✏️ 한줄요약 ✏️
- Gated Axial Attention을 사용하여 medical image segmentation에 알맞은 medical transformer 모델 제안
Motivation
Medical Image Segmentation은 automatic, accurate, robust한 segmentation results을 내는 것이 주요 과제이다.
1. ConvNets
: Deep Convolutional Neural Network가 computer vision에서 많은 ~
: U-Net, V-Net, 3D U-Net 등등 have been proposed for performing image and volumetric segmentation for various medical imaging modalities.
long-range dependencies의 문제점 발생
ConvNets에서 각 convolutional kernel은 전체 이미지에서 지역적인 일부 픽셀에만 관심을 가지며, 네트워크가 global한 context이 아닌 local한 pattern에 집중하도록 강제합니다.
2. long range dependencies을 해결한 ConvNets
long-range dependencies을 해결하기 위한 convolutional neural network(ConvNets) -> image pyramid, atrous convolutions, and attention mechanism.
하지만, 여전히 medical image segmentataion분야에서는 이전 방법들이 이러한 면에 초점을 맞추지 않았기 때문에 개선의 여지가 있음.
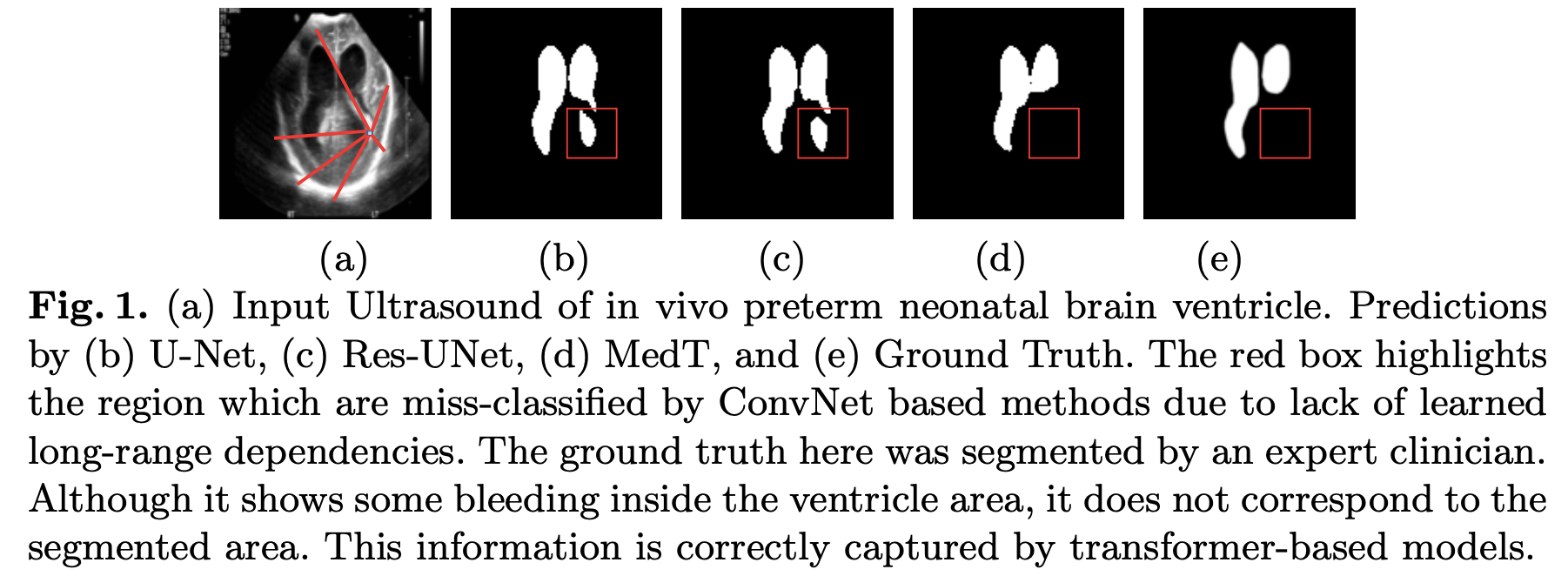
ex. 의료 이미지에서 long-range dependency가 왜 중요한지 이해하기 위한 예시
- 빨간색 상자는 ConvNet기반 방법이 학습된 long-range dependency의 부족으로 miss-classify된 영역을 강조
- 효과적인 분할을 제공하려면 네트워크가 mask에 해당하는 픽셀과 background에 해당하는 픽셀을 이해할 수 있어야 함.
이미지의 배경이 흩어져 있기 때문에 배경에 해당하는 픽셀 간에 long-range dependency을 학습하는 것은 mask로 잘못 분류되어 false positive을 줄이는데 도움이 될 수 있음- (b), (c)에서 보이듯이 convolution network은 배경을 잘못분류하는 반면, 제안된 transformer 기반 방법은 올바르게 판단함.
3. Transformer in medical imaging
NLP application 내에서는 transformer가 self-attention mechanism이 sequential input의 dependency를 잘 찾아주는 덕분에 long-range dependency를 인코딩하는 능력이 뛰어나다.
Axial Deeplab: axial attention module이 포함되어있는 모델로, 2D self-attention를 두개의 1D self-attention을 준다. 이 self-attention은 position-sensitive axial attention으로 구성되어있다.
SETR: transformer가 encoder로써 사용이 되며, ConvNet가 decoder로 이용이 되어 powerful한 segmentation model이 만들어진다.
large-scale dataset에서는 좋지만, medical imaging과 같이 많은 데이터를 가질 수 없는 task에 대해서는 좋지않은 성능을 보임.
Contribution
- A gated position-sensitive axial attention mechanism
- Local-Global (LoGo) training methodology for transformers
- Medical-Transformer (MedT)
- 3가지의 각각 다른 medical dataset을 사용하여 성능향상을 보여줌.
Preview
- Gated position-sensitive axial attention mechanism
- small dataset에 유용
- positional embedding이 key, query, 그리고 key에 제공하는 정보의 양을 제어하는 4개의 gate를 소개함.
- gate는 학습 가능한 매개변수이며, 제안된 메커니즘이 어떤 크기의 데이터셋에서도 적용될 수 있도록 만듦.
- 데이터셋의 크기에 따라 이 게이트는 이미지의 수가 충분한지 여부를 학습하여 적절한 positional embedding을 학습할 수 있음.
- positional embedding이 학습한 정보가 유용한지 여부에 따라 게이트 매개변수는 0에 수렴하거나 더 높은 값을 가질 수 있도록 조정이 됨.
- Local-Global training (LoGo)
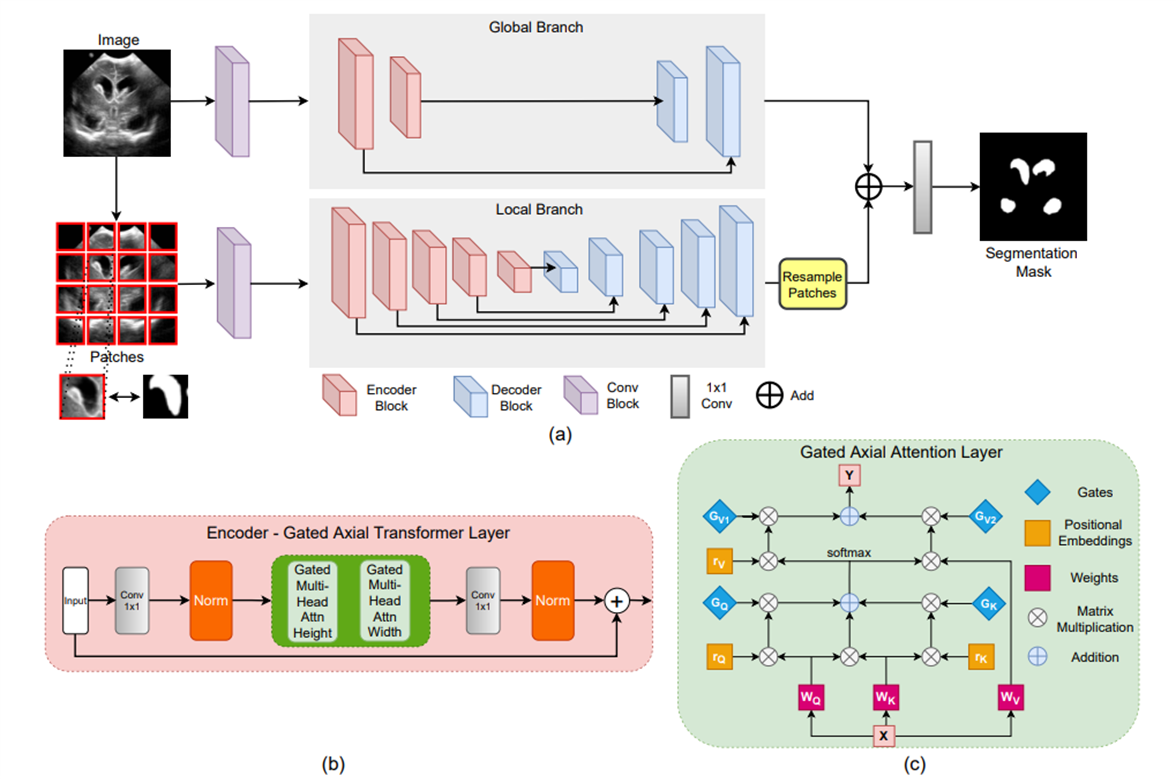
Global Branch와 Local Branch을 나눠서 학습 - Medical Transformer (MedT)
gated position-sensit텍스트ive axial attention 을 block 쌓을 때 사용하고 LoGo를 training strategy에 사용.
1. Gated Axial Attention
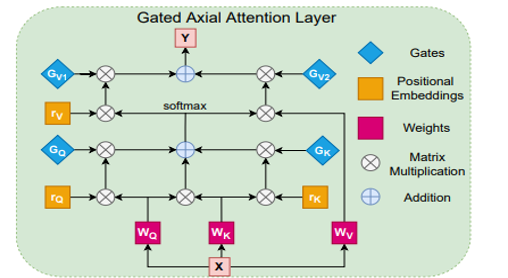
1.1. Axial Deeplab
Gated Axial Attention Mechanism에서 나온 axial attention은 axial Deeplab axialDeeplab 에서 먼저 나온 개념이다.
Axial Attention이 나오게된 배경에 대한 설명을 우선 하도록 하겠다.
1. Self-Attention Mechanism
기존의 self-attention mechanism .
(+) 전체 feature map에서 관련 있는 context을 볼 수 있다는 장점
(-) 모든 나머지 patch 들은 하나의 패치에 대해 attention을 계산해야 하기 때문에 계산 비용이 매우 비쌈.
(-) positional embedding이 불충분. Self-attention 레이어는 convolution 레이어와 달리 non-local context를 계산할 때 위치 정보를 사용하지 않음.
2. Stand-Alone Self Attention
(+) 모든 feature map pixel를 key로 사용하는 것이 아닌 query 주변의 MxM개만을 key로 사용. Computational Complexity 줄어듦.
(+) query에 relative positional encoding 추가.
→ 각 pixel(query)들은 주변 MxM 공간을 receptive field로써 확장된 정보를 가지며, 이 덕분에 softmax 이후에도 dynamic 한 prior를 생산할 수 있음.
3. Position-Sensitivity self attention
(-) 기존 method는 query에 대한 positional embedding만 추가
(+) query에 대한 relative positional embedding 뿐만 아니라 key, value에 대해서 relative positional embedding를 추가. → 한 query에 대해서 주변의 patch의 attention만 계산을 하기 때문에 key와 value의 positional embedding도 필수로 필요.
→ 추가된 positional embedding은 across heads 사이에 parameter를 share하기 때문에 큰 cost 증가는 없음.
→ long-range interaction과 positional information을 가지며 computation 에 대해서 정당성을 가지는 position-sensitive self-attention 만듦
4. Axial Attention
※ 위 수식은 weight axis에 대해서만 나타낸 수식임.
(-) Stand-alone mechanism은 MxM만을 고려하므로, receptive field가 local constraint로써 단점으로 작용 가능.
(+) global connection(=capture global information) 사용
(+) 각 query에 HW를 모두 key로 사용하는 것 보다는, efficient computation 을 획득함. width-axis, height-axis 방향으로 2번 적용.
1.2. Proposed Gated Axial-Attention
Axial Attention
- non-local context를 비교적 높은 계산 효율성으로 계산 가능
- input feature map내에서 long-range interaction을 인코딩할 수 있는 positional bias를 mechanism에 인코딩 가능
- large scale segmentation dataset은 axial attention으로 key, query, value의 positional bias를 학습하는 것은 쉬움.
Medical segmentation에서는 small scale dataset이 문제.
Small scale dataset은 positional bias에 대해서 학습하기 어렵기 때문에 long-range interaction을 인코딩하는데 항상 정확하지 않을 수 있음.
따라서, relative positional bias이 인코딩하는 non-local context에 미치는 영향을 제어할 수 있는 modified axial attention block 제안.
수정된 axial attention block에서 너비축에 적용되는 self-attention mechansim.
Gated Axial Attention
- learnable parameters
- positional bias의 영향을 제어하는 gating mechanism을 생성 (non local context을 가지는)
- 만약, relative positional encoding이 정확하게 학습이 되었을 경우, Gating Mechanism은 정확하게 학습된 positional encoding에 높은 가중치를 할당.
2. Local-Global Training (LoGo Training)
패치 단위 학습만으로는 충분하지 않고, 패치 단위 학습은 패치 간 픽셀 간의 정보나 의존성을 학습하는데에 제한이 있음.
2.1. Global branch
이미지의 원래 해상도에서 작동
📌 제안된 transformer 모델의 처음 몇 블록이 long-range dependency을 모델링하는데 충분하다는 것을 관찰하여 gated axial tranformer layer의 수를 줄임.
2.2. Local branch
이미지의 패치에서 작동
📌 16 patches들이 network을 feed forward한 후 feature map은 위치에 따라 다시 resampling되어서 output feature map을 얻게 됨.
두 feature map은 더해지고 1x1 convolution layer를 통과하여 output segmentation mask를 생성
- binary cross entropy loss을 사용해서 network을 training 시킴
Implementation Details
dataset
Brain anatomy segmentation(ultrasound)Gland Segmentation(microscopic)MoNuSeg(microscopic)
※brain anatomy segmentation: large scale dataset
※GLaS&MoNuSeg: small scale dataset
Training Details
- batch size : 4
- Adam Optimizer
- Learning Rate : 0.001
- 400 epochs
- gated axial attention layer을 학습할 때에는 첫 10epochs는 학습을 하지 않음 - Nvidia Quadro 8000 GPU
Results
F1 scores와 IoU을 평가를 위해 사용함.
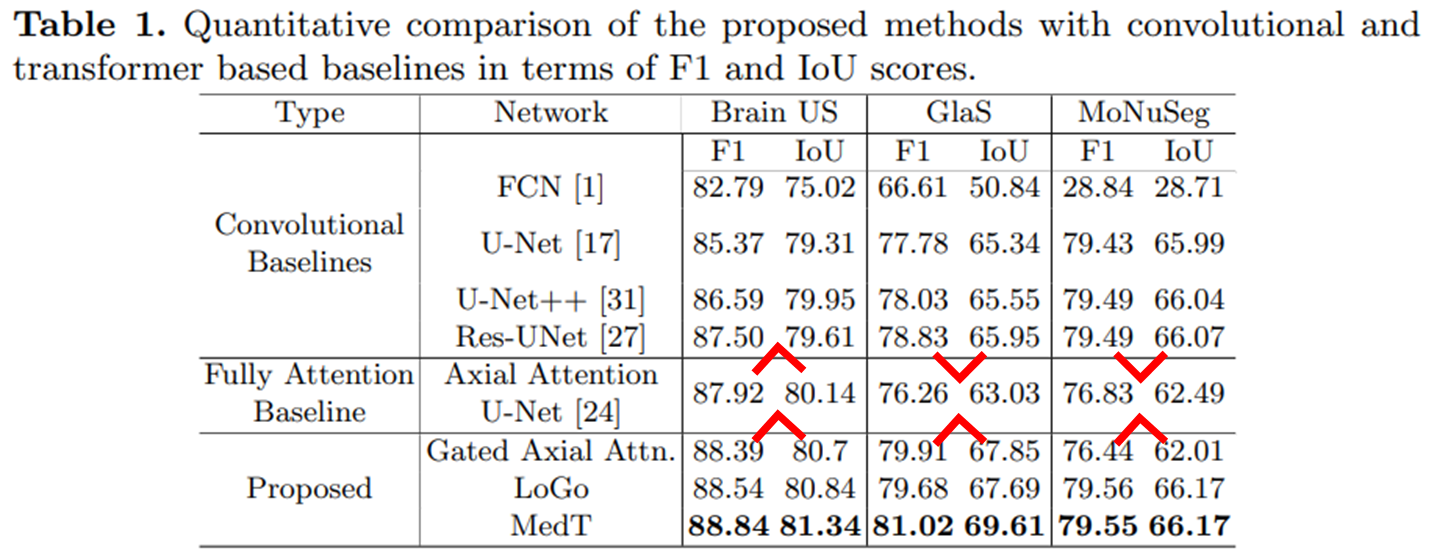
BrainUS와 같이 많은 이미지를 가진 데이터셋에서는 전체적으로 fully attention based 모델이 convolutional baselines보다 성능이 우수함을 알 수 있음.
GlaS와 MoNuSeg 데이터셋과 같이 적은 양의 데이터로는 fully attention based 모델을 훈련시키기 어려운 경우에는 convolutional baselines 모델이 더 나은 성능을 발휘.
MedT가 다른 어느 방법론보다 더 높은 성능을 보임을 알 수 있다.
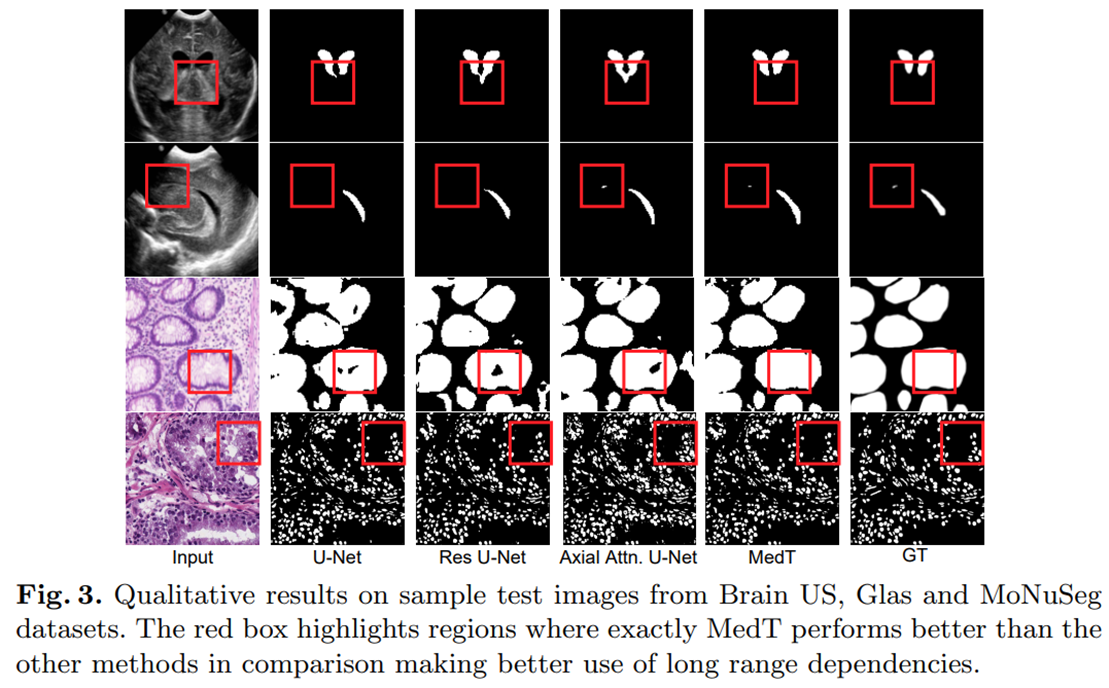
- MedT의 예측이 long-range dependency을 매우 잘 포착함을 알 수 있음.
- 2행에서는 빨간색 상자에 강조된 작은 segmentation mask가 모든 convolutional based model에서 감지되지 않은 것을 관찰 할 수 있음.
- fully attention based 모델은 long range dependency을 인코딩하기 때문에 global context을 잘 인코딩하여 잘 segment 하도록 학습함.
- 1&4행에서는 다른 방법들이 강조된 영역에서 miss-classify을 하는 반면, MedT는 gating mechanism으로 인코딩된 pixel 별 종속성을 고려하기 때문에 axial attention U-net 보다 이러한 dependency을 더 잘 학습할 수 있음.

멋져요