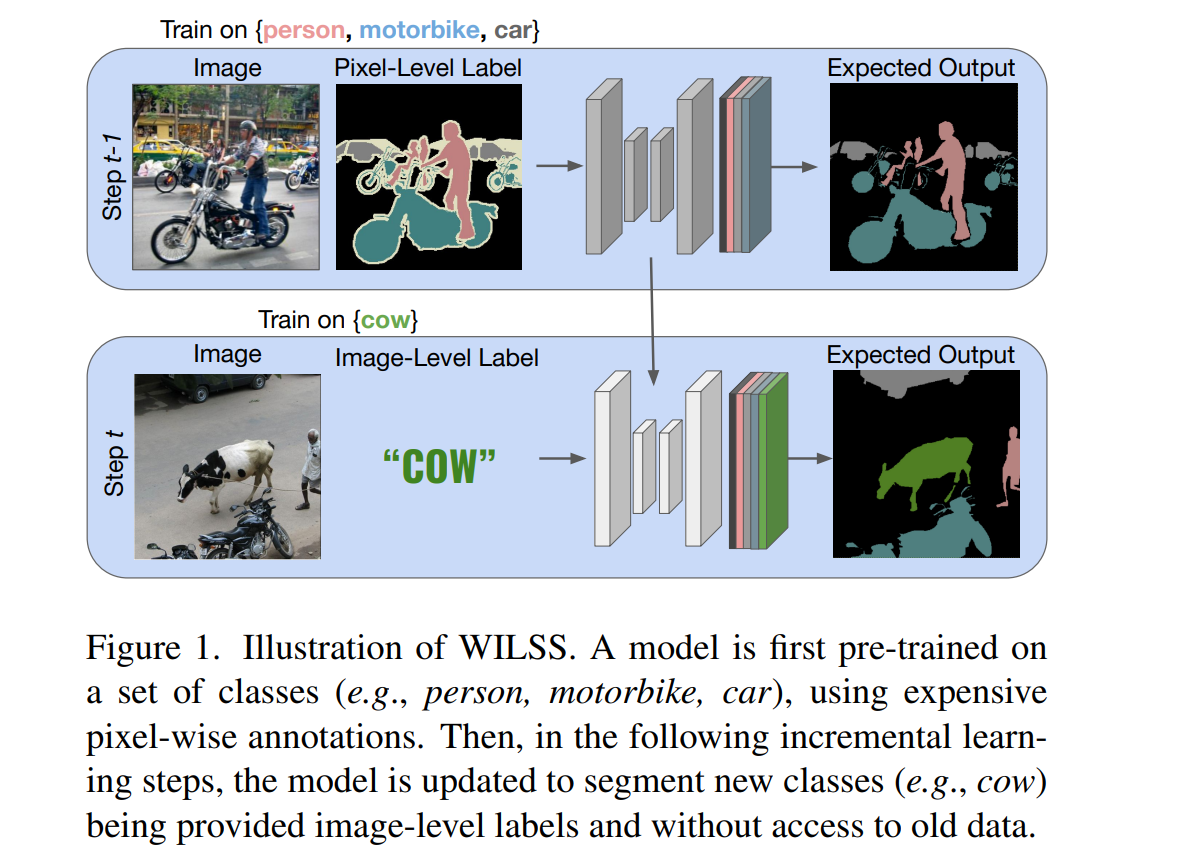
사진에서 보여지듯이, 처음에는 pixel-wise annotations을 사용해서 pretrained을 시킨 다음 두번째부터는 incremental learning step을 밟는다. 이때 새로운 데이터들은 image-level labels로 학습이 됨.
Method
1. Training the Localizer
, segmentation에 pseudo-supervision을 주기위해서 image-level labels로 학습이 되어짐.
Segmentation encoder 로 부터 얻어진 모든 class에 대한 scores가 있는 features들을 localizer가 사용하게 됨. .
Image level labels를 학습하려면 먼저 pixel level classification score 을 aggregate 해야 함. Global Average Pooling(GAP) 를 사용할 수 있지만, 이건 coarse pseudo labels을 만들게 됨.
→ normalized Global Weighted Pooling (nGWP)
1.1. nGWP
target class에 대한 relevance을 기준으로 모든 픽셀의 가중치를 부여
특히, 각 픽셀의 가중치는 softmax 연산으로 classification score를 정규화하여 계산함
점수가 물체의 모든 visible parts를 식별하도록 하기 위해서, 우리는 focal penalty term 사용
nGWP와 focal penalty terms 에 대한 설명
1.2. multi-label soft-margin loss
, , = logistic function
loss는 새로운 클래스에만 계산되지만 function의 softmax 기반 aggregation으로 인해 이전 클래스 점수에 암묵적으로 의존한다는 점.
1.3. Localization Prior
image-level label은 이미지에 새 class가 있는 경우에만 supervision 제공 → boundary에 대해서나 old class의 위치에 대한 정보는 제공하지 않음. (이건 이전 segmentation model에서도 충분히 얻을 수 있음. 또한 background score도 더 나은 object boundary를 추출하기 위해 중요하게 사용.)
→ old classes의 점수는 이미지에 old class가 있는지 여부와 위치를 detect하여 localizer의 attention을 대체 영역으로 유도.
t-1 단계에서 훈련된 segmentation model에서 오는 localizer에 대한 직접적인 supervision → supervision은 Localization Prior로 작용, pixel-wise loss (output(), classification scores )
Objective function
위의 Eq.을 보면, segmentation model이 old classes에 대한 dense한 target을 제공함. softmax 연산자가 클래스 간의 경쟁을 enforce 하는 것과 달리, logistic function은 클래스 확률을 독립적으로 만들어 이전의 correct localizer prior에 유리함. New class의 경우, old class와 background 모두 낮은 점수를 가질 것. 픽셀이 새 클래스에 속함을 implicitly하게 localizer에 알림.
Learning to Segment from Pseudo-Supervision
Hard psdueo lables (from an image level classifier): one-hot distribution for each pixel
이건 가장 높은 점수를 가진 class에만 1, 나머지는 0임. → 하지만, 보통은 image-level classifier는 noisy하고 정확하지 않은 target을 맞춰질때가 있음.
따라서, 본 논문에서는 pseudo-labels에 smooth 작업을 해준다.
(는 smoothness를 control하는 hyperparameter)
localizer가 new class와 old class에 대해 score을 생성하지만, incremental learning으로 인해 output distribution이 new class로 편향될 수 있음.
따라서 segmentation model의 target으로 를 사용하면 catastophic forgetting이 발생할 수 있음.
본 논문에서는 이전 클래스의 localizer에서 추출한 pseudo-supervision을 이전 학습단계에서 훈련된 segmentation model의 output으로 대체. (knowledge distillation framework)
FINAL PIXEL-LEVEL PSEUDO SUPERVISION
- b는 배경 class, 는 logistic function
Multi-label soft-margin loss
- : set of all seen classes
- : segmentation model output
※ test 단계에서는 localizer가 사용되지 않음.
Dataset
PASCAL VOC dataset
15-5 VOC dataset : 처음 학습단계에서 15개의 클래스를 학습하고 두번째 단계에서 5개의 새로운 클래스를 추가
10-10 VOC dataset : 처음 클래스를 10개의 클래스, 두번째는 10개의 새로운 클래스 추가.
- disjoint scenario
각 훈련 단계에는 이전에 학습한 클래스 또는 학습할 새 클래스의 객체를 포함하는 이미지만 포함. 학습 프로세스 중에 모델은 학습의 두 번째 단계가 시작될 때까지 새 클래스의 개체가 포함된 이미지에 액세스할 수 없음.
이 설정은 이전에 배운 것을 잊지 않고 새 클래스를 배우는 모델의 능력을 평가함.
- overlap scenario
각 훈련 단계에는 이전에 학습한 클래스에 속하는지 새로운 클래스에 속하는지에 관계없이 새로운 클래스의 픽셀이 하나 이상 포함된 모든 이미지가 포함. 이 시나리오에서 모델은 교육 중에 이전에 본 클래스와 새 클래스 모두에 액세스할 수 있음. 이 설정은 이전 지식을 유지하면서 새로운 클래스를 점진적으로 학습하는 모델의 능력을 평가함.
COCO dataset
COCO-to-VOC : 첫번째 단게에서는 Pascal VOC 데이터셋에 없는 60개의 COCO 클래스를 학습하고 이전 데이터셋에 있는 이미지에서 적어도 하나의 픽셀을 포함하고 있는 이미지를 제거함. 그 다음 두번째 단계에서는 Pascal VOC 데이터셋의 20개의 클래스를 학습.
Implementation Details
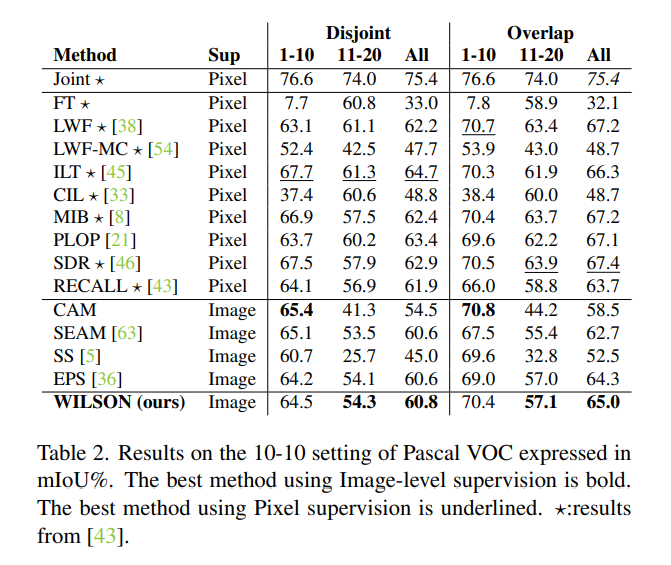
WILSON이 새로운 설정이므로, 이전에 연구된 incremetal learning과 Weakly supervised semantic segmentation 모델들과 비교를 진행.
Results


Localization Prior.
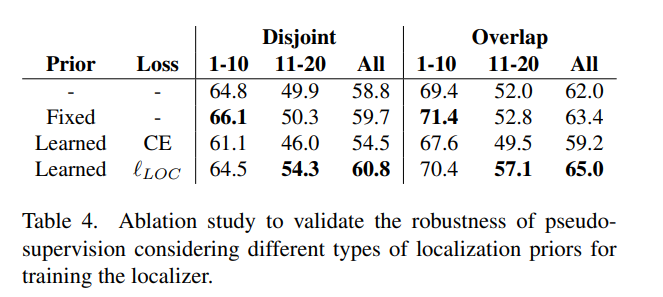
VOC10-10 segmentation dataset 사용.
이전 클래스에 대해 constant value을 사용하거나 이전 모델의 segmentation output을 직접 붙여서 계산하는 고정된 사전(prior)을 사용하는 것보다, 이전 클래스의 위치를 localizer에게 가르치는 것이 새로운 클래스를 학습하면서 forgetting을 방지하고 성능을 향상시키는 효과가 있음.
이전 모델의 segmentation output을 직접 사용하는 aggressive prior을 사용하는 것은 새로운 클래스를 효과적으로 학습하지 못하게 하므로, 와 비교하여 격차가 발생. segmentation output을 일치시키기 위해 softmax cross entropy loss을 사용하는 것은 성능에 부정적인 영향을 끼침. → softmax normalization, cross-entropy loss가 각 클래스를 독립적으로 고려하지않아서 이전 클래스의 점수를 강제로 높이기 때문.
Smoothing effect on psuedo-supervision

Eq.4 에서 하이퍼파라미터 를 조정.
다섯 가지 서로 다른 α 값 (0에서 1까지 범위)에 대한 최종 mIoU
-
α = 1 - hard pseudo label,
모델은 noise 때문에 이전 지식을 forget하고 새로운 클래스를 배울 수 없게 됨. -
α = 0.5를 선택
값이 0에서 0.7까지 변할 때 분리 및 겹치는 경우 평균적으로 결과에 미치는 영향은 0.5% 미만으로 WILSON은 다양한 α 값에 대해 strong.
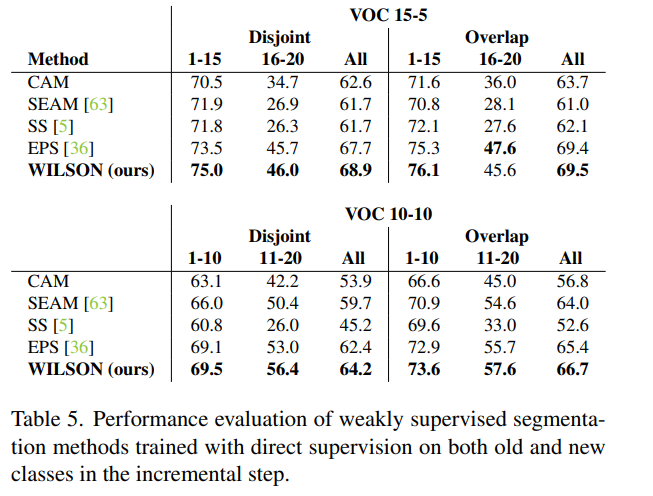
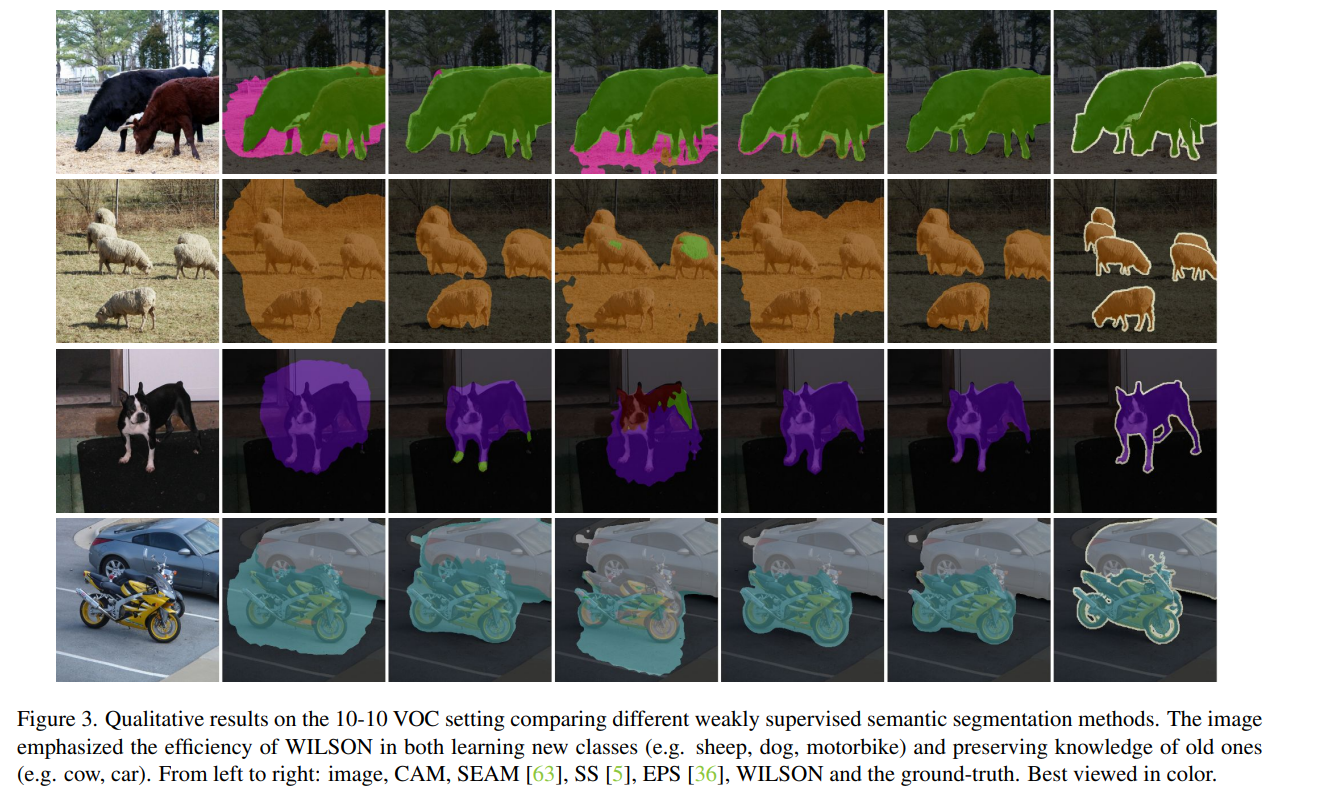
Using supervision for all the classes.
Limitation
- Eq. 3이 학습을 적절하게 안내하기 위해 부정적인 예가 필요하기 때문에 WILSON은 단일 클래스 점진적 학습 단계를 수행할 수 없음.
- 여전히 모델을 학습하기 위해 상당한 양의 이미지가 필요.
NEXT works
- CLIP을 사용해서 WILSON이 아닌 zero-shot으로도 가능하게 만듦.
CVPR'23
