cs224n
1.Stanford CS224N NLP with Deep Learning | Winter 2021 | Lecture 7 - Translation, Seq2Seq, Attention
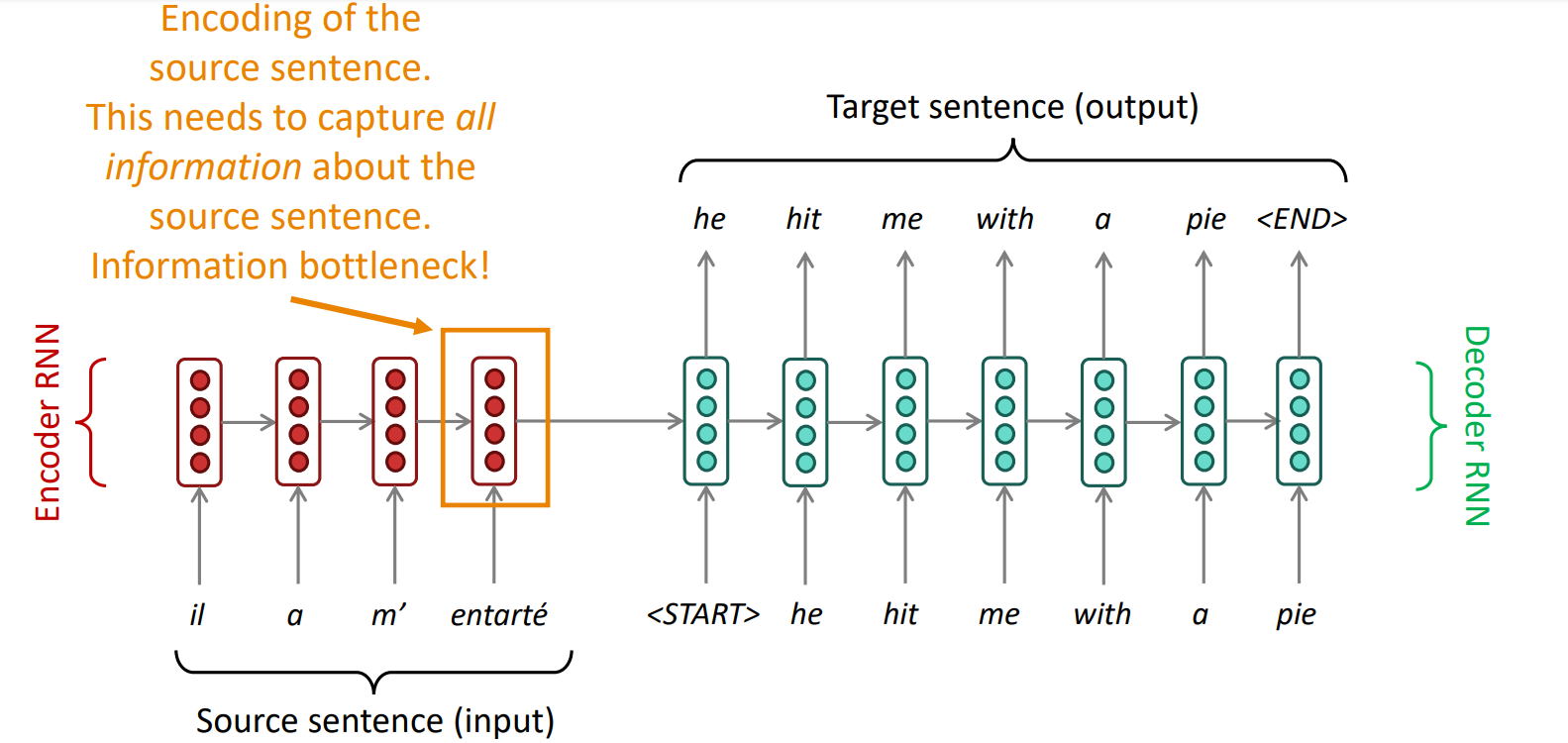
encoder RNN의 마지막 hidden state에 모든 정보가 쏠림Sentiment Analysis task에서는 문장 전체를 보지 않아도 좋은 performance를 낼 수 있었지만 NMT task에서는 아님사람이 번역을 할 때도 source sentence를
2023년 10월 4일
2.Stanford CS224N NLP with Deep Learning | Winter 2021 | Lecture 9 - Self- Attention and Transformers
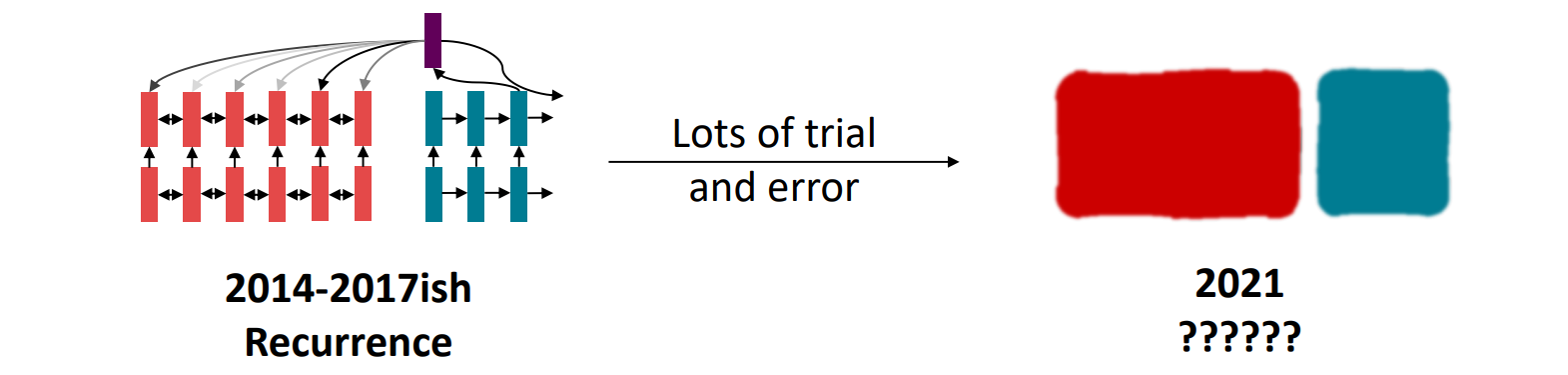
bidirectional LSTM으로 문장 encodingLSTM decoderattention을 이용해 메모리에 유연하게 접근2021년, 모델에서 최적의 building block은 무엇일까gradient vanishing으로 long-distance dependen
2023년 10월 4일